 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeta-VAE has 2 Behaviors: PCA or ICA?
Mar 25, 2023Beta-VAE is a very classical model for disentangled representation learning, the use of an expanding bottleneck that allow information into the decoder gradually is key to representation disentanglement as well as high-quality reconstruction. During recent experiments on such fascinating structure, we discovered that the total amount of latent variables can affect the representation learnt by the network: with very few latent variables, the network tend to learn the most important or principal variables, acting like a PCA; with very large numbers of latent variables, the variables tend to be more disentangled, and act like an ICA. Our assumption is that the competition between latent variables while trying to gain the most information bandwidth can lead to this phenomenon.
Full Encoder: Make Autoencoders Learn Like PCA
Mar 25, 2021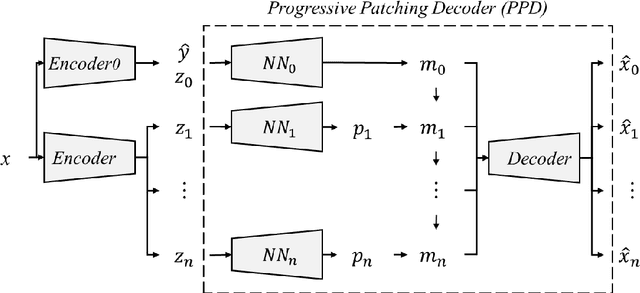

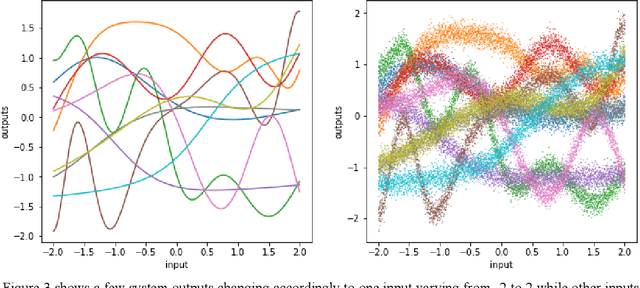
While the beta-VAE family is aiming to find disentangled representations and acquire human-interpretable generative factors, like what an ICA does in the linear domain, we propose Full Encoder: a novel unified autoencoder framework as a correspondence to PCA in the non-linear domain. The idea is to train an autoencoder with one latent variable first, then involve more latent variables progressively to refine the reconstruction results. The latent variables acquired with Full Encoder is stable and robust, as they always learn the same representation regardless the network initial states. Full Encoder can be used to determine the degrees of freedom in a non-linear system, and is useful for data compression or anomaly detection. Full Encoder can also be combined with beta-VAE framework to sort out the importance of the generative factors, providing more insights for non-linear system analysis. We created a toy dataset with a non-linear system to test the Full Encoder and compare its results to VAE and beta-VAE's results.