 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic audiovisual synchronisation for ultrasound tongue imaging
May 31, 2021

Ultrasound tongue imaging is used to visualise the intra-oral articulators during speech production. It is utilised in a range of applications, including speech and language therapy and phonetics research. Ultrasound and speech audio are recorded simultaneously, and in order to correctly use this data, the two modalities should be correctly synchronised. Synchronisation is achieved using specialised hardware at recording time, but this approach can fail in practice resulting in data of limited usability. In this paper, we address the problem of automatically synchronising ultrasound and audio after data collection. We first investigate the tolerance of expert ultrasound users to synchronisation errors in order to find the thresholds for error detection. We use these thresholds to define accuracy scoring boundaries for evaluating our system. We then describe our approach for automatic synchronisation, which is driven by a self-supervised neural network, exploiting the correlation between the two signals to synchronise them. We train our model on data from multiple domains with different speaker characteristics, different equipment, and different recording environments, and achieve an accuracy >92.4% on held-out in-domain data. Finally, we introduce a novel resource, the Cleft dataset, which we gathered with a new clinical subgroup and for which hardware synchronisation proved unreliable. We apply our model to this out-of-domain data, and evaluate its performance subjectively with expert users. Results show that users prefer our model's output over the original hardware output 79.3% of the time. Our results demonstrate the strength of our approach and its ability to generalise to data from new domains.
Silent versus modal multi-speaker speech recognition from ultrasound and video
Feb 27, 2021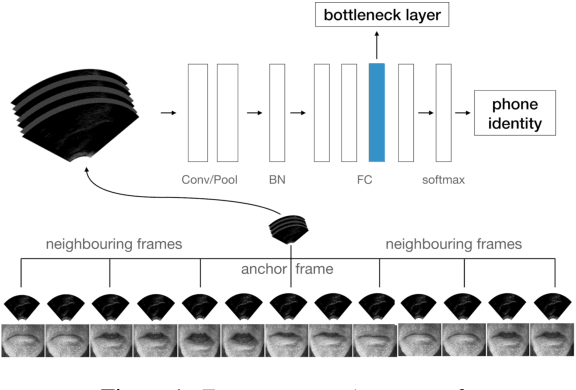
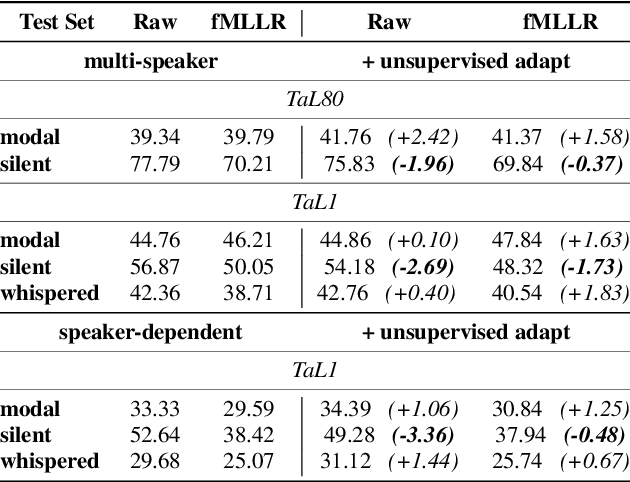
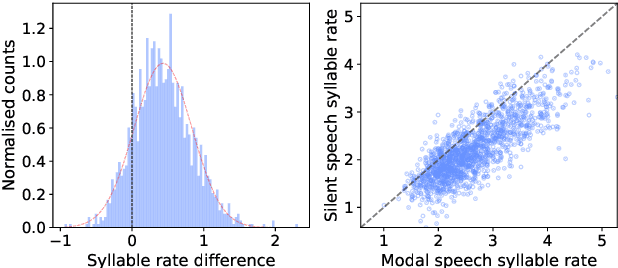

We investigate multi-speaker speech recognition from ultrasound images of the tongue and video images of the lips. We train our systems on imaging data from modal speech, and evaluate on matched test sets of two speaking modes: silent and modal speech. We observe that silent speech recognition from imaging data underperforms compared to modal speech recognition, likely due to a speaking-mode mismatch between training and testing. We improve silent speech recognition performance using techniques that address the domain mismatch, such as fMLLR and unsupervised model adaptation. We also analyse the properties of silent and modal speech in terms of utterance duration and the size of the articulatory space. To estimate the articulatory space, we compute the convex hull of tongue splines, extracted from ultrasound tongue images. Overall, we observe that the duration of silent speech is longer than that of modal speech, and that silent speech covers a smaller articulatory space than modal speech. Although these two properties are statistically significant across speaking modes, they do not directly correlate with word error rates from speech recognition.
