 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe KnowWhereGraph Ontology
Oct 17, 2024



KnowWhereGraph is one of the largest fully publicly available geospatial knowledge graphs. It includes data from 30 layers on natural hazards (e.g., hurricanes, wildfires), climate variables (e.g., air temperature, precipitation), soil properties, crop and land-cover types, demographics, and human health, various place and region identifiers, among other themes. These have been leveraged through the graph by a variety of applications to address challenges in food security and agricultural supply chains; sustainability related to soil conservation practices and farm labor; and delivery of emergency humanitarian aid following a disaster. In this paper, we introduce the ontology that acts as the schema for KnowWhereGraph. This broad overview provides insight into the requirements and design specifications for the graph and its schema, including the development methodology (modular ontology modeling) and the resources utilized to implement, materialize, and deploy KnowWhereGraph with its end-user interfaces and public query SPARQL endpoint.
They Look Like Each Other: Case-based Reasoning for Explainable Depression Detection on Twitter using Large Language Models
Jul 21, 2024



Depression is a common mental health issue that requires prompt diagnosis and treatment. Despite the promise of social media data for depression detection, the opacity of employed deep learning models hinders interpretability and raises bias concerns. We address this challenge by introducing ProtoDep, a novel, explainable framework for Twitter-based depression detection. ProtoDep leverages prototype learning and the generative power of Large Language Models to provide transparent explanations at three levels: (i) symptom-level explanations for each tweet and user, (ii) case-based explanations comparing the user to similar individuals, and (iii) transparent decision-making through classification weights. Evaluated on five benchmark datasets, ProtoDep achieves near state-of-the-art performance while learning meaningful prototypes. This multi-faceted approach offers significant potential to enhance the reliability and transparency of depression detection on social media, ultimately aiding mental health professionals in delivering more informed care.
Conversational Ontology Alignment with ChatGPT
Aug 18, 2023This study evaluates the applicability and efficiency of ChatGPT for ontology alignment using a naive approach. ChatGPT's output is compared to the results of the Ontology Alignment Evaluation Initiative 2022 campaign using conference track ontologies. This comparison is intended to provide insights into the capabilities of a conversational large language model when used in a naive way for ontology matching, and to investigate the potential advantages and disadvantages of this approach.
Fusing Visual, Textual and Connectivity Clues for Studying Mental Health
Feb 19, 2019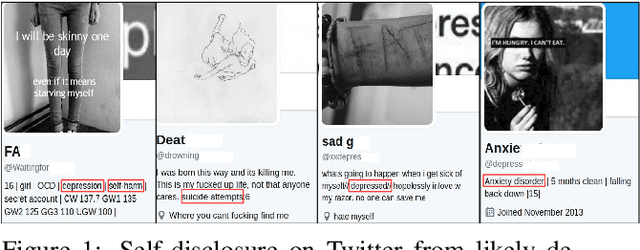
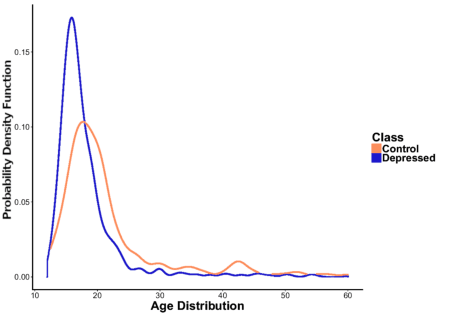
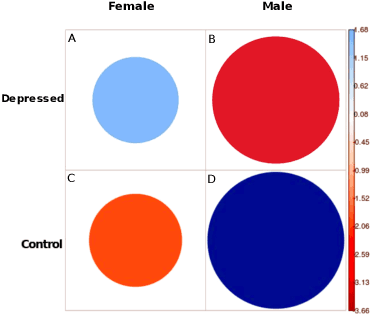
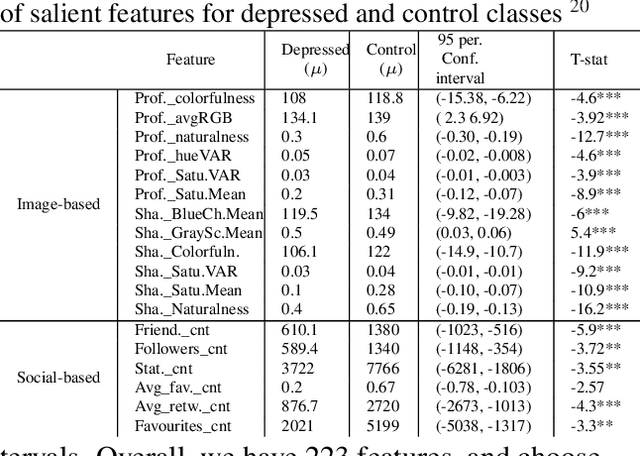
With ubiquity of social media platforms, millions of people are sharing their online persona by expressing their thoughts, moods, emotions, feelings, and even their daily struggles with mental health issues voluntarily and publicly on social media. Unlike the most existing efforts which study depression by analyzing textual content, we examine and exploit multimodal big data to discern depressive behavior using a wide variety of features including individual-level demographics. By developing a multimodal framework and employing statistical techniques for fusing heterogeneous sets of features obtained by processing visual, textual and user interaction data, we significantly enhance the current state-of-the-art approaches for identifying depressed individuals on Twitter (improving the average F1-Score by 5 percent) as well as facilitate demographic inference from social media for broader applications. Besides providing insights into the relationship between demographics and mental health, our research assists in the design of a new breed of demographic-aware health interventions.
