 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAMOT: Camera Angle-aware Multi-Object Tracking
Sep 26, 2024



This paper proposes CAMOT, a simple camera angle estimator for multi-object tracking to tackle two problems: 1) occlusion and 2) inaccurate distance estimation in the depth direction. Under the assumption that multiple objects are located on a flat plane in each video frame, CAMOT estimates the camera angle using object detection. In addition, it gives the depth of each object, enabling pseudo-3D MOT. We evaluated its performance by adding it to various 2D MOT methods on the MOT17 and MOT20 datasets and confirmed its effectiveness. Applying CAMOT to ByteTrack, we obtained 63.8% HOTA, 80.6% MOTA, and 78.5% IDF1 in MOT17, which are state-of-the-art results. Its computational cost is significantly lower than the existing deep-learning-based depth estimators for tracking.
Pyramid Coder: Hierarchical Code Generator for Compositional Visual Question Answering
Jul 30, 2024Visual question answering (VQA) is the task of providing accurate answers to natural language questions based on visual input. Programmatic VQA (PVQA) models have been gaining attention recently. These use large language models (LLMs) to formulate executable programs that address questions requiring complex visual reasoning. However, there are challenges in enabling LLMs to comprehend the usage of image processing modules and generate relevant code. To overcome these challenges, this paper introduces PyramidCoder, a novel prompting framework for PVQA models. PyramidCoder consists of three hierarchical levels, each serving a distinct purpose: query rephrasing, code generation, and answer aggregation. Notably, PyramidCoder utilizes a single frozen LLM and pre-defined prompts at each level, eliminating the need for additional training and ensuring flexibility across various LLM architectures. Compared to the state-of-the-art PVQA model, our approach improves accuracy by at least 0.5% on the GQA dataset, 1.4% on the VQAv2 dataset, and 2.9% on the NLVR2 dataset.
Implicit Neural Representations for Variable Length Human Motion Generation
Mar 25, 2022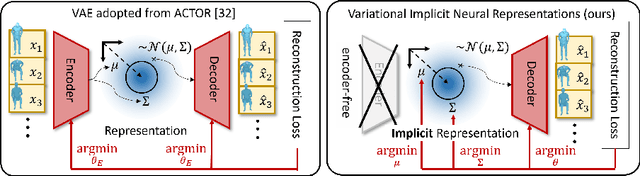
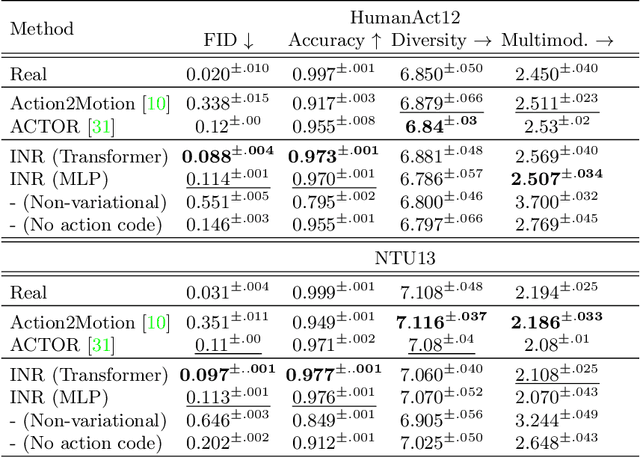
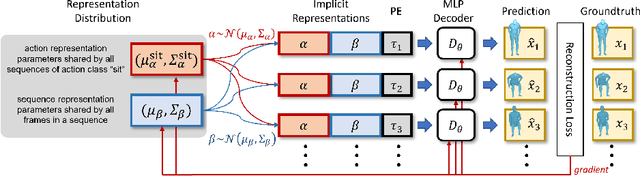

We propose an action-conditional human motion generation method using variational implicit neural representations (INR). The variational formalism enables action-conditional distributions of INRs, from which one can easily sample representations to generate novel human motion sequences. Our method offers variable-length sequence generation by construction because a part of INR is optimized for a whole sequence of arbitrary length with temporal embeddings. In contrast, previous works reported difficulties with modeling variable-length sequences. We confirm that our method with a Transformer decoder outperforms all relevant methods on HumanAct12, NTU-RGBD, and UESTC datasets in terms of realism and diversity of generated motions. Surprisingly, even our method with an MLP decoder consistently outperforms the state-of-the-art Transformer-based auto-encoder. In particular, we show that variable-length motions generated by our method are better than fixed-length motions generated by the state-of-the-art method in terms of realism and diversity.
