 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKrishnaprasad Thirunarayan
Topic-Centric Unsupervised Multi-Document Summarization of Scientific and News Articles
Nov 03, 2020
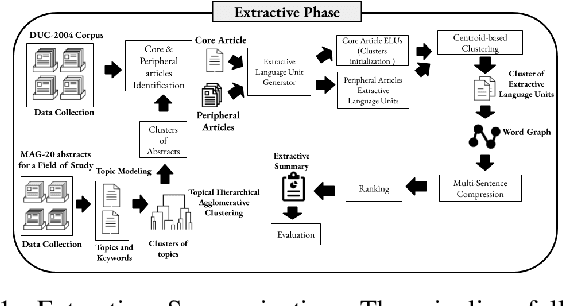

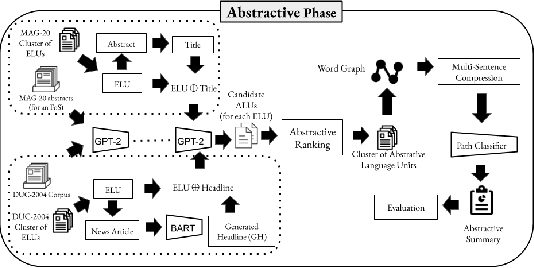
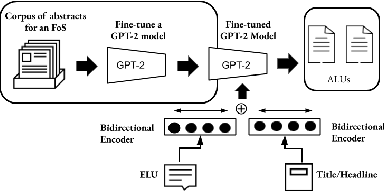
Recent advances in natural language processing have enabled automation of a wide range of tasks, including machine translation, named entity recognition, and sentiment analysis. Automated summarization of documents, or groups of documents, however, has remained elusive, with many efforts limited to extraction of keywords, key phrases, or key sentences. Accurate abstractive summarization has yet to be achieved due to the inherent difficulty of the problem, and limited availability of training data. In this paper, we propose a topic-centric unsupervised multi-document summarization framework to generate extractive and abstractive summaries for groups of scientific articles across 20 Fields of Study (FoS) in Microsoft Academic Graph (MAG) and news articles from DUC-2004 Task 2. The proposed algorithm generates an abstractive summary by developing salient language unit selection and text generation techniques. Our approach matches the state-of-the-art when evaluated on automated extractive evaluation metrics and performs better for abstractive summarization on five human evaluation metrics (entailment, coherence, conciseness, readability, and grammar). We achieve a kappa score of 0.68 between two co-author linguists who evaluated our results. We plan to publicly share MAG-20, a human-validated gold standard dataset of topic-clustered research articles and their summaries to promote research in abstractive summarization.
"When they say weed causes depression, but it's your fav antidepressant": Knowledge-aware Attention Framework for Relationship Extraction
Sep 21, 2020
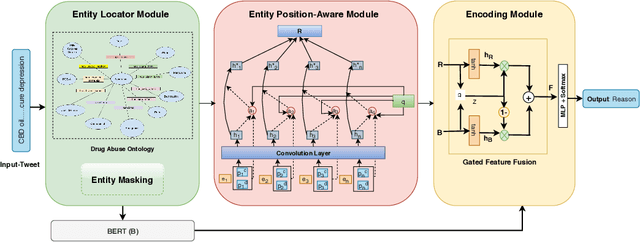

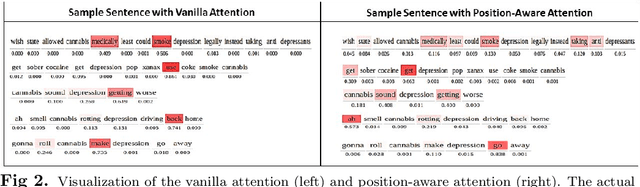
With the increasing legalization of medical and recreational use of cannabis, more research is needed to understand the association between depression and consumer behavior related to cannabis consumption. Big social media data has potential to provide deeper insights about these associations to public health analysts. In this interdisciplinary study, we demonstrate the value of incorporating domain-specific knowledge in the learning process to identify the relationships between cannabis use and depression. We develop an end-to-end knowledge infused deep learning framework (Gated-K-BERT) that leverages the pre-trained BERT language representation model and domain-specific declarative knowledge source (Drug Abuse Ontology (DAO)) to jointly extract entities and their relationship using gated fusion sharing mechanism. Our model is further tailored to provide more focus to the entities mention in the sentence through entity-position aware attention layer, where ontology is used to locate the target entities position. Experimental results show that inclusion of the knowledge-aware attentive representation in association with BERT can extract the cannabis-depression relationship with better coverage in comparison to the state-of-the-art relation extractor.