Exploiting ultrasound tongue imaging for the automatic detection of speech articulation errors
Feb 27, 2021

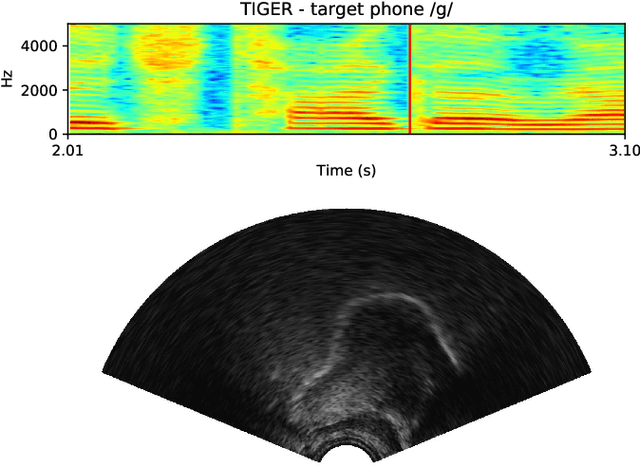
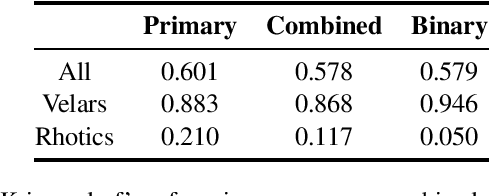
Speech sound disorders are a common communication impairment in childhood. Because speech disorders can negatively affect the lives and the development of children, clinical intervention is often recommended. To help with diagnosis and treatment, clinicians use instrumented methods such as spectrograms or ultrasound tongue imaging to analyse speech articulations. Analysis with these methods can be laborious for clinicians, therefore there is growing interest in its automation. In this paper, we investigate the contribution of ultrasound tongue imaging for the automatic detection of speech articulation errors. Our systems are trained on typically developing child speech and augmented with a database of adult speech using audio and ultrasound. Evaluation on typically developing speech indicates that pre-training on adult speech and jointly using ultrasound and audio gives the best results with an accuracy of 86.9%. To evaluate on disordered speech, we collect pronunciation scores from experienced speech and language therapists, focusing on cases of velar fronting and gliding of /r/. The scores show good inter-annotator agreement for velar fronting, but not for gliding errors. For automatic velar fronting error detection, the best results are obtained when jointly using ultrasound and audio. The best system correctly detects 86.6% of the errors identified by experienced clinicians. Out of all the segments identified as errors by the best system, 73.2% match errors identified by clinicians. Results on automatic gliding detection are harder to interpret due to poor inter-annotator agreement, but appear promising. Overall findings suggest that automatic detection of speech articulation errors has potential to be integrated into ultrasound intervention software for automatically quantifying progress during speech therapy.