Neural Architecture Search Using Stable Rank of Convolutional Layers
Sep 19, 2020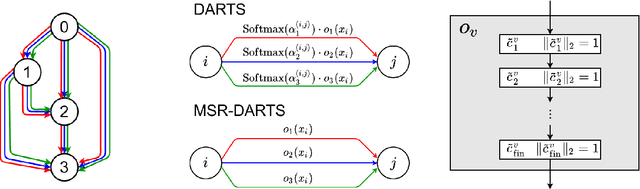
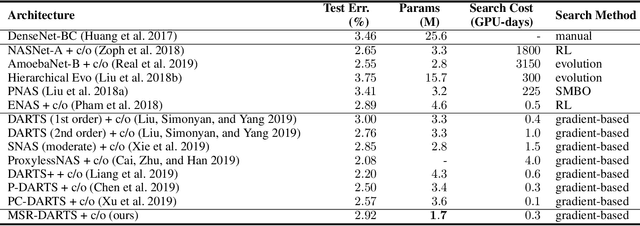
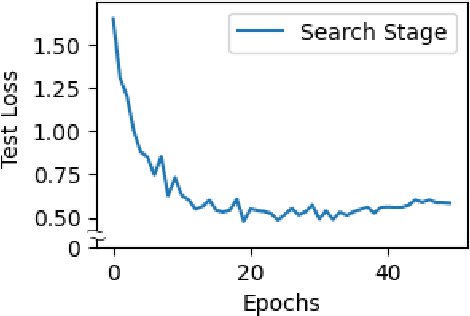

In Neural Architecture Search (NAS), Differentiable ARchiTecture Search (DARTS) has recently attracted much attention due to its high efficiency. It defines an over-parameterized network with mixed edges each of which represents all operator candidates, and jointly optimizes the weights of the network and its architecture in an alternating way. However, this process prefers a model whose weights converge faster than the others, and such a model with fastest convergence often leads to overfitting. Accordingly the resulting model cannot always be well-generalized. To overcome this problem, we propose Minimum Stable Rank DARTS (MSR-DARTS), which aims to find a model with the best generalization error by replacing the architecture optimization with the selection process using the minimum stable rank criterion. Specifically, a convolution operator is represented by a matrix and our method chooses the one whose stable rank is the smallest. We evaluate MSR-DARTS on CIFAR-10 and ImageNet dataset. It achieves an error rate of 2.92% with only 1.7M parameters within 0.5 GPU-days on CIFAR-10, and a top-1 error rate of 24.0% on ImageNet. Our MSR-DARTS directly optimizes an ImageNet model with only 2.6 GPU days while it is often impractical for existing NAS methods to directly optimize a large model such as ImageNet models and hence a proxy dataset such as CIFAR-10 is often utilized.
