 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Quality Type-aware Annotated Corpus and Lexicon for Harassment Research
May 23, 2018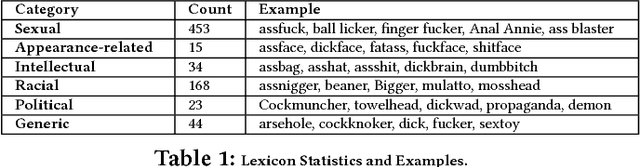
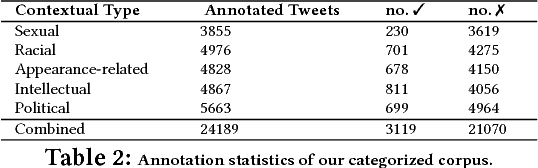

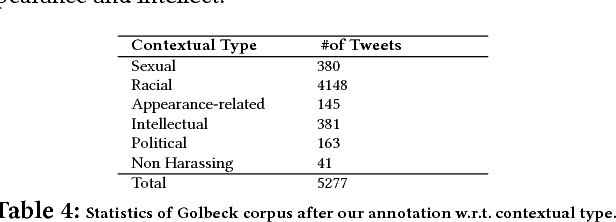
Having a quality annotated corpus is essential especially for applied research. Despite the recent focus of Web science community on researching about cyberbullying, the community dose not still have standard benchmarks. In this paper, we publish first, a quality annotated corpus and second, an offensive words lexicon capturing different types type of harassment as (i) sexual harassment, (ii) racial harassment, (iii) appearance-related harassment, (iv) intellectual harassment, and (v) political harassment.We crawled data from Twitter using our offensive lexicon. Then relied on the human judge to annotate the collected tweets w.r.t. the contextual types because using offensive words is not sufficient to reliably detect harassment. Our corpus consists of 25,000 annotated tweets in five contextual types. We are pleased to share this novel annotated corpus and the lexicon with the research community. The instruction to acquire the corpus has been published on the Git repository.
Semi-Supervised Approach to Monitoring Clinical Depressive Symptoms in Social Media
Oct 16, 2017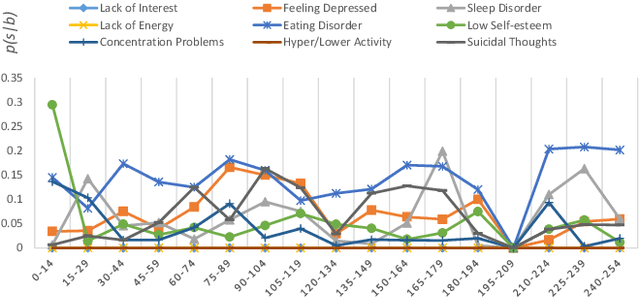
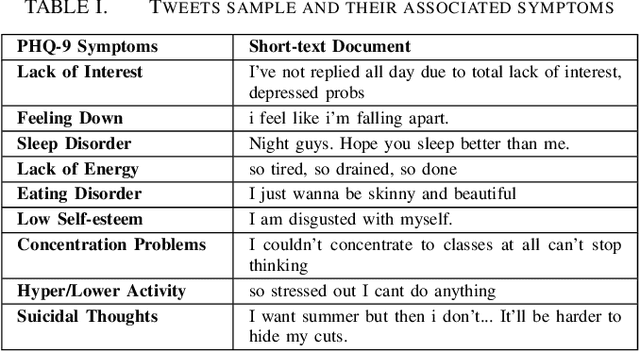
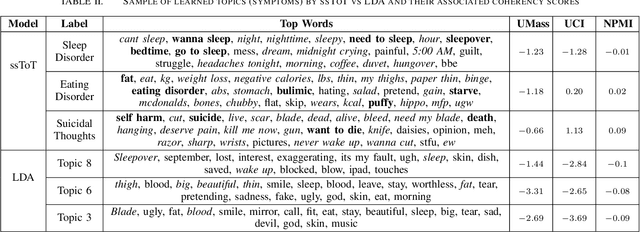
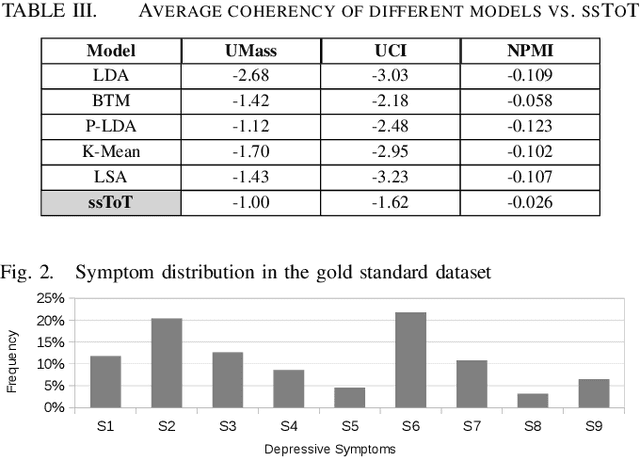
With the rise of social media, millions of people are routinely expressing their moods, feelings, and daily struggles with mental health issues on social media platforms like Twitter. Unlike traditional observational cohort studies conducted through questionnaires and self-reported surveys, we explore the reliable detection of clinical depression from tweets obtained unobtrusively. Based on the analysis of tweets crawled from users with self-reported depressive symptoms in their Twitter profiles, we demonstrate the potential for detecting clinical depression symptoms which emulate the PHQ-9 questionnaire clinicians use today. Our study uses a semi-supervised statistical model to evaluate how the duration of these symptoms and their expression on Twitter (in terms of word usage patterns and topical preferences) align with the medical findings reported via the PHQ-9. Our proactive and automatic screening tool is able to identify clinical depressive symptoms with an accuracy of 68% and precision of 72%.
