 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing High-Dimensional Datasets From Their Bivariate Projections
Dec 23, 2023This paper deals with developing techniques for the reconstruction of high-dimensional datasets given each bivariate projection, as would be found in a matrix scatterplot. A graph-based solution is introduced, involving clique-finding, providing a set of possible rows that might make up the original dataset. Complications are discussed, including cases where phantom cliques are found, as well as cases where an exact solution is impossible. Additional methods are shown, with some dealing with fully deducing rows and others dealing with having to creatively produce methods that find some possibilities to be more likely than others. Results show that these methods are highly successful in recreating a significant portion of the original dataset in many cases - for randomly generated and real-world datasets - with the factors leading to a greater rate of failure being lower dimension, higher n, and lower interval.
An Explainable AI Approach to Large Language Model Assisted Causal Model Auditing and Development
Dec 23, 2023Causal networks are widely used in many fields, including epidemiology, social science, medicine, and engineering, to model the complex relationships between variables. While it can be convenient to algorithmically infer these models directly from observational data, the resulting networks are often plagued with erroneous edges. Auditing and correcting these networks may require domain expertise frequently unavailable to the analyst. We propose the use of large language models such as ChatGPT as an auditor for causal networks. Our method presents ChatGPT with a causal network, one edge at a time, to produce insights about edge directionality, possible confounders, and mediating variables. We ask ChatGPT to reflect on various aspects of each causal link and we then produce visualizations that summarize these viewpoints for the human analyst to direct the edge, gather more data, or test further hypotheses. We envision a system where large language models, automated causal inference, and the human analyst and domain expert work hand in hand as a team to derive holistic and comprehensive causal models for any given case scenario. This paper presents first results obtained with an emerging prototype.
DOMINO: Visual Causal Reasoning with Time-Dependent Phenomena
Mar 12, 2023Current work on using visual analytics to determine causal relations among variables has mostly been based on the concept of counterfactuals. As such the derived static causal networks do not take into account the effect of time as an indicator. However, knowing the time delay of a causal relation can be crucial as it instructs how and when actions should be taken. Yet, similar to static causality, deriving causal relations from observational time-series data, as opposed to designed experiments, is not a straightforward process. It can greatly benefit from human insight to break ties and resolve errors. We hence propose a set of visual analytics methods that allow humans to participate in the discovery of causal relations associated with windows of time delay. Specifically, we leverage a well-established method, logic-based causality, to enable analysts to test the significance of potential causes and measure their influences toward a certain effect. Furthermore, since an effect can be a cause of other effects, we allow users to aggregate different temporal cause-effect relations found with our method into a visual flow diagram to enable the discovery of temporal causal networks. To demonstrate the effectiveness of our methods we constructed a prototype system named DOMINO and showcase it via a number of case studies using real-world datasets. Finally, we also used DOMINO to conduct several evaluations with human analysts from different science domains in order to gain feedback on the utility of our system in practical scenarios.
Improving CT Image Segmentation Accuracy Using StyleGAN Driven Data Augmentation
Feb 07, 2023Medical Image Segmentation is a useful application for medical image analysis including detecting diseases and abnormalities in imaging modalities such as MRI, CT etc. Deep learning has proven to be promising for this task but usually has a low accuracy because of the lack of appropriate publicly available annotated or segmented medical datasets. In addition, the datasets that are available may have a different texture because of different dosage values or scanner properties than the images that need to be segmented. This paper presents a StyleGAN-driven approach for segmenting publicly available large medical datasets by using readily available extremely small annotated datasets in similar modalities. The approach involves augmenting the small segmented dataset and eliminating texture differences between the two datasets. The dataset is augmented by being passed through six different StyleGANs that are trained on six different style images taken from the large non-annotated dataset we want to segment. Specifically, style transfer is used to augment the training dataset. The annotations of the training dataset are hence combined with the textures of the non-annotated dataset to generate new anatomically sound images. The augmented dataset is then used to train a U-Net segmentation network which displays a significant improvement in the segmentation accuracy in segmenting the large non-annotated dataset.
Using Large Language Models to Generate Engaging Captions for Data Visualizations
Dec 27, 2022



Creating compelling captions for data visualizations has been a longstanding challenge. Visualization researchers are typically untrained in journalistic reporting and hence the captions that are placed below data visualizations tend to be not overly engaging and rather just stick to basic observations about the data. In this work we explore the opportunities offered by the newly emerging crop of large language models (LLM) which use sophisticated deep learning technology to produce human-like prose. We ask, can these powerful software devices be purposed to produce engaging captions for generic data visualizations like a scatterplot. It turns out that the key challenge lies in designing the most effective prompt for the LLM, a task called prompt engineering. We report on first experiments using the popular LLM GPT-3 and deliver some promising results.