Speech Paralinguistic Approach for Detecting Dementia Using Gated Convolutional Neural Network
Apr 16, 2020

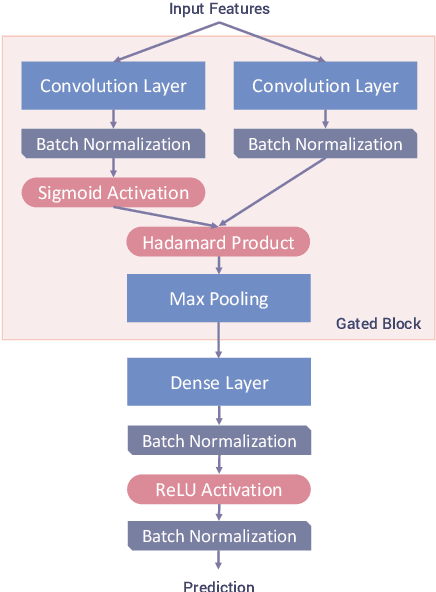
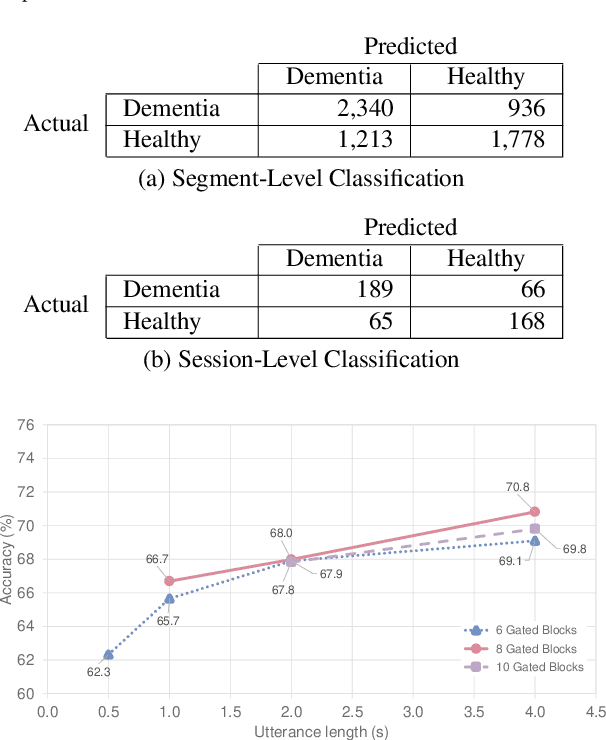
We propose a non-invasive and cost-effective method to automatically detect dementia by utilizing solely speech audio data without any linguistic features. We extract paralinguistic features for a short speech utterance segment and use Gated Convolutional Neural Networks (GCNN) to classify it into dementia or healthy. We evaluate our method by using the Pitt Corpus and our own dataset, the PROMPT Database. Our method yields the accuracy of 73.1% on the Pitt Corpus using an average of 114 seconds of speech data. In the PROMPT Database, our method yields the accuracy of 74.7% using 4 seconds of speech data and it improves to 79.0% when we use 5 minutes of speech data. Furthermore, we evaluate our method on a three-class classification problem in which we included the Mild Cognitive Impairment (MCI) class and achieved the accuracy of 60.6%.
I4U Submission to NIST SRE 2018: Leveraging from a Decade of Shared Experiences
Apr 16, 2019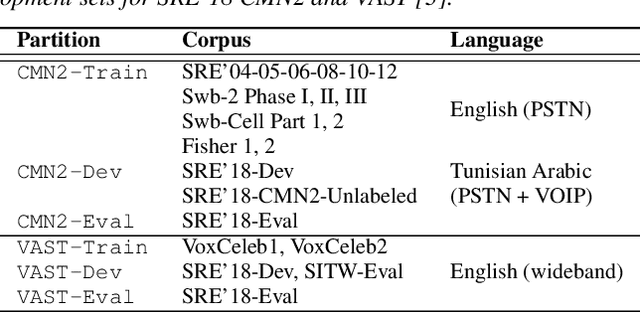
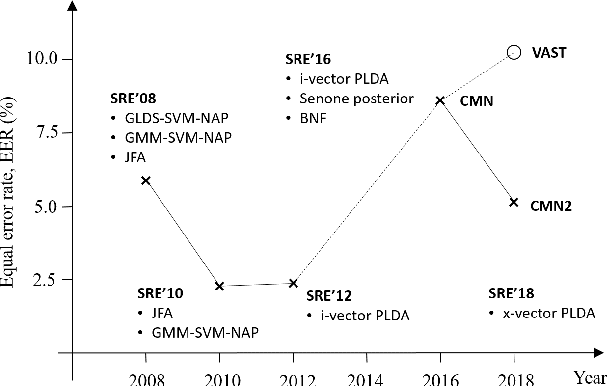
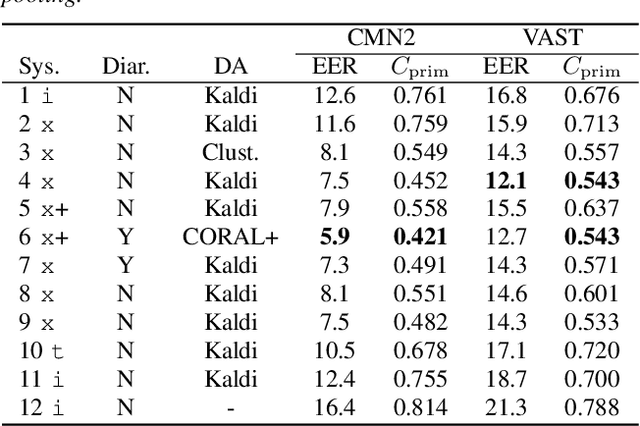
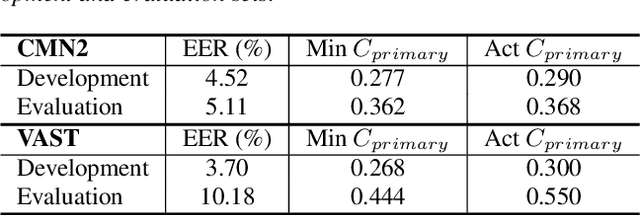
The I4U consortium was established to facilitate a joint entry to NIST speaker recognition evaluations (SRE). The latest edition of such joint submission was in SRE 2018, in which the I4U submission was among the best-performing systems. SRE'18 also marks the 