 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness-Aware Ranking in Search & Recommendation Systems with Application to LinkedIn Talent Search
May 21, 2019


We present a framework for quantifying and mitigating algorithmic bias in mechanisms designed for ranking individuals, typically used as part of web-scale search and recommendation systems. We first propose complementary measures to quantify bias with respect to protected attributes such as gender and age. We then present algorithms for computing fairness-aware re-ranking of results. For a given search or recommendation task, our algorithms seek to achieve a desired distribution of top ranked results with respect to one or more protected attributes. We show that such a framework can be tailored to achieve fairness criteria such as equality of opportunity and demographic parity depending on the choice of the desired distribution. We evaluate the proposed algorithms via extensive simulations over different parameter choices, and study the effect of fairness-aware ranking on both bias and utility measures. We finally present the online A/B testing results from applying our framework towards representative ranking in LinkedIn Talent Search, and discuss the lessons learned in practice. Our approach resulted in tremendous improvement in the fairness metrics (nearly three fold increase in the number of search queries with representative results) without affecting the business metrics, which paved the way for deployment to 100% of LinkedIn Recruiter users worldwide. Ours is the first large-scale deployed framework for ensuring fairness in the hiring domain, with the potential positive impact for more than 630M LinkedIn members.
What's in a Name? Reducing Bias in Bios without Access to Protected Attributes
Apr 10, 2019
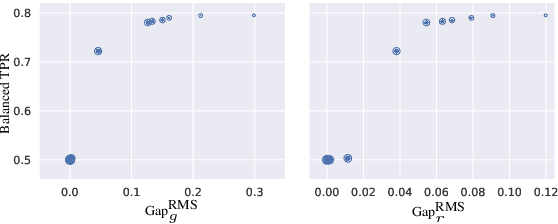
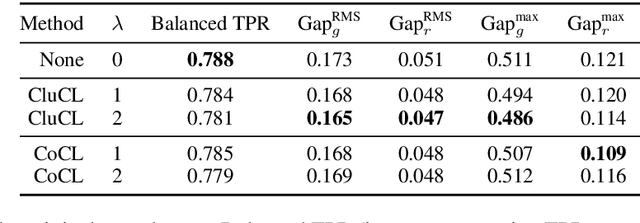
There is a growing body of work that proposes methods for mitigating bias in machine learning systems. These methods typically rely on access to protected attributes such as race, gender, or age. However, this raises two significant challenges: (1) protected attributes may not be available or it may not be legal to use them, and (2) it is often desirable to simultaneously consider multiple protected attributes, as well as their intersections. In the context of mitigating bias in occupation classification, we propose a method for discouraging correlation between the predicted probability of an individual's true occupation and a word embedding of their name. This method leverages the societal biases that are encoded in word embeddings, eliminating the need for access to protected attributes. Crucially, it only requires access to individuals' names at training time and not at deployment time. We evaluate two variations of our proposed method using a large-scale dataset of online biographies. We find that both variations simultaneously reduce race and gender biases, with almost no reduction in the classifier's overall true positive rate.
Bias in Bios: A Case Study of Semantic Representation Bias in a High-Stakes Setting
Jan 27, 2019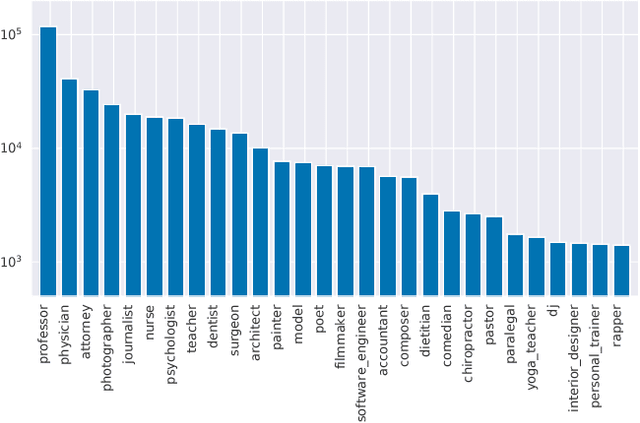
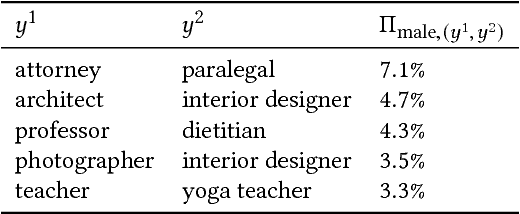
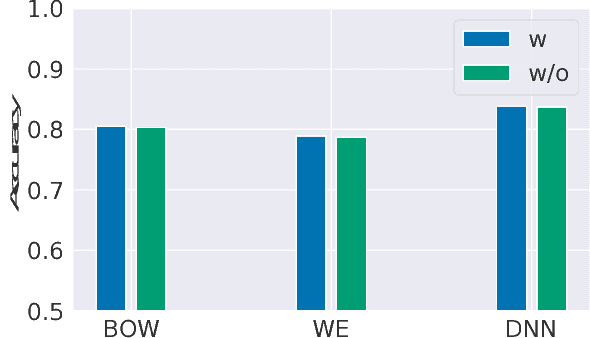

We present a large-scale study of gender bias in occupation classification, a task where the use of machine learning may lead to negative outcomes on peoples' lives. We analyze the potential allocation harms that can result from semantic representation bias. To do so, we study the impact on occupation classification of including explicit gender indicators---such as first names and pronouns---in different semantic representations of online biographies. Additionally, we quantify the bias that remains when these indicators are "scrubbed," and describe proxy behavior that occurs in the absence of explicit gender indicators. As we demonstrate, differences in true positive rates between genders are correlated with existing gender imbalances in occupations, which may compound these imbalances.