Measuring Pain in Sickle Cell Disease using Clinical Text
Aug 05, 2020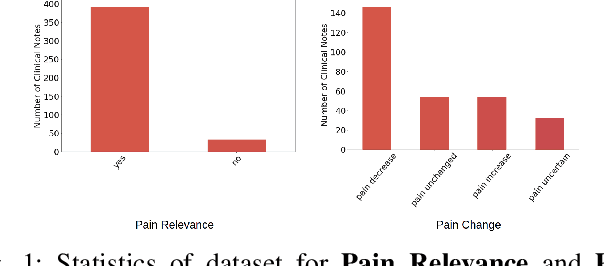
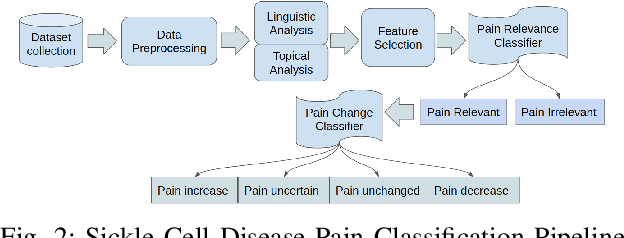
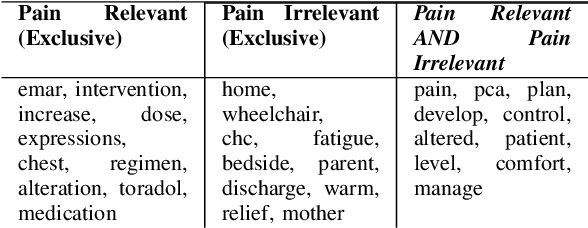
Sickle Cell Disease (SCD) is a hereditary disorder of red blood cells in humans. Complications such as pain, stroke, and organ failure occur in SCD as malformed, sickled red blood cells passing through small blood vessels get trapped. Particularly, acute pain is known to be the primary symptom of SCD. The insidious and subjective nature of SCD pain leads to challenges in pain assessment among Medical Practitioners (MPs). Thus, accurate identification of markers of pain in patients with SCD is crucial for pain management. Classifying clinical notes of patients with SCD based on their pain level enables MPs to give appropriate treatment. We propose a binary classification model to predict pain relevance of clinical notes and a multiclass classification model to predict pain level. While our four binary machine learning (ML) classifiers are comparable in their performance, Decision Trees had the best performance for the multiclass classification task achieving 0.70 in F-measure. Our results show the potential clinical text analysis and machine learning offer to pain management in sickle cell patients.
Towards Geocoding Spatial Expressions
Jun 12, 2019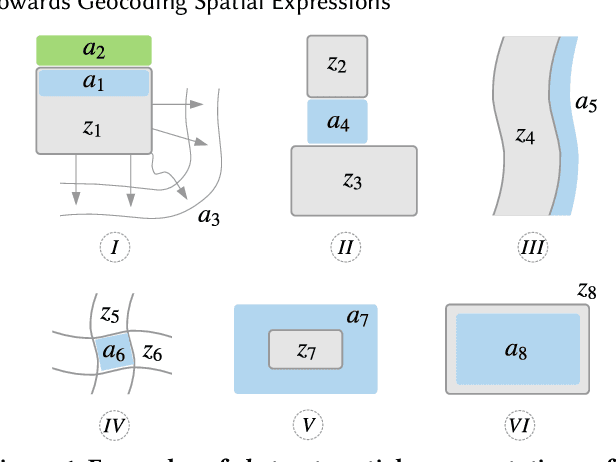
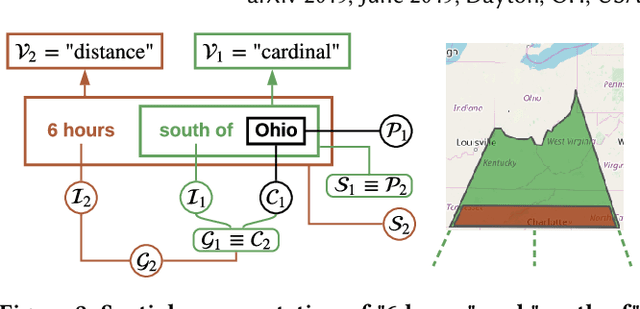
Imprecise composite location references formed using ad hoc spatial expressions in English text makes the geocoding task challenging for both inference and evaluation. Typically such spatial expressions fill in unestablished areas with new toponyms for finer spatial referents. For example, the spatial extent of the ad hoc spatial expression "north of" or "50 minutes away from" in relation to the toponym "Dayton, OH" refers to an ambiguous, imprecise area, requiring translation from this qualitative representation to a quantitative one with precise semantics using systems such as WGS84. Here we highlight the challenges of geocoding such referents and propose a formal representation that employs background knowledge, semantic approximations and rules, and fuzzy linguistic variables. We also discuss an appropriate evaluation technique for the task that is based on human contextualized and subjective judgment.