10-year anniversary of I4U consortium into NIST SRE series of evaluation. The primary objective of the current paper is to summarize the results and lessons learned based on the twelve sub-systems and their fusion submitted to SRE'18. It is also our intention to present a shared view on the advancements, progresses, and major paradigm shifts that we have witnessed as an SRE participant in the past decade from SRE'08 to SRE'18. In this regard, we have seen, among others, a paradigm shift from supervector representation to deep speaker embedding, and a switch of research challenge from channel compensation to domain adaptation.
Sequence-Level Knowledge Distillation for Model Compression of Attention-based Sequence-to-Sequence Speech Recognition
Nov 12, 2018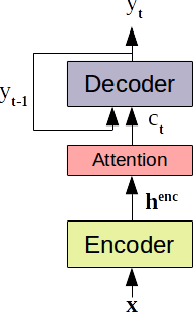

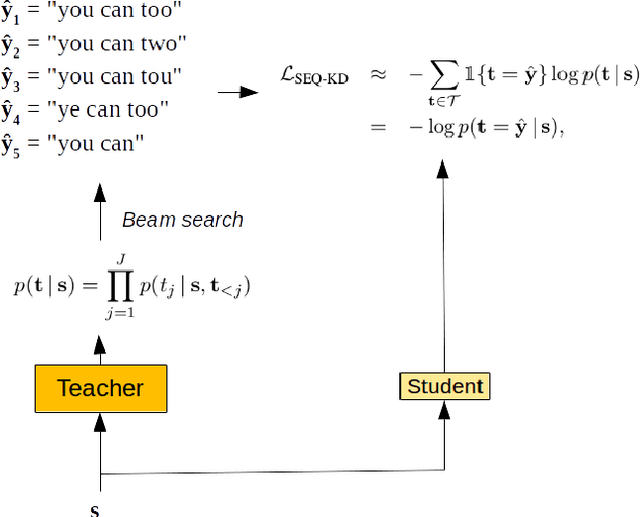
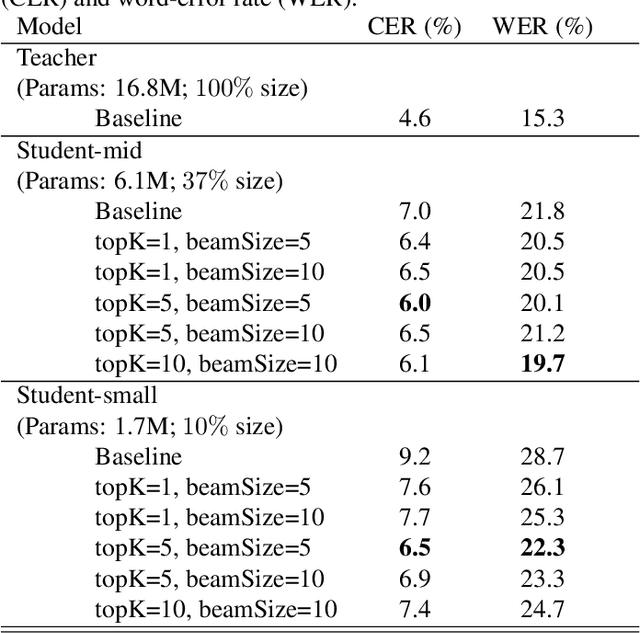
We investigate the feasibility of sequence-level knowledge distillation of Sequence-to-Sequence (Seq2Seq) models for Large Vocabulary Continuous Speech Recognition (LVSCR). We first use a pre-trained larger teacher model to generate multiple hypotheses per utterance with beam search. With the same input, we then train the student model using these hypotheses generated from the teacher as pseudo labels in place of the original ground truth labels. We evaluate our proposed method using Wall Street Journal (WSJ) corpus. It achieved up to $ 9.8 \times$ parameter reduction with accuracy loss of up to 7.0\% word-error rate (WER) increase