D-BIAS: A Causality-Based Human-in-the-Loop System for Tackling Algorithmic Bias
Aug 10, 2022
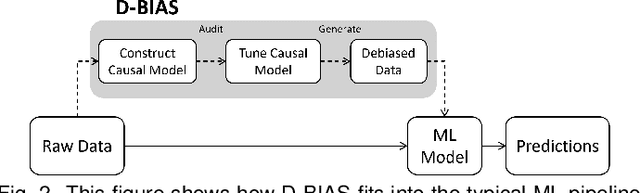

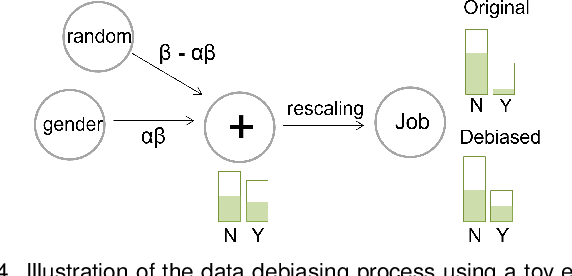
With the rise of AI, algorithms have become better at learning underlying patterns from the training data including ingrained social biases based on gender, race, etc. Deployment of such algorithms to domains such as hiring, healthcare, law enforcement, etc. has raised serious concerns about fairness, accountability, trust and interpretability in machine learning algorithms. To alleviate this problem, we propose D-BIAS, a visual interactive tool that embodies human-in-the-loop AI approach for auditing and mitigating social biases from tabular datasets. It uses a graphical causal model to represent causal relationships among different features in the dataset and as a medium to inject domain knowledge. A user can detect the presence of bias against a group, say females, or a subgroup, say black females, by identifying unfair causal relationships in the causal network and using an array of fairness metrics. Thereafter, the user can mitigate bias by acting on the unfair causal edges. For each interaction, say weakening/deleting a biased causal edge, the system uses a novel method to simulate a new (debiased) dataset based on the current causal model. Users can visually assess the impact of their interactions on different fairness metrics, utility metrics, data distortion, and the underlying data distribution. Once satisfied, they can download the debiased dataset and use it for any downstream application for fairer predictions. We evaluate D-BIAS by conducting experiments on 3 datasets and also a formal user study. We found that D-BIAS helps reduce bias significantly compared to the baseline debiasing approach across different fairness metrics while incurring little data distortion and a small loss in utility. Moreover, our human-in-the-loop based approach significantly outperforms an automated approach on trust, interpretability and accountability.
An Open Source Interactive Visual Analytics Tool for Comparative Programming Comprehension
Jul 29, 2022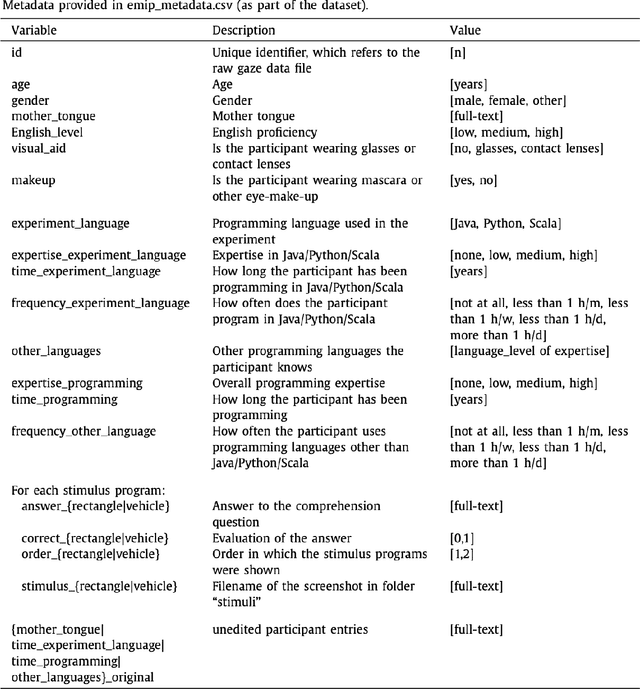



This paper proposes an open source visual analytics tool consisting of several views and perspectives on eye movement data collected during code reading tasks when writing computer programs. Hence the focus of this work is on code and program comprehension. The source code is shown as a visual stimulus. It can be inspected in combination with overlaid scanpaths in which the saccades can be visually encoded in several forms, including straight, curved, and orthogonal lines, modifiable by interaction techniques. The tool supports interaction techniques like filter functions, aggregations, data sampling, and many more. We illustrate the usefulness of our tool by applying it to the eye movements of 216 programmers of multiple expertise levels that were collected during two code comprehension tasks. Our tool helped to analyze the difference between the strategic program comprehension of programmers based on their demographic background, time taken to complete the task, choice of programming task, and expertise.