Fusing Visual, Textual and Connectivity Clues for Studying Mental Health
Feb 19, 2019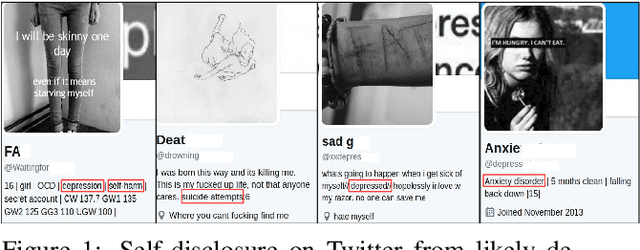
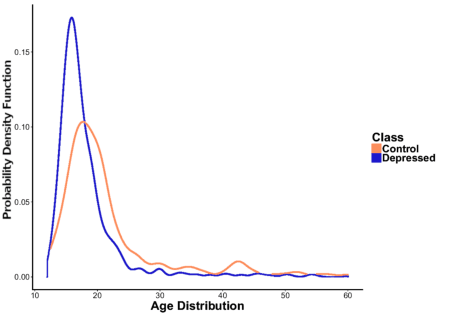
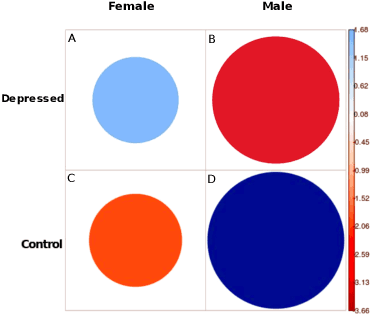
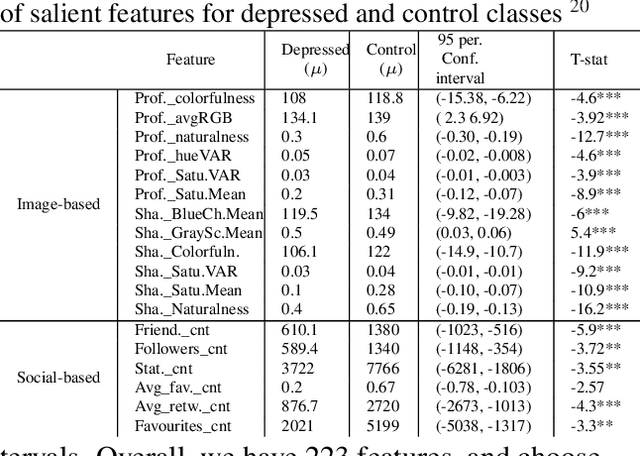
With ubiquity of social media platforms, millions of people are sharing their online persona by expressing their thoughts, moods, emotions, feelings, and even their daily struggles with mental health issues voluntarily and publicly on social media. Unlike the most existing efforts which study depression by analyzing textual content, we examine and exploit multimodal big data to discern depressive behavior using a wide variety of features including individual-level demographics. By developing a multimodal framework and employing statistical techniques for fusing heterogeneous sets of features obtained by processing visual, textual and user interaction data, we significantly enhance the current state-of-the-art approaches for identifying depressed individuals on Twitter (improving the average F1-Score by 5 percent) as well as facilitate demographic inference from social media for broader applications. Besides providing insights into the relationship between demographics and mental health, our research assists in the design of a new breed of demographic-aware health interventions.