Deep Learning Based Multi-modal Addressee Recognition in Visual Scenes with Utterances
Sep 12, 2018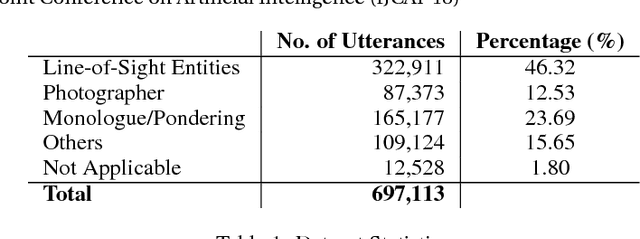

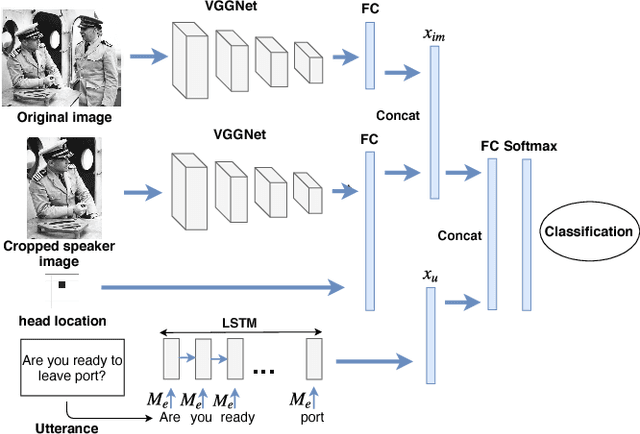
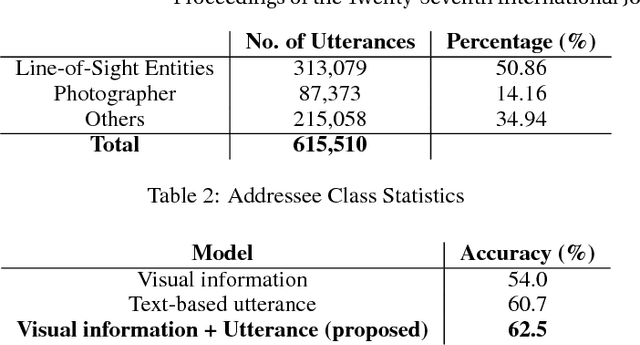
With the widespread use of intelligent systems, such as smart speakers, addressee recognition has become a concern in human-computer interaction, as more and more people expect such systems to understand complicated social scenes, including those outdoors, in cafeterias, and hospitals. Because previous studies typically focused only on pre-specified tasks with limited conversational situations such as controlling smart homes, we created a mock dataset called Addressee Recognition in Visual Scenes with Utterances (ARVSU) that contains a vast body of image variations in visual scenes with an annotated utterance and a corresponding addressee for each scenario. We also propose a multi-modal deep-learning-based model that takes different human cues, specifically eye gazes and transcripts of an utterance corpus, into account to predict the conversational addressee from a specific speaker's view in various real-life conversational scenarios. To the best of our knowledge, we are the first to introduce an end-to-end deep learning model that combines vision and transcripts of utterance for addressee recognition. As a result, our study suggests that future addressee recognition can reach the ability to understand human intention in many social situations previously unexplored, and our modality dataset is a first step in promoting research in this field.