Infographics Wizard: Flexible Infographics Authoring and Design Exploration
Apr 21, 2022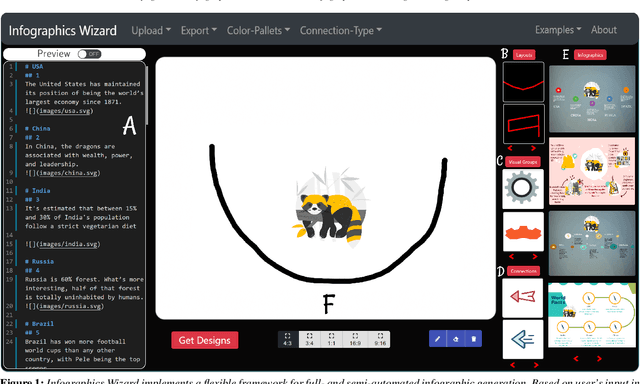
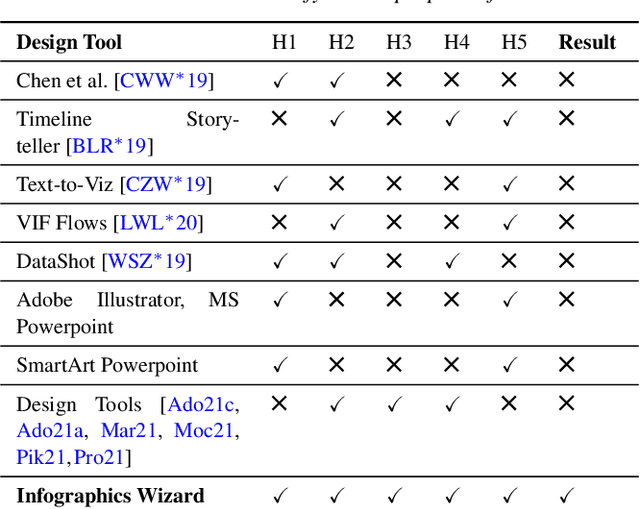
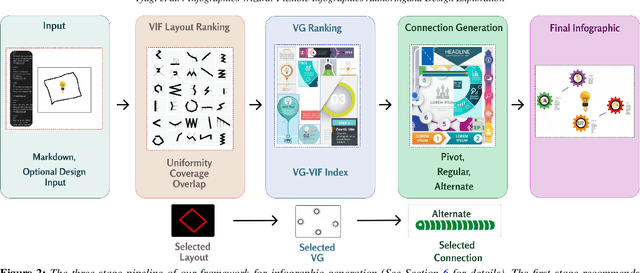
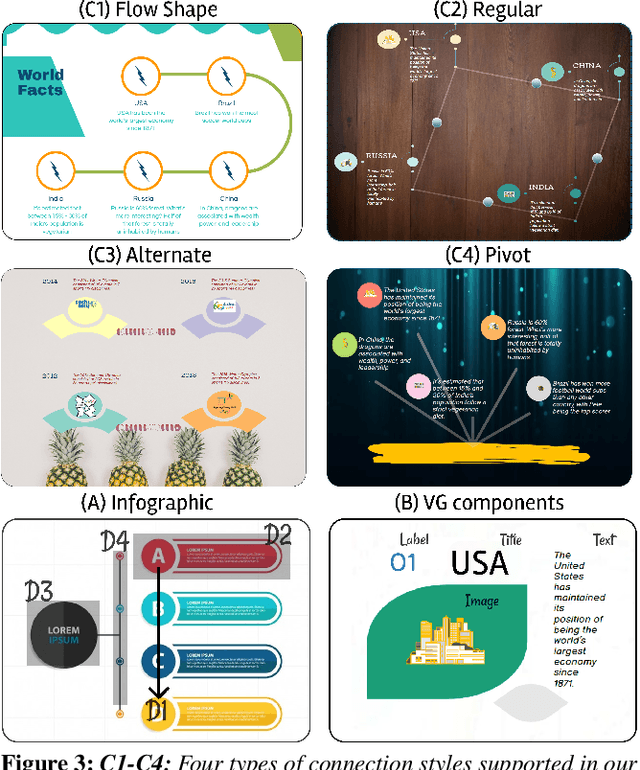
Infographics are an aesthetic visual representation of information following specific design principles of human perception. Designing infographics can be a tedious process for non-experts and time-consuming, even for professional designers. With the help of designers, we propose a semi-automated infographic framework for general structured and flow-based infographic design generation. For novice designers, our framework automatically creates and ranks infographic designs for a user-provided text with no requirement for design input. However, expert designers can still provide custom design inputs to customize the infographics. We will also contribute an individual visual group (VG) designs dataset (in SVG), along with a 1k complete infographic image dataset with segmented VGs in this work. Evaluation results confirm that by using our framework, designers from all expertise levels can generate generic infographic designs faster than existing methods while maintaining the same quality as hand-designed infographics templates.