* 15 pages, 9 figures, 6 tables
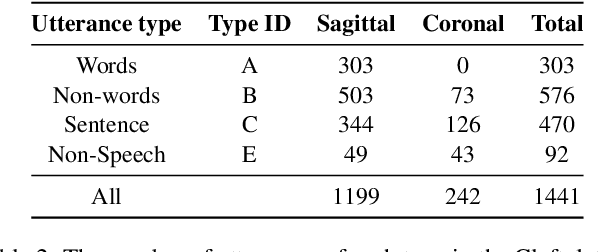
TaL: a synchronised multi-speaker corpus of ultrasound tongue imaging, audio, and lip videos
Nov 19, 2020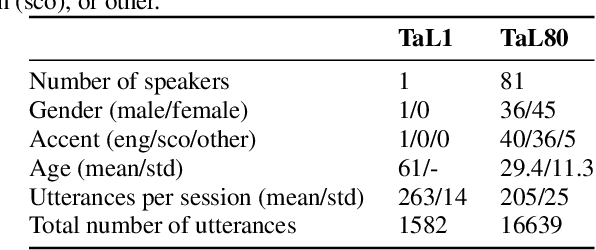
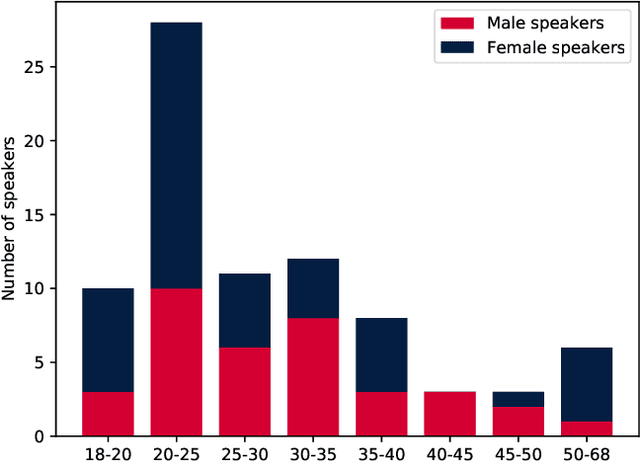

We present the Tongue and Lips corpus (TaL), a multi-speaker corpus of audio, ultrasound tongue imaging, and lip videos. TaL consists of two parts: TaL1 is a set of six recording sessions of one professional voice talent, a male native speaker of English; TaL80 is a set of recording sessions of 81 native speakers of English without voice talent experience. Overall, the corpus contains 24 hours of parallel ultrasound, video, and audio data, of which approximately 13.5 hours are speech. This paper describes the corpus and presents benchmark results for the tasks of speech recognition, speech synthesis (articulatory-to-acoustic mapping), and automatic synchronisation of ultrasound to audio. The TaL corpus is publicly available under the CC BY-NC 4.0 license.
Ultrasound tongue imaging for diarization and alignment of child speech therapy sessions
Aug 15, 2019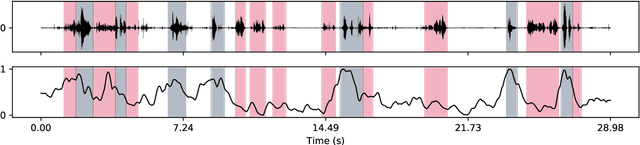
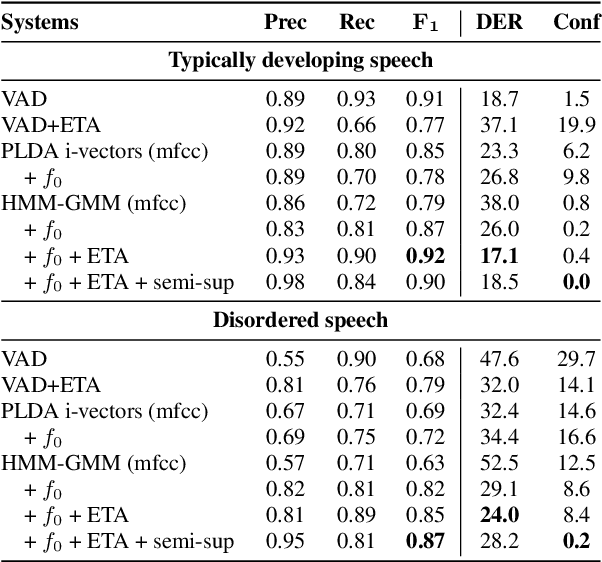
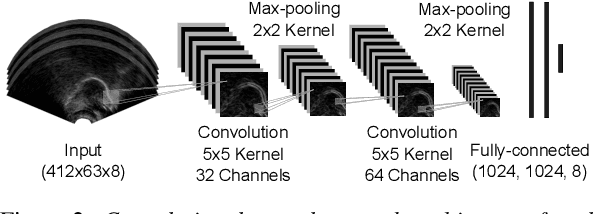
We investigate the automatic processing of child speech therapy sessions using ultrasound visual biofeedback, with a specific focus on complementing acoustic features with ultrasound images of the tongue for the tasks of speaker diarization and time-alignment of target words. For speaker diarization, we propose an ultrasound-based time-domain signal which we call estimated tongue activity. For word-alignment, we augment an acoustic model with low-dimensional representations of ultrasound images of the tongue, learned by a convolutional neural network. We conduct our experiments using the Ultrasuite repository of ultrasound and speech recordings for child speech therapy sessions. For both tasks, we observe that systems augmented with ultrasound data outperform corresponding systems using only the audio signal.