A Fine-to-Coarse Convolutional Neural Network for 3D Human Action Recognition
Aug 18, 2018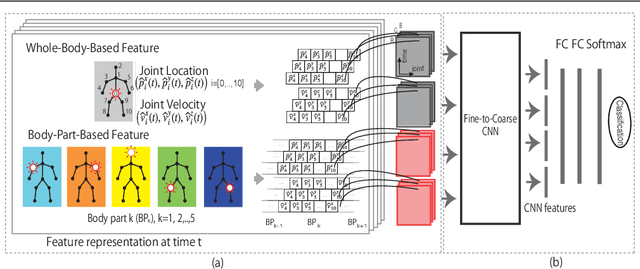
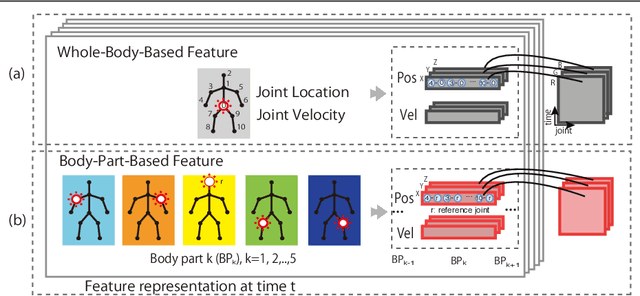
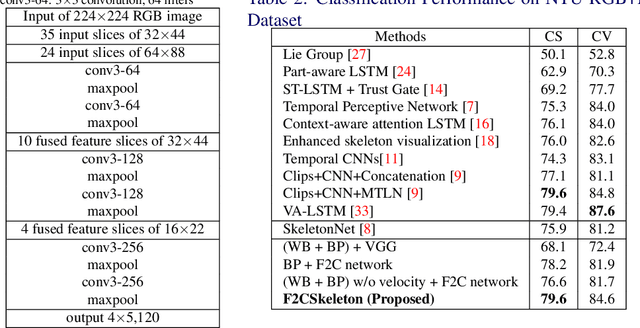
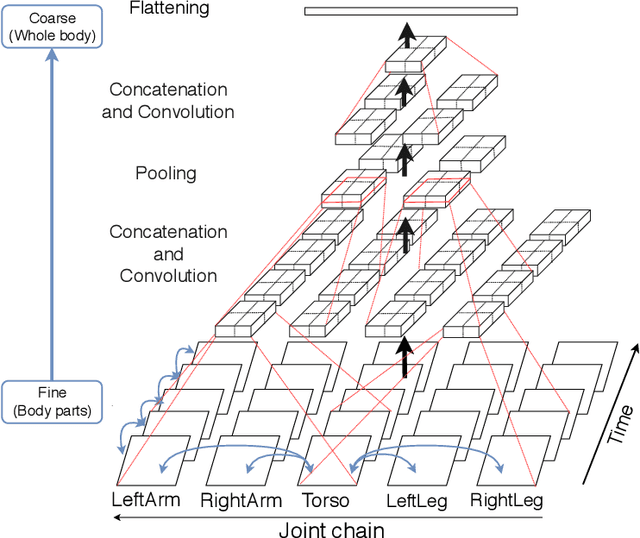
This paper presents a new framework for human action recognition from a 3D skeleton sequence. Previous studies do not fully utilize the temporal relationships between video segments in a human action. Some studies successfully used very deep Convolutional Neural Network (CNN) models but often suffer from the data insufficiency problem. In this study, we first segment a skeleton sequence into distinct temporal segments in order to exploit the correlations between them. The temporal and spatial features of a skeleton sequence are then extracted simultaneously by utilizing a fine-to-coarse (F2C) CNN architecture optimized for human skeleton sequences. We evaluate our proposed method on NTU RGB+D and SBU Kinect Interaction dataset. It achieves 79.6% and 84.6% of accuracies on NTU RGB+D with cross-object and cross-view protocol, respectively, which are almost identical with the state-of-the-art performance. In addition, our method significantly improves the accuracy of the actions in two-person interactions.