Talent Search and Recommendation Systems at LinkedIn: Practical Challenges and Lessons Learned
Sep 18, 2018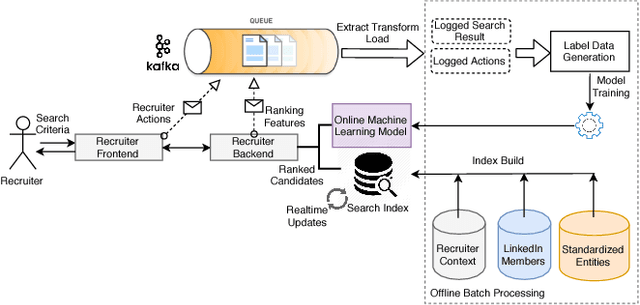
LinkedIn Talent Solutions business contributes to around 65% of LinkedIn's annual revenue, and provides tools for job providers to reach out to potential candidates and for job seekers to find suitable career opportunities. LinkedIn's job ecosystem has been designed as a platform to connect job providers and job seekers, and to serve as a marketplace for efficient matching between potential candidates and job openings. A key mechanism to help achieve these goals is the LinkedIn Recruiter product, which enables recruiters to search for relevant candidates and obtain candidate recommendations for their job postings. In this work, we highlight a set of unique information retrieval, system, and modeling challenges associated with talent search and recommendation systems.
Towards Deep and Representation Learning for Talent Search at LinkedIn
Sep 17, 2018
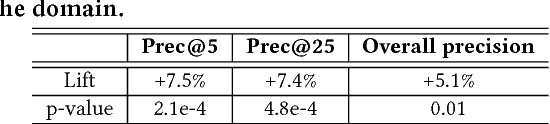
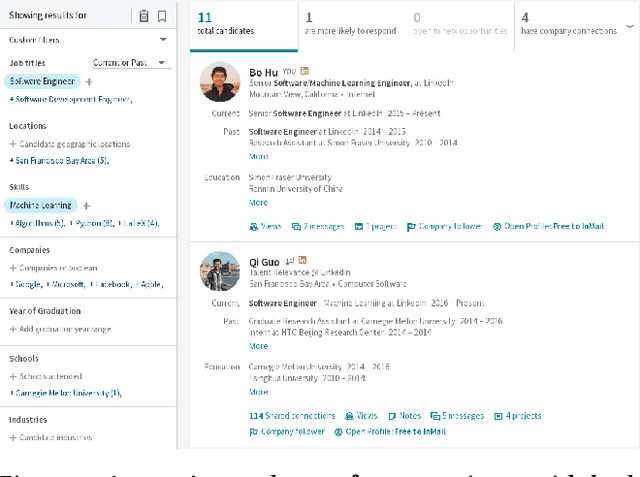
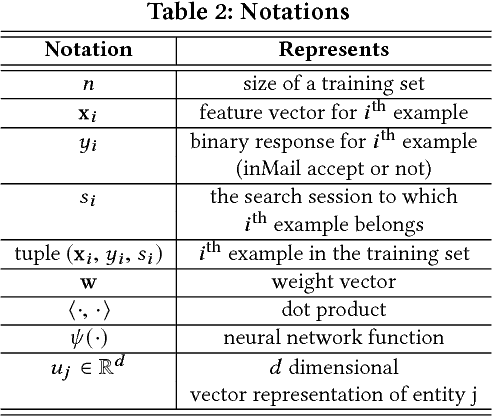
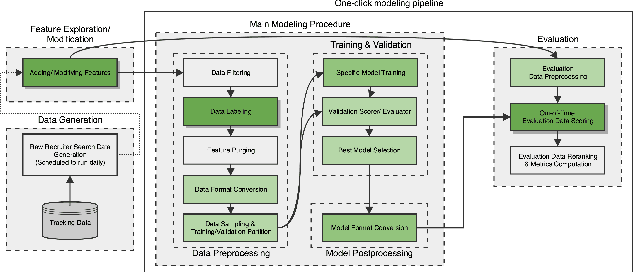
Talent search and recommendation systems at LinkedIn strive to match the potential candidates to the hiring needs of a recruiter or a hiring manager expressed in terms of a search query or a job posting. Recent work in this domain has mainly focused on linear models, which do not take complex relationships between features into account, as well as ensemble tree models, which introduce non-linearity but are still insufficient for exploring all the potential feature interactions, and strictly separate feature generation from modeling. In this paper, we present the results of our application of deep and representation learning models on LinkedIn Recruiter. Our key contributions include: (i) Learning semantic representations of sparse entities within the talent search domain, such as recruiter ids, candidate ids, and skill entity ids, for which we utilize neural network models that take advantage of LinkedIn Economic Graph, and (ii) Deep models for learning recruiter engagement and candidate response in talent search applications. We also explore learning to rank approaches applied to deep models, and show the benefits for the talent search use case. Finally, we present offline and online evaluation results for LinkedIn talent search and recommendation systems, and discuss potential challenges along the path to a fully deep model architecture. The challenges and approaches discussed generalize to any multi-faceted search engine.