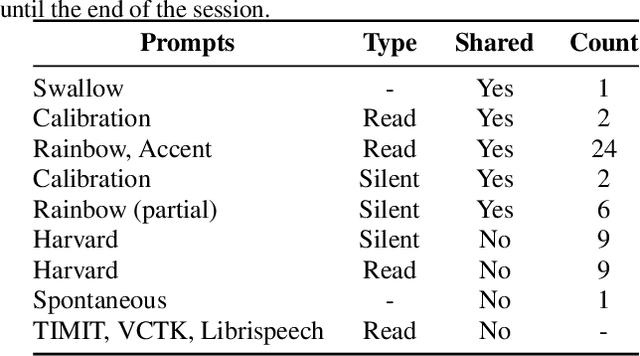
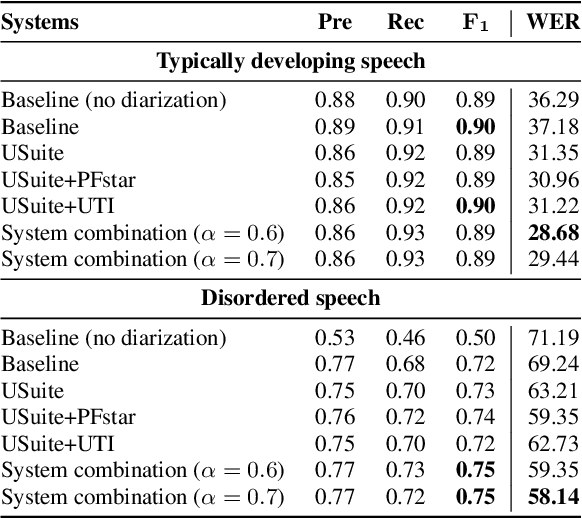
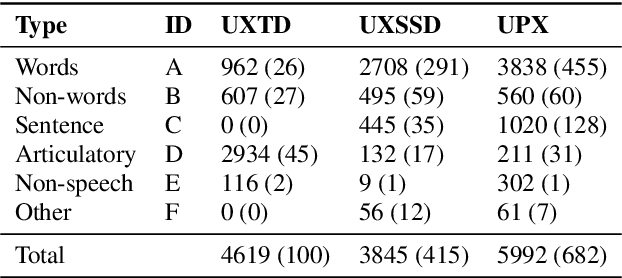
UltraSuite: A Repository of Ultrasound and Acoustic Data from Child Speech Therapy Sessions
Jul 01, 2019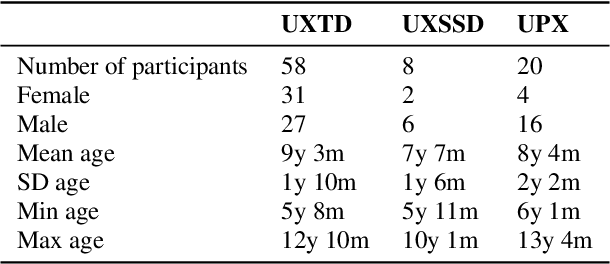

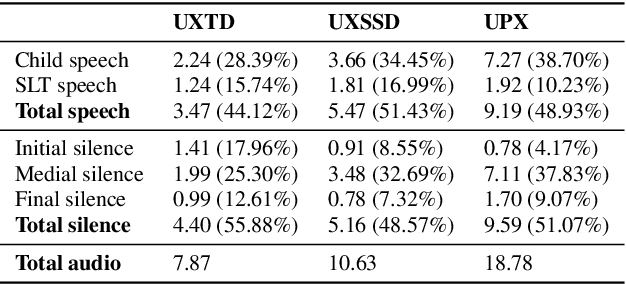
We introduce UltraSuite, a curated repository of ultrasound and acoustic data, collected from recordings of child speech therapy sessions. This release includes three data collections, one from typically developing children and two from children with speech sound disorders. In addition, it includes a set of annotations, some manual and some automatically produced, and software tools to process, transform and visualise the data.