Implicit Entity Linking in Tweets
Jul 26, 2017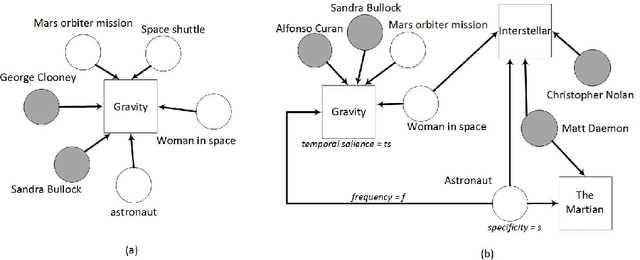
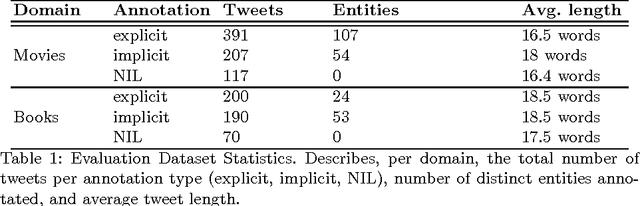


Over the years, Twitter has become one of the largest communication platforms providing key data to various applications such as brand monitoring, trend detection, among others. Entity linking is one of the major tasks in natural language understanding from tweets and it associates entity mentions in text to corresponding entries in knowledge bases in order to provide unambiguous interpretation and additional con- text. State-of-the-art techniques have focused on linking explicitly mentioned entities in tweets with reasonable success. However, we argue that in addition to explicit mentions i.e. The movie Gravity was more ex- pensive than the mars orbiter mission entities (movie Gravity) can also be mentioned implicitly i.e. This new space movie is crazy. you must watch it!. This paper introduces the problem of implicit entity linking in tweets. We propose an approach that models the entities by exploiting their factual and contextual knowledge. We demonstrate how to use these models to perform implicit entity linking on a ground truth dataset with 397 tweets from two domains, namely, Movie and Book. Specifically, we show: 1) the importance of linking implicit entities and its value addition to the standard entity linking task, and 2) the importance of exploiting contextual knowledge associated with an entity for linking their implicit mentions. We also make the ground truth dataset publicly available to foster the research in this new research area.
Knowledge will Propel Machine Understanding of Content: Extrapolating from Current Examples
Jul 14, 2017
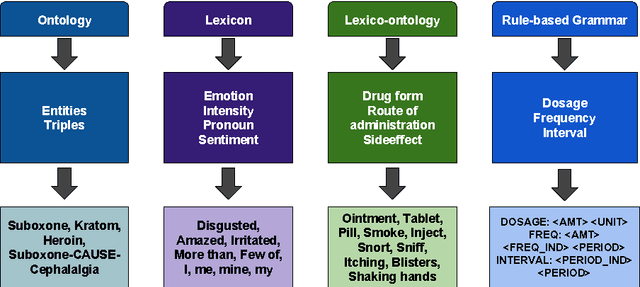
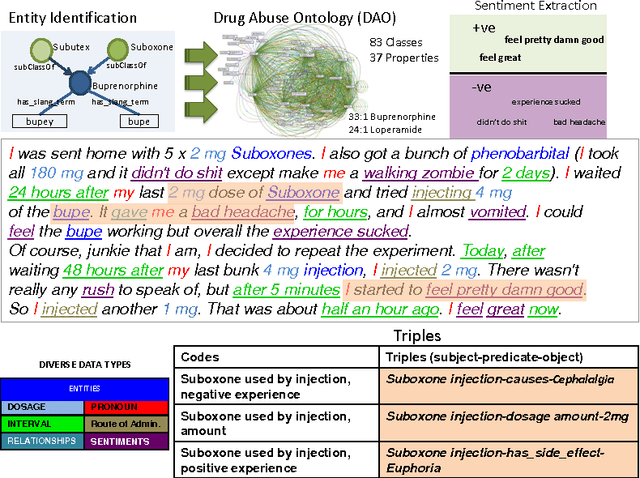
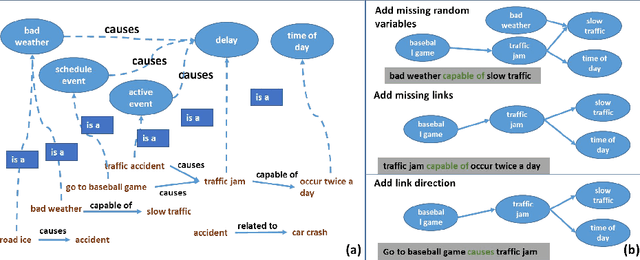
Machine Learning has been a big success story during the AI resurgence. One particular stand out success relates to learning from a massive amount of data. In spite of early assertions of the unreasonable effectiveness of data, there is increasing recognition for utilizing knowledge whenever it is available or can be created purposefully. In this paper, we discuss the indispensable role of knowledge for deeper understanding