 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHYVE: Hybrid Views for LLM Context Engineering over Machine Data
Apr 07, 2026Machine data is central to observability and diagnosis in modern computing systems, appearing in logs, metrics, telemetry traces, and configuration snapshots. When provided to large language models (LLMs), this data typically arrives as a mixture of natural language and structured payloads such as JSON or Python/AST literals. Yet LLMs remain brittle on such inputs, particularly when they are long, deeply nested, and dominated by repetitive structure. We present HYVE (HYbrid ViEw), a framework for LLM context engineering for inputs containing large machine-data payloads, inspired by database management principles. HYVE surrounds model invocation with coordinated preprocessing and postprocessing, centered on a request-scoped datastore augmented with schema information. During preprocessing, HYVE detects repetitive structure in raw inputs, materializes it in the datastore, transforms it into hybrid columnar and row-oriented views, and selectively exposes only the most relevant representation to the LLM. During postprocessing, HYVE either returns the model output directly, queries the datastore to recover omitted information, or performs a bounded additional LLM call for SQL-augmented semantic synthesis. We evaluate HYVE on diverse real-world workloads spanning knowledge QA, chart generation, anomaly detection, and multi-step network troubleshooting. Across these benchmarks, HYVE reduces token usage by 50-90% while maintaining or improving output quality. On structured generation tasks, it improves chart-generation accuracy by up to 132% and reduces latency by up to 83%. Overall, HYVE offers a practical approximation to an effectively unbounded context window for prompts dominated by large machine-data payloads.
A Practical Incremental Learning Framework For Sparse Entity Extraction
Jun 26, 2018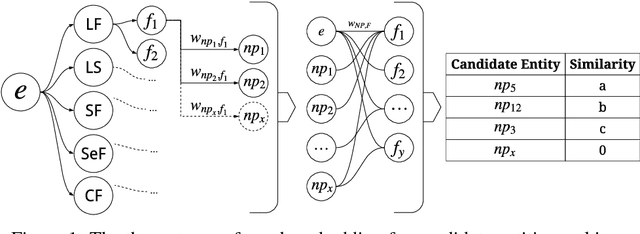
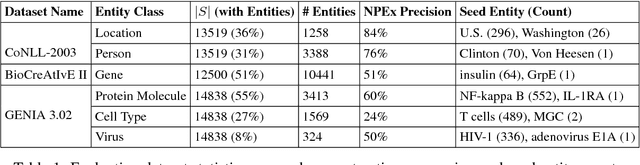
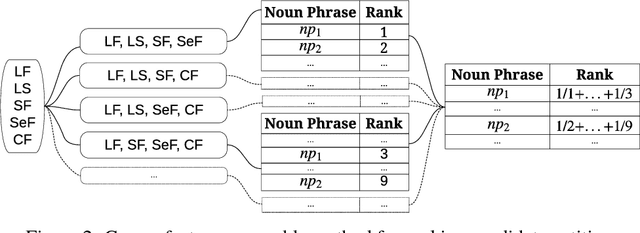
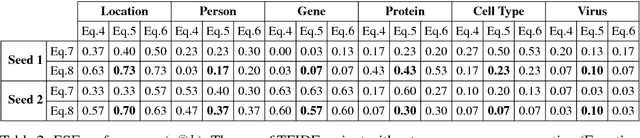
This work addresses challenges arising from extracting entities from textual data, including the high cost of data annotation, model accuracy, selecting appropriate evaluation criteria, and the overall quality of annotation. We present a framework that integrates Entity Set Expansion (ESE) and Active Learning (AL) to reduce the annotation cost of sparse data and provide an online evaluation method as feedback. This incremental and interactive learning framework allows for rapid annotation and subsequent extraction of sparse data while maintaining high accuracy. We evaluate our framework on three publicly available datasets and show that it drastically reduces the cost of sparse entity annotation by an average of 85% and 45% to reach 0.9 and 1.0 F-Scores respectively. Moreover, the method exhibited robust performance across all datasets.