Synchronising audio and ultrasound by learning cross-modal embeddings
Jul 01, 2019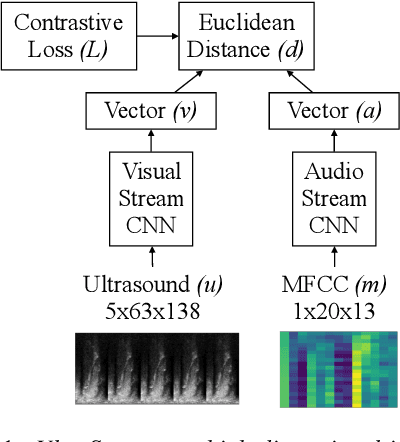
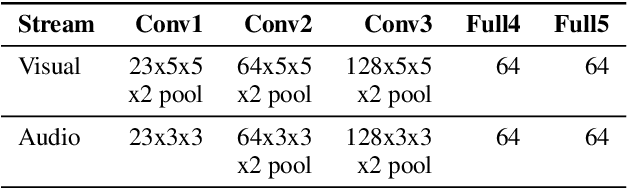
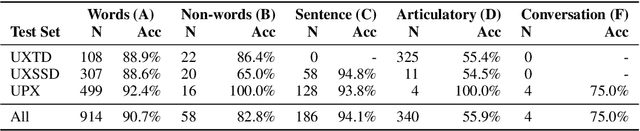
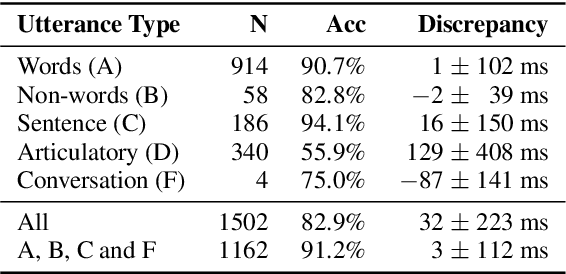
Audiovisual synchronisation is the task of determining the time offset between speech audio and a video recording of the articulators. In child speech therapy, audio and ultrasound videos of the tongue are captured using instruments which rely on hardware to synchronise the two modalities at recording time. Hardware synchronisation can fail in practice, and no mechanism exists to synchronise the signals post hoc. To address this problem, we employ a two-stream neural network which exploits the correlation between the two modalities to find the offset. We train our model on recordings from 69 speakers, and show that it correctly synchronises 82.9% of test utterances from unseen therapy sessions and unseen speakers, thus considerably reducing the number of utterances to be manually synchronised. An analysis of model performance on the test utterances shows that directed phone articulations are more difficult to automatically synchronise compared to utterances containing natural variation in speech such as words, sentences, or conversations.
Speaker-independent classification of phonetic segments from raw ultrasound in child speech
Jul 01, 2019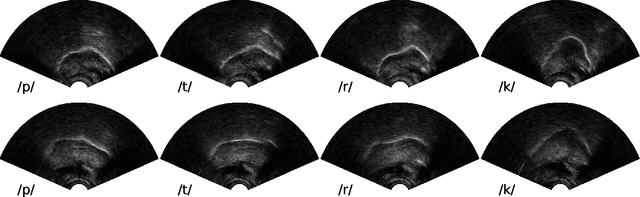
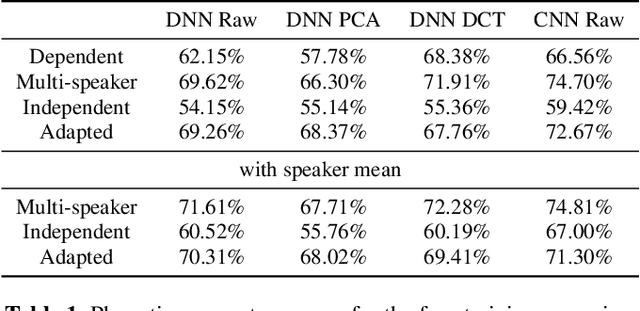

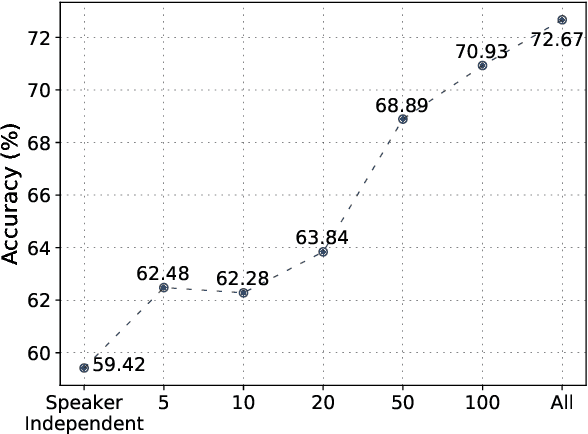
Ultrasound tongue imaging (UTI) provides a convenient way to visualize the vocal tract during speech production. UTI is increasingly being used for speech therapy, making it important to develop automatic methods to assist various time-consuming manual tasks currently performed by speech therapists. A key challenge is to generalize the automatic processing of ultrasound tongue images to previously unseen speakers. In this work, we investigate the classification of phonetic segments (tongue shapes) from raw ultrasound recordings under several training scenarios: speaker-dependent, multi-speaker, speaker-independent, and speaker-adapted. We observe that models underperform when applied to data from speakers not seen at training time. However, when provided with minimal additional speaker information, such as the mean ultrasound frame, the models generalize better to unseen speakers.