Bringing Salary Transparency to the World: Computing Robust Compensation Insights via LinkedIn Salary
Sep 01, 2017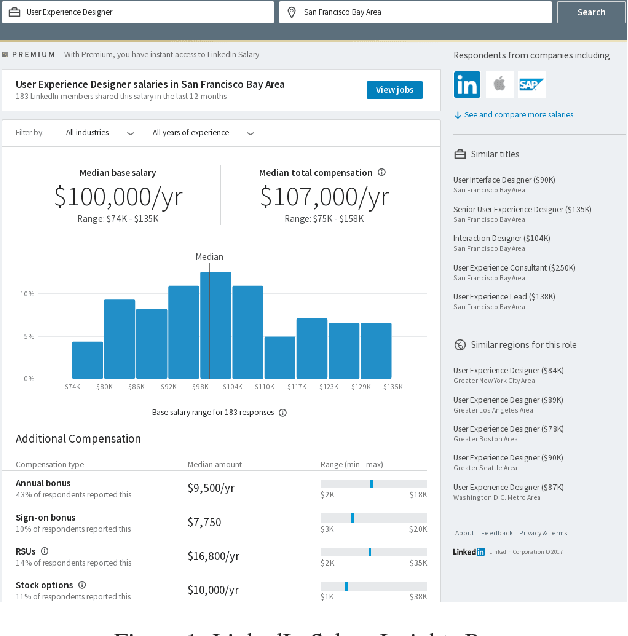
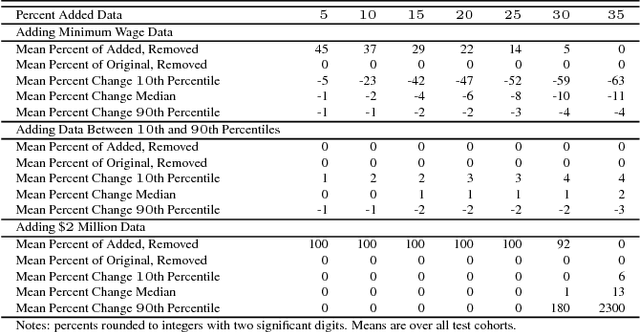
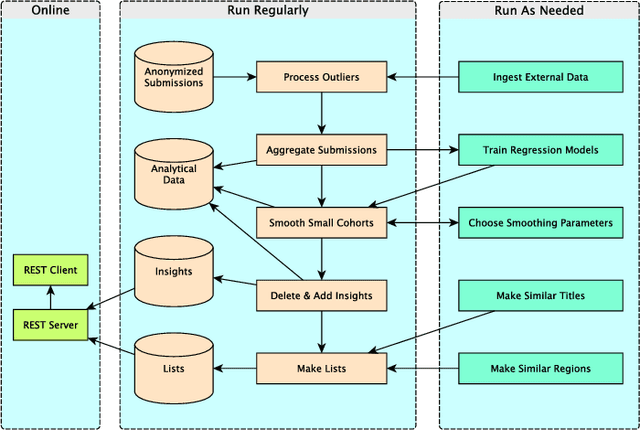
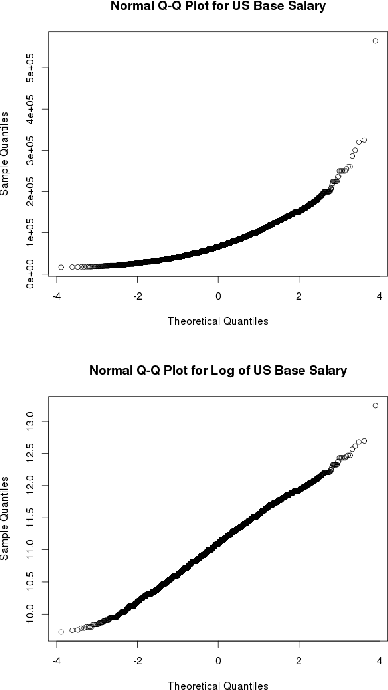
The recently launched LinkedIn Salary product has been designed with the goal of providing compensation insights to the world's professionals and thereby helping them optimize their earning potential. We describe the overall design and architecture of the statistical modeling system underlying this product. We focus on the unique data mining challenges while designing and implementing the system, and describe the modeling components such as Bayesian hierarchical smoothing that help to compute and present robust compensation insights to users. We report on extensive evaluation with nearly one year of de-identified compensation data collected from over one million LinkedIn users, thereby demonstrating the efficacy of the statistical models. We also highlight the lessons learned through the deployment of our system at LinkedIn.