Analyzing and learning the language for different types of harassment
Nov 01, 2018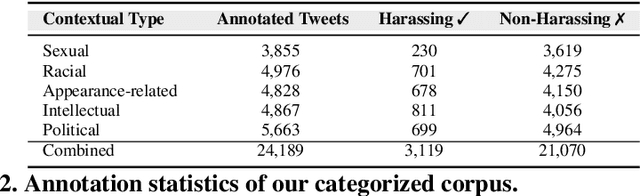
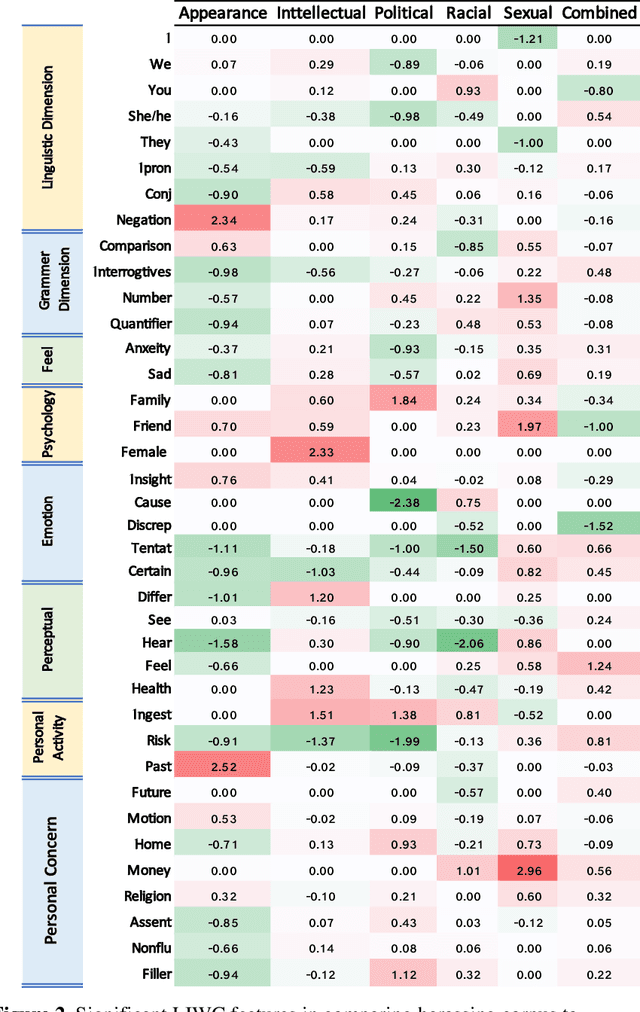
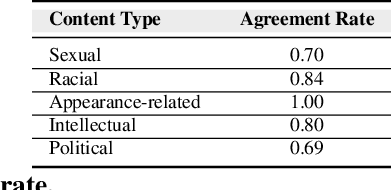
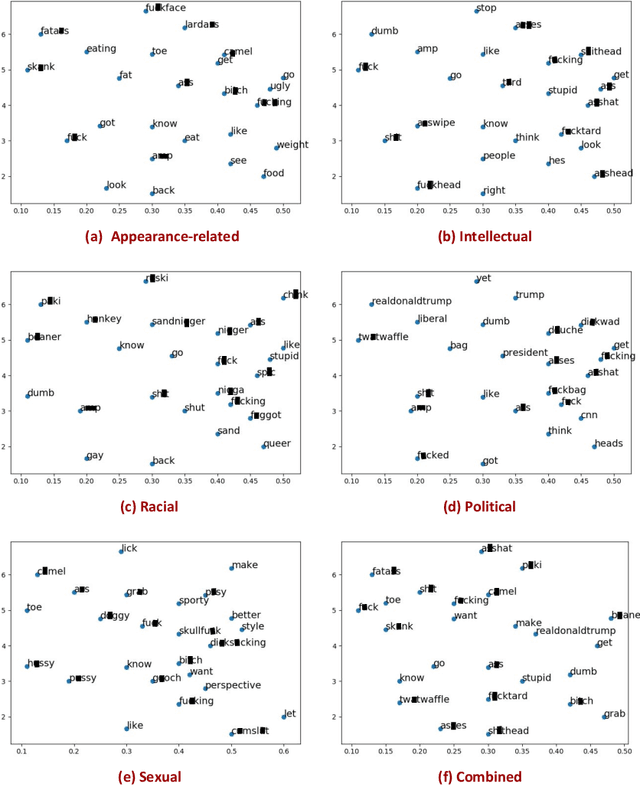
The presence of a significant amount of harassment in user-generated content and its negative impact calls for robust automatic detection approaches. This requires that we can identify different forms or types of harassment. Earlier work has classified harassing language in terms of hurtfulness, abusiveness, sentiment, and profanity. However, to identify and understand harassment more accurately, it is essential to determine the context that represents the interrelated conditions in which they occur. In this paper, we introduce the notion of contextual type to harassment involving five categories: (i) sexual, (ii) racial, (iii) appearance-related, (iv) intellectual and (v) political. We utilize an annotated corpus from Twitter distinguishing these types of harassment. To study the context for each type that sheds light on the linguistic meaning, interpretation, and distribution, we conduct two lines of investigation: an extensive linguistic analysis, and a statistical distribution of unigrams. We then build type-ware classifiers to automate the identification of type-specific harassment. Our experiments demonstrate that these classifiers provide competitive accuracy for identifying and analyzing harassment on social media. We present extensive discussion and major observations about the effectiveness of type-aware classifiers using a detailed comparison setup providing insight into the role of type-dependent features.