Attentive Filtering Networks for Audio Replay Attack Detection
Oct 31, 2018
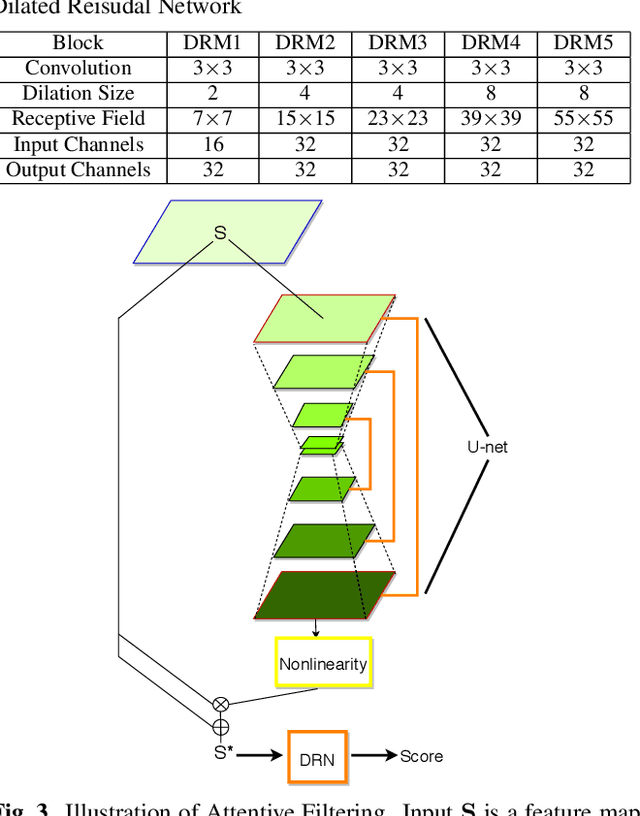
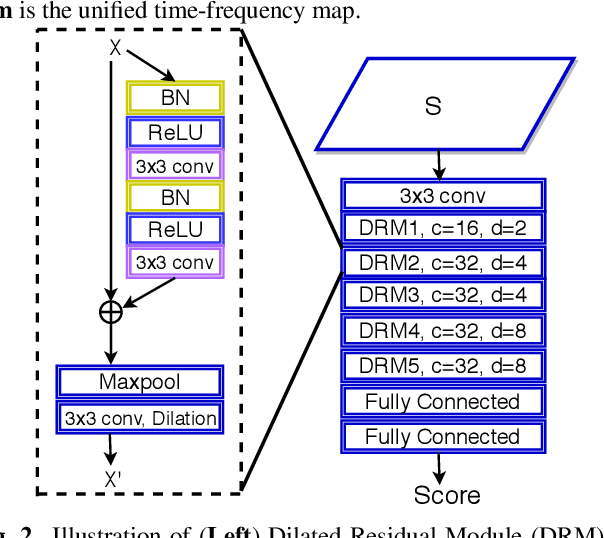
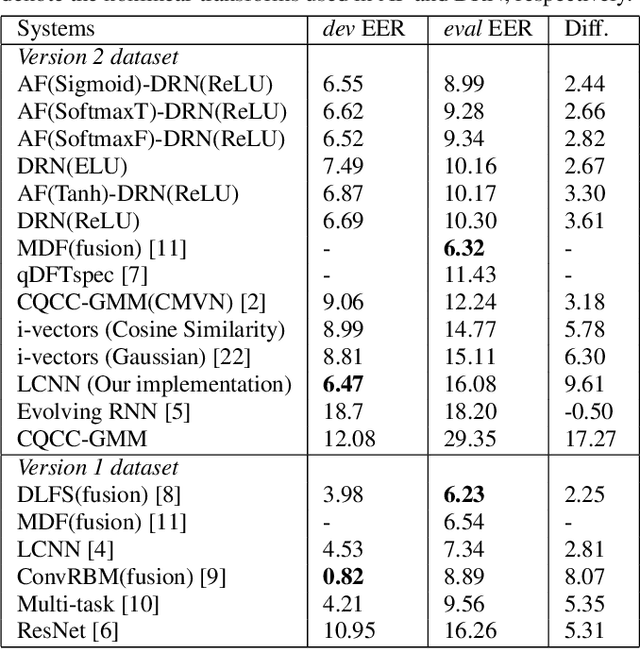
An attacker may use a variety of techniques to fool an automatic speaker verification system into accepting them as a genuine user. Anti-spoofing methods meanwhile aim to make the system robust against such attacks. The ASVspoof 2017 Challenge focused specifically on replay attacks, with the intention of measuring the limits of replay attack detection as well as developing countermeasures against them. In this work, we propose our replay attacks detection system - Attentive Filtering Network, which is composed of an attention-based filtering mechanism that enhances feature representations in both the frequency and time domains, and a ResNet-based classifier. We show that the network enables us to visualize the automatically acquired feature representations that are helpful for spoofing detection. Attentive Filtering Network attains an evaluation EER of 8.99$\%$ on the ASVspoof 2017 Version 2.0 dataset. With system fusion, our best system further obtains a 30$\%$ relative improvement over the ASVspoof 2017 enhanced baseline system.