Few-Shot Adaptation for Multimedia Semantic Indexing
Jul 19, 2018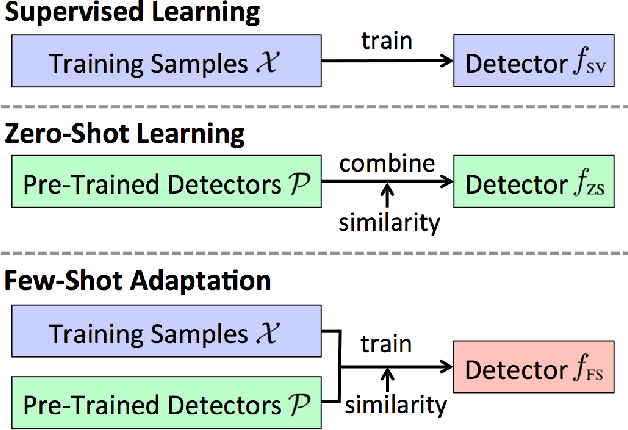
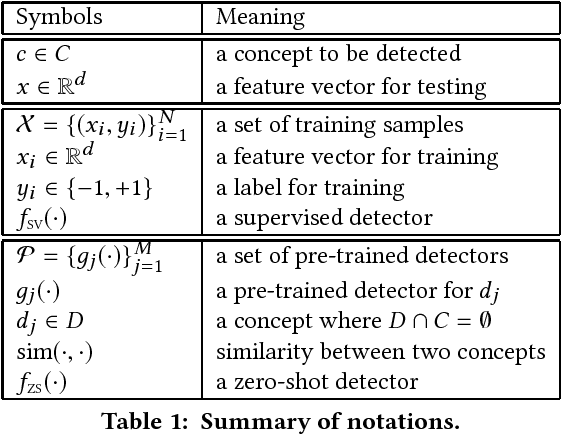

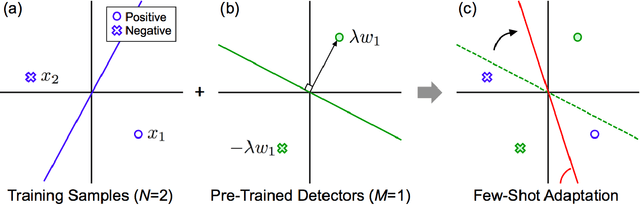
We propose a few-shot adaptation framework, which bridges zero-shot learning and supervised many-shot learning, for semantic indexing of image and video data. Few-shot adaptation provides robust parameter estimation with few training examples, by optimizing the parameters of zero-shot learning and supervised many-shot learning simultaneously. In this method, first we build a zero-shot detector, and then update it by using the few examples. Our experiments show the effectiveness of the proposed framework on three datasets: TRECVID Semantic Indexing 2010, 2014, and ImageNET. On the ImageNET dataset, we show that our method outperforms recent few-shot learning methods. On the TRECVID 2014 dataset, we achieve 15.19% and 35.98% in Mean Average Precision under the zero-shot condition and the supervised condition, respectively. To the best of our knowledge, these are the best results on this dataset.