CEVO: Comprehensive EVent Ontology Enhancing Cognitive Annotation
Oct 03, 2018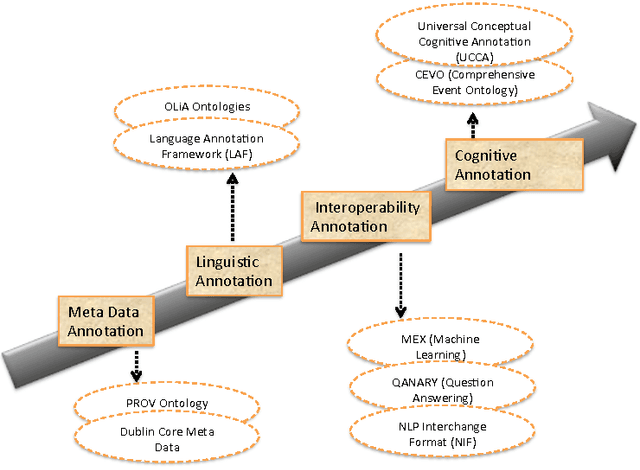
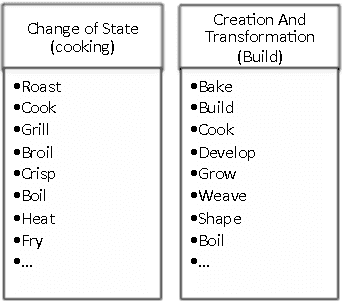
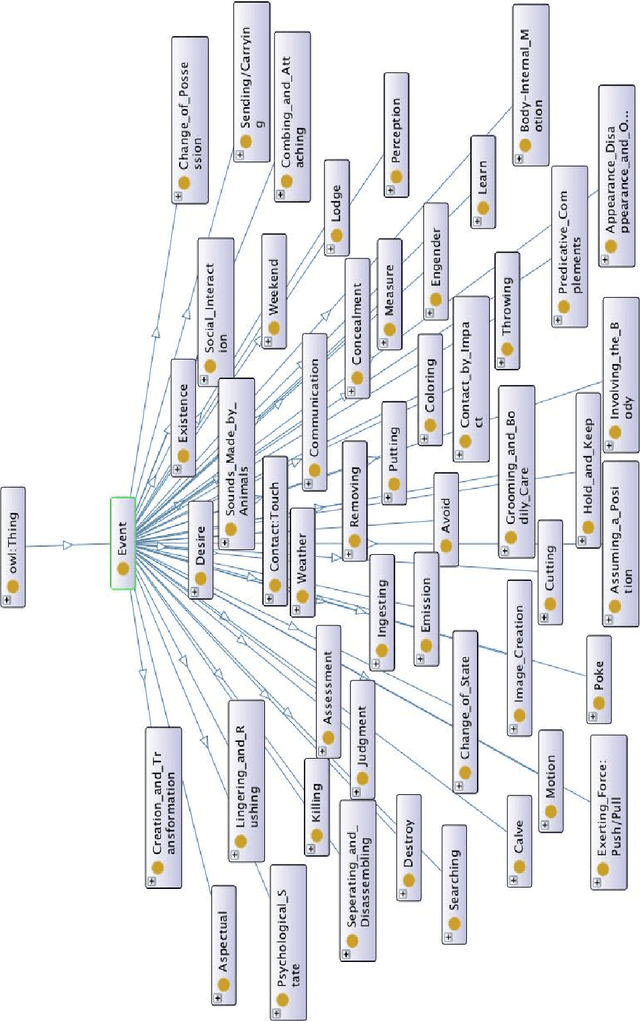
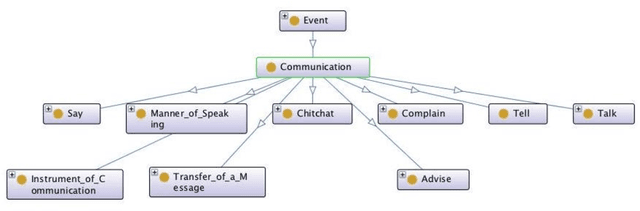
While the general analysis of named entities has received substantial research attention on unstructured as well as structured data, the analysis of relations among named entities has received limited focus. In fact, a review of the literature revealed a deficiency in research on the abstract conceptualization required to organize relations. We believe that such an abstract conceptualization can benefit various communities and applications such as natural language processing, information extraction, machine learning, and ontology engineering. In this paper, we present Comprehensive EVent Ontology (CEVO), built on Levin's conceptual hierarchy of English verbs that categorizes verbs with shared meaning, and syntactic behavior. We present the fundamental concepts and requirements for this ontology. Furthermore, we present three use cases employing the CEVO ontology on annotation tasks: (i) annotating relations in plain text, (ii) annotating ontological properties, and (iii) linking textual relations to ontological properties. These use-cases demonstrate the benefits of using CEVO for annotation: (i) annotating English verbs from an