A Multilinear Tongue Model Derived from Speech Related MRI Data of the Human Vocal Tract
Apr 17, 2018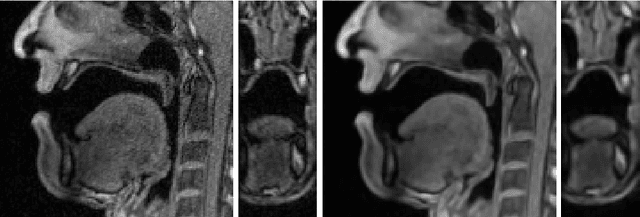
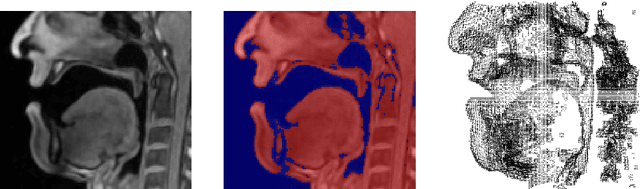
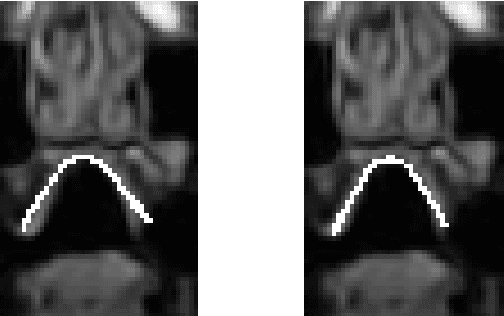
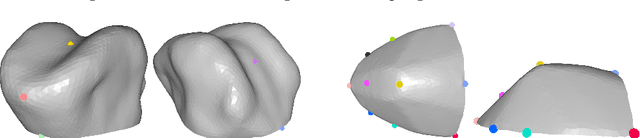
We present a multilinear statistical model of the human tongue that captures anatomical and tongue pose related shape variations separately. The model is derived from 3D magnetic resonance imaging data of 11 speakers sustaining speech related vocal tract configurations. The extraction is performed by using a minimally supervised method that uses as basis an image segmentation approach and a template fitting technique. Furthermore, it uses image denoising to deal with possibly corrupt data, palate surface information reconstruction to handle palatal tongue contacts, and a bootstrap strategy to refine the obtained shapes. Our evaluation concludes that limiting the degrees of freedom for the anatomical and speech related variations to 5 and 4, respectively, produces a model that can reliably register unknown data while avoiding overfitting effects. Furthermore, we show that it can be used to generate a plausible tongue animation by tracking sparse motion capture data.