Cascaded Debiasing : Studying the Cumulative Effect of Multiple Fairness-Enhancing Interventions
Feb 08, 2022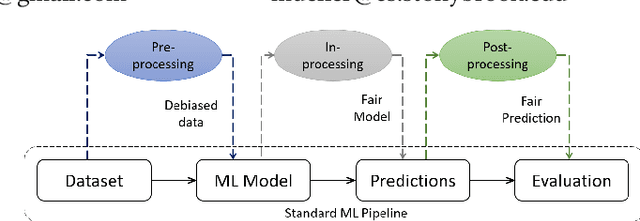
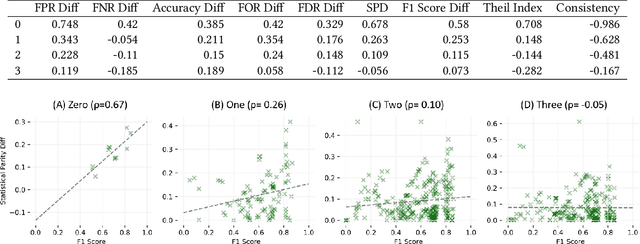

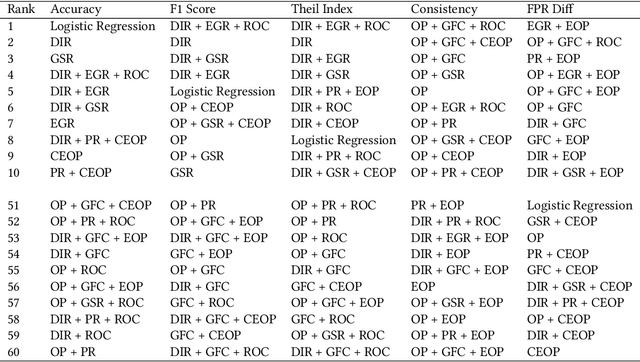
Understanding the cumulative effect of multiple fairness enhancing interventions at different stages of the machine learning (ML) pipeline is a critical and underexplored facet of the fairness literature. Such knowledge can be valuable to data scientists/ML practitioners in designing fair ML pipelines. This paper takes the first step in exploring this area by undertaking an extensive empirical study comprising 60 combinations of interventions, 9 fairness metrics, 2 utility metrics (Accuracy and F1 Score) across 4 benchmark datasets. We quantitatively analyze the experimental data to measure the impact of multiple interventions on fairness, utility and population groups. We found that applying multiple interventions results in better fairness and lower utility than individual interventions on aggregate. However, adding more interventions do no always result in better fairness or worse utility. The likelihood of achieving high performance (F1 Score) along with high fairness increases with larger number of interventions. On the downside, we found that fairness-enhancing interventions can negatively impact different population groups, especially the privileged group. This study highlights the need for new fairness metrics that account for the impact on different population groups apart from just the disparity between groups. Lastly, we offer a list of combinations of interventions that perform best for different fairness and utility metrics to aid the design of fair ML pipelines.
User-Centric Semi-Automated Infographics Authoring and Recommendation
Aug 27, 2021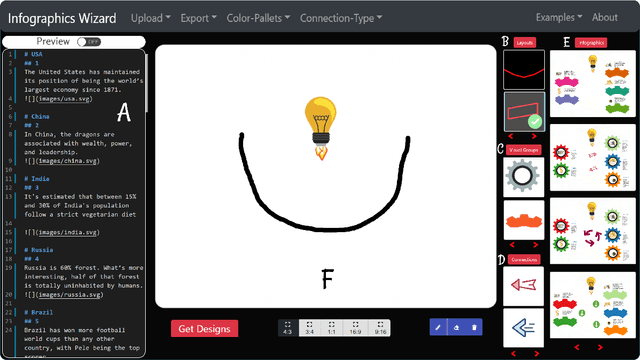



Designing infographics can be a tedious process for non-experts and time-consuming even for professional designers. Based on the literature and a formative study, we propose a flexible framework for automated and semi-automated infographics design. This framework captures the main design components in infographics and streamlines the generation workflow into three steps, allowing users to control and optimize each aspect independently. Based on the framework, we also propose an interactive tool, \name{}, for assisting novice designers with creating high-quality infographics from an input in a markdown format by offering recommendations of different design components of infographics. Simultaneously, more experienced designers can provide custom designs and layout ideas to the tool using a canvas to control the automated generation process partially. As part of our work, we also contribute an individual visual group (VG) and connection designs dataset (in SVG), along with a 1k complete infographic image dataset with segmented VGs. This dataset plays a crucial role in diversifying the infographic designs created by our framework. We evaluate our approach with a comparison against similar tools, a user study with novice and expert designers, and a case study. Results confirm that our framework and \name{} excel in creating customized infographics and exploring a large variety of designs.