abstract conceptualization, (ii) playing the role of an upper ontology for organizing ontological properties, and (iii) facilitating the annotation of text relations using any underlying vocabulary. This resource is available at https://shekarpour.github.io/cevo.io/ using https://w3id.org/cevo namespace.
Principles for Developing a Knowledge Graph of Interlinked Events from News Headlines on Twitter
Aug 06, 2018
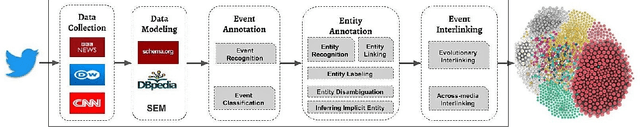
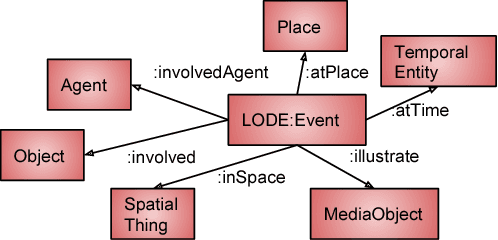

The ever-growing datasets published on Linked Open Data mainly contain encyclopedic information. However, there is a lack of quality structured and semantically annotated datasets extracted from unstructured real-time sources. In this paper, we present principles for developing a knowledge graph of interlinked events using the case study of news headlines published on Twitter which is a real-time and eventful source of fresh information. We represent the essential pipeline containing the required tasks ranging from choosing background data model, event annotation (i.e., event recognition and classification), entity annotation and eventually interlinking events. The state-of-the-art is limited to domain-specific scenarios for recognizing and classifying events, whereas this paper plays the role of a domain-agnostic road-map for developing a knowledge graph of interlinked events.
