 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanOrbit: 3D Human Reconstruction as 360° Orbit Generation
Feb 27, 2026We present a method for generating a full 360° orbit video around a person from a single input image. Existing methods typically adapt image-based diffusion models for multi-view synthesis, but yield inconsistent results across views and with the original identity. In contrast, recent video diffusion models have demonstrated their ability in generating photorealistic results that align well with the given prompts. Inspired by these results, we propose HumanOrbit, a video diffusion model for multi-view human image generation. Our approach enables the model to synthesize continuous camera rotations around the subject, producing geometrically consistent novel views while preserving the appearance and identity of the person. Using the generated multi-view frames, we further propose a reconstruction pipeline that recovers a textured mesh of the subject. Experimental results validate the effectiveness of HumanOrbit for multi-view image generation and that the reconstructed 3D models exhibit superior completeness and fidelity compared to those from state-of-the-art baselines.
Open-Vocabulary Semantic Part Segmentation of 3D Human
Feb 27, 20253D part segmentation is still an open problem in the field of 3D vision and AR/VR. Due to limited 3D labeled data, traditional supervised segmentation methods fall short in generalizing to unseen shapes and categories. Recently, the advancement in vision-language models' zero-shot abilities has brought a surge in open-world 3D segmentation methods. While these methods show promising results for 3D scenes or objects, they do not generalize well to 3D humans. In this paper, we present the first open-vocabulary segmentation method capable of handling 3D human. Our framework can segment the human category into desired fine-grained parts based on the textual prompt. We design a simple segmentation pipeline, leveraging SAM to generate multi-view proposals in 2D and proposing a novel HumanCLIP model to create unified embeddings for visual and textual inputs. Compared with existing pre-trained CLIP models, the HumanCLIP model yields more accurate embeddings for human-centric contents. We also design a simple-yet-effective MaskFusion module, which classifies and fuses multi-view features into 3D semantic masks without complex voting and grouping mechanisms. The design of decoupling mask proposals and text input also significantly boosts the efficiency of per-prompt inference. Experimental results on various 3D human datasets show that our method outperforms current state-of-the-art open-vocabulary 3D segmentation methods by a large margin. In addition, we show that our method can be directly applied to various 3D representations including meshes, point clouds, and 3D Gaussian Splatting.
Video to Fully Automatic 3D Hair Model
Sep 13, 2018
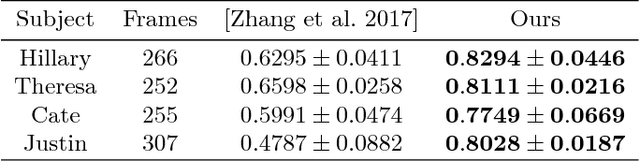
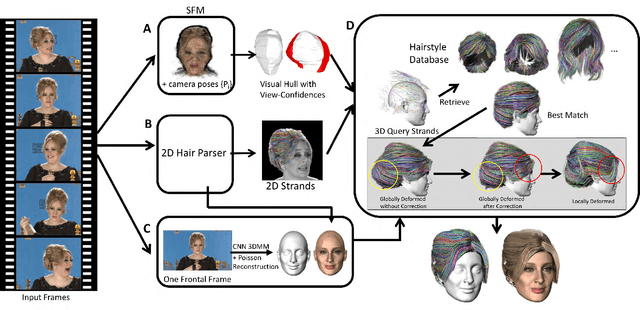
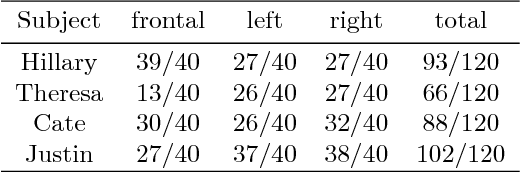
Imagine taking a selfie video with your mobile phone and getting as output a 3D model of your head (face and 3D hair strands) that can be later used in VR, AR, and any other domain. State of the art hair reconstruction methods allow either a single photo (thus compromising 3D quality) or multiple views, but they require manual user interaction (manual hair segmentation and capture of fixed camera views that span full 360 degree). In this paper, we describe a system that can completely automatically create a reconstruction from any video (even a selfie video), and we don't require specific views, since taking your -90 degree, 90 degree, and full back views is not feasible in a selfie capture. In the core of our system, in addition to the automatization components, hair strands are estimated and deformed in 3D (rather than 2D as in state of the art) thus enabling superior results. We provide qualitative, quantitative, and Mechanical Turk human studies that support the proposed system, and show results on a diverse variety of videos (8 different celebrity videos, 9 selfie mobile videos, spanning age, gender, hair length, type, and styling).