 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecAware: A Spectral-Content Aware Foundation Model for Unifying Multi-Sensor Learning in Hyperspectral Remote Sensing Mapping
Oct 31, 2025



Hyperspectral imaging (HSI) is a vital tool for fine-grained land-use and land-cover (LULC) mapping. However, the inherent heterogeneity of HSI data has long posed a major barrier to developing generalized models via joint training. Although HSI foundation models have shown promise for different downstream tasks, the existing approaches typically overlook the critical guiding role of sensor meta-attributes, and struggle with multi-sensor training, limiting their transferability. To address these challenges, we propose SpecAware, which is a novel hyperspectral spectral-content aware foundation model for unifying multi-sensor learning for HSI mapping. We also constructed the Hyper-400K dataset to facilitate this research, which is a new large-scale, high-quality benchmark dataset with over 400k image patches from diverse airborne AVIRIS sensors. The core of SpecAware is a two-step hypernetwork-driven encoding process for HSI data. Firstly, we designed a meta-content aware module to generate a unique conditional input for each HSI patch, tailored to each spectral band of every sample by fusing the sensor meta-attributes and its own image content. Secondly, we designed the HyperEmbedding module, where a sample-conditioned hypernetwork dynamically generates a pair of matrix factors for channel-wise encoding, consisting of adaptive spatial pattern extraction and latent semantic feature re-projection. Thus, SpecAware gains the ability to perceive and interpret spatial-spectral features across diverse scenes and sensors. This, in turn, allows SpecAware to adaptively process a variable number of spectral channels, establishing a unified framework for joint pre-training. Extensive experiments on six datasets demonstrate that SpecAware can learn superior feature representations, excelling in land-cover semantic segmentation classification, change detection, and scene classification.
Divide-and-Shuffle Synchronization for Distributed Machine Learning
Jul 07, 2020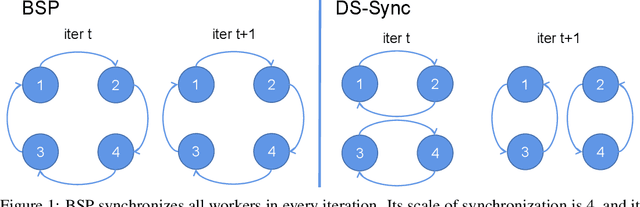
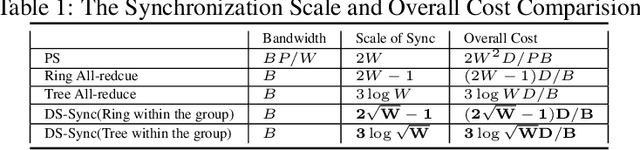

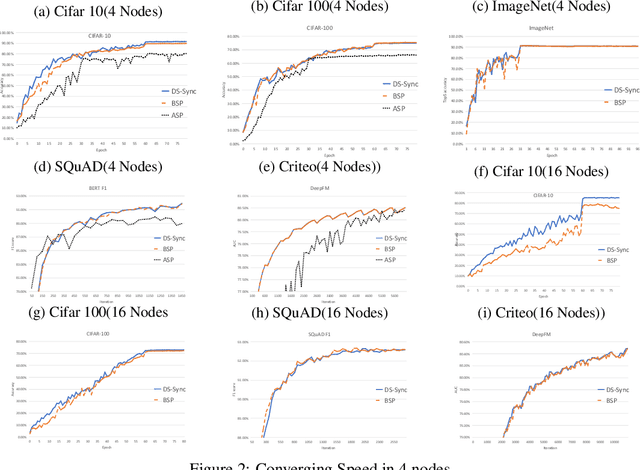
Distributed Machine Learning suffers from the bottleneck of synchronization to all-reduce workers' updates. Previous works mainly consider better network topology, gradient compression, or stale updates to speed up communication and relieve the bottleneck. However, all these works ignore the importance of reducing the scale of synchronized elements and inevitable serial executed operators. To address the problem, our work proposes the Divide-and-Shuffle Synchronization(DS-Sync), which divides workers into several parallel groups and shuffles group members. DS-Sync only synchronizes the workers in the same group so that the scale of a group is much smaller. The shuffle of workers maintains the algorithm's convergence speed, which is interpreted in theory. Comprehensive experiments also show the significant improvements in the latest and popular models like Bert, WideResnet, and DeepFM on challenging datasets.