of content where (i) large amounts of training data are unavailable, (ii) the objects to be recognized are complex, (e.g., implicit entities and highly subjective content), and (iii) applications need to use complementary or related data in multiple modalities/media. What brings us to the cusp of rapid progress is our ability to (a) create relevant and reliable knowledge and (b) carefully exploit knowledge to enhance ML/NLP techniques. Using diverse examples, we seek to foretell unprecedented progress in our ability for deeper understanding and exploitation of multimodal data and continued incorporation of knowledge in learning techniques.
On Reasoning with RDF Statements about Statements using Singleton Property Triples
Sep 15, 2015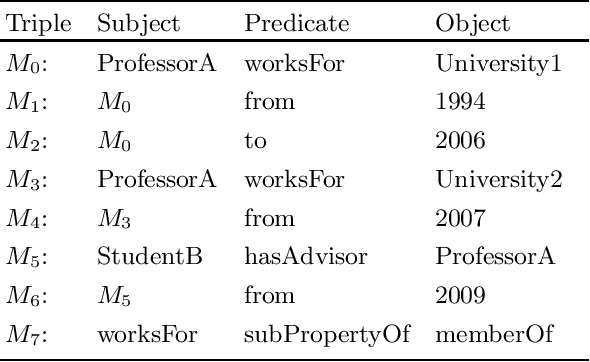
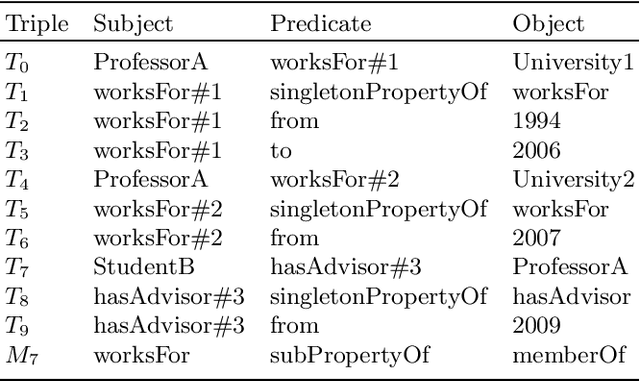
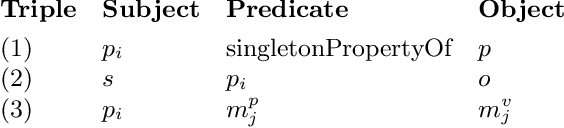
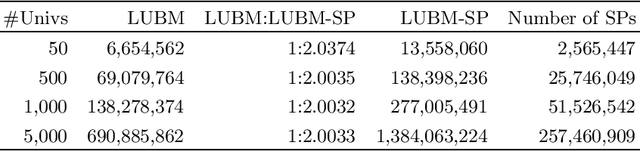
The Singleton Property (SP) approach has been proposed for representing and querying metadata about RDF triples such as provenance, time, location, and evidence. In this approach, one singleton property is created to uniquely represent a relationship in a particular context, and in general, generates a large property hierarchy in the schema. It has become the subject of important questions from Semantic Web practitioners. Can an existing reasoner recognize the singleton property triples? And how? If the singleton property triples describe a data triple, then how can a reasoner infer this data triple from the singleton property triples? Or would the large property hierarchy affect the reasoners in some way? We address these questions in this paper and present our study about the reasoning aspects of the singleton properties. We propose a simple mechanism to enable existing reasoners to recognize the singleton property triples, as well as to infer the data triples described by the singleton property triples. We evaluate the effect of the singleton property triples in the reasoning processes by comparing the performance on RDF datasets with and without singleton properties. Our evaluation uses as benchmark the LUBM datasets and the LUBM-SP datasets derived from LUBM with temporal information added through singleton properties.