A Practical Incremental Learning Framework For Sparse Entity Extraction
Jun 26, 2018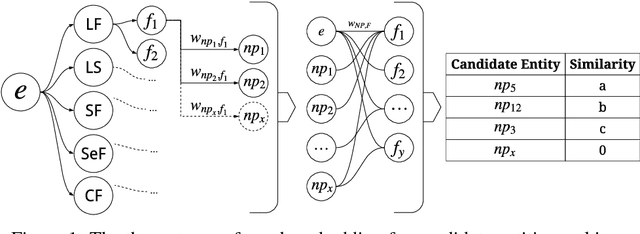
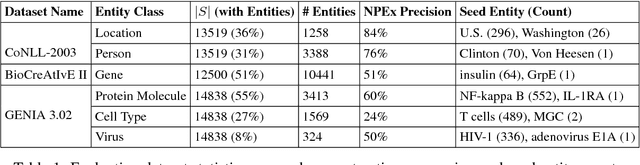
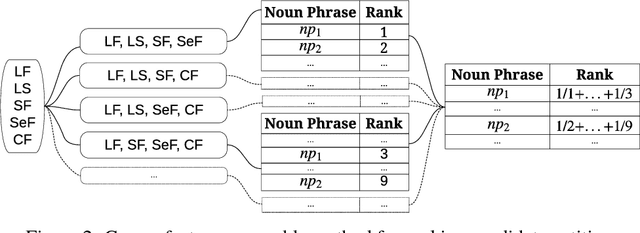
This work addresses challenges arising from extracting entities from textual data, including the high cost of data annotation, model accuracy, selecting appropriate evaluation criteria, and the overall quality of annotation. We present a framework that integrates Entity Set Expansion (ESE) and Active Learning (AL) to reduce the annotation cost of sparse data and provide an online evaluation method as feedback. This incremental and interactive learning framework allows for rapid annotation and subsequent extraction of sparse data while maintaining high accuracy. We evaluate our framework on three publicly available datasets and show that it drastically reduces the cost of sparse entity annotation by an average of 85% and 45% to reach 0.9 and 1.0 F-Scores respectively. Moreover, the method exhibited robust performance across all datasets.
Location Name Extraction from Targeted Text Streams using Gazetteer-based Statistical Language Models
Jun 07, 2018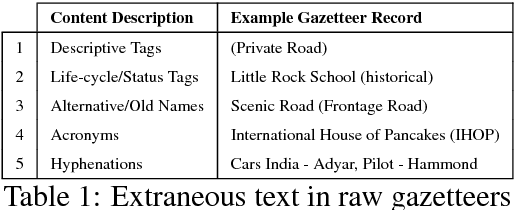
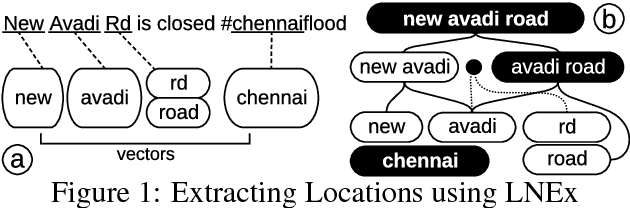

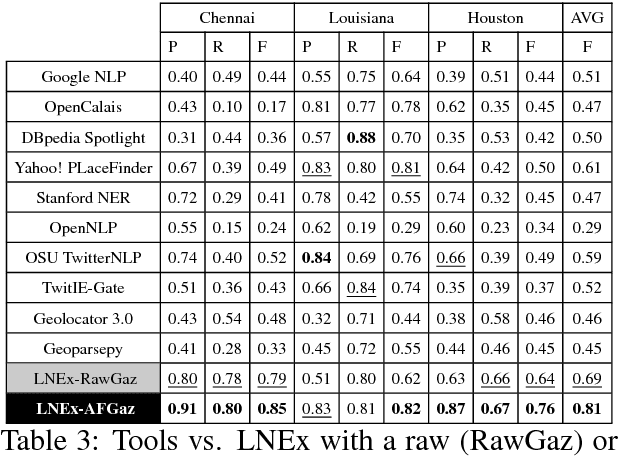
Extracting location names from informal and unstructured social media data requires the identification of referent boundaries and partitioning compound names. Variability, particularly systematic variability in location names (Carroll, 1983), challenges the identification task. Some of this variability can be anticipated as operations within a statistical language model, in this case drawn from gazetteers such as OpenStreetMap (OSM), Geonames, and DBpedia. This permits evaluation of an observed n-gram in Twitter targeted text as a legitimate location name variant from the same location-context. Using n-gram statistics and location-related dictionaries, our Location Name Extraction tool (LNEx) handles abbreviations and automatically filters and augments the location names in gazetteers (handling name contractions and auxiliary contents) to help detect the boundaries of multi-word location names and thereby delimit them in texts. We evaluated our approach on 4,500 event-specific tweets from three targeted streams to compare the performance of LNEx against that of ten state-of-the-art taggers that rely on standard semantic, syntactic and/or orthographic features. LNEx improved the average F-Score by 33-179%, outperforming all taggers. Further, LNEx is capable of stream processing.