Machine learning for Internet of Things data analysis: A survey
Feb 17, 2018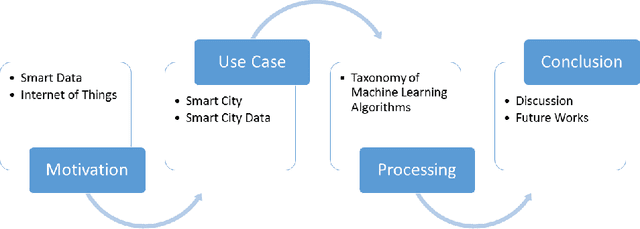
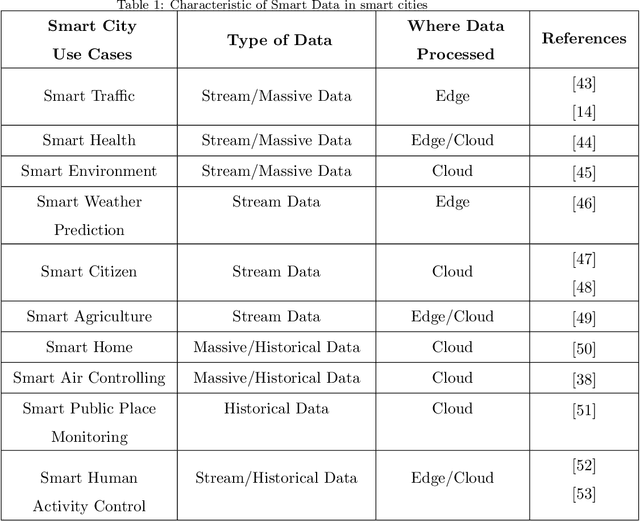
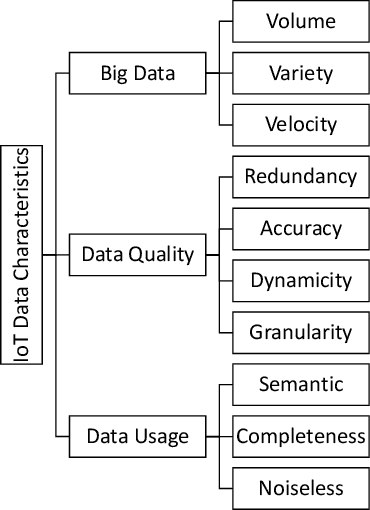
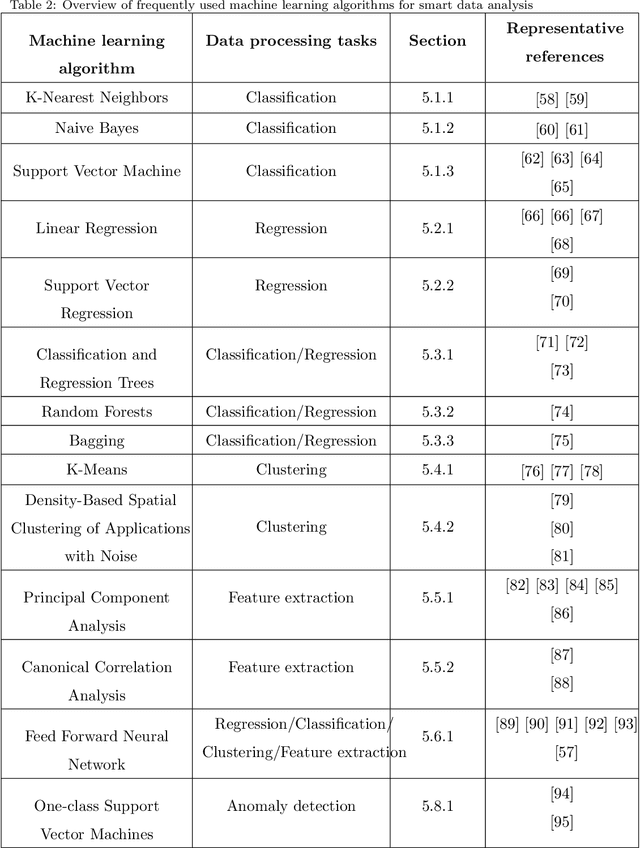
Rapid developments in hardware, software, and communication technologies have allowed the emergence of Internet-connected sensory devices that provide observation and data measurement from the physical world. By 2020, it is estimated that the total number of Internet-connected devices being used will be between 25 and 50 billion. As the numbers grow and technologies become more mature, the volume of data published will increase. Internet-connected devices technology, referred to as Internet of Things (IoT), continues to extend the current Internet by providing connectivity and interaction between the physical and cyber worlds. In addition to increased volume, the IoT generates Big Data characterized by velocity in terms of time and location dependency, with a variety of multiple modalities and varying data quality. Intelligent processing and analysis of this Big Data is the key to developing smart IoT applications. This article assesses the different machine learning methods that deal with the challenges in IoT data by considering smart cities as the main use case. The key contribution of this study is presentation of a taxonomy of machine learning algorithms explaining how different techniques are applied to the data in order to extract higher level information. The potential and challenges of machine learning for IoT data analytics will also be discussed. A use case of applying Support Vector Machine (SVM) on Aarhus Smart City traffic data is presented for a more detailed exploration.