 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Object Representation Learning with Iterative Variational Inference
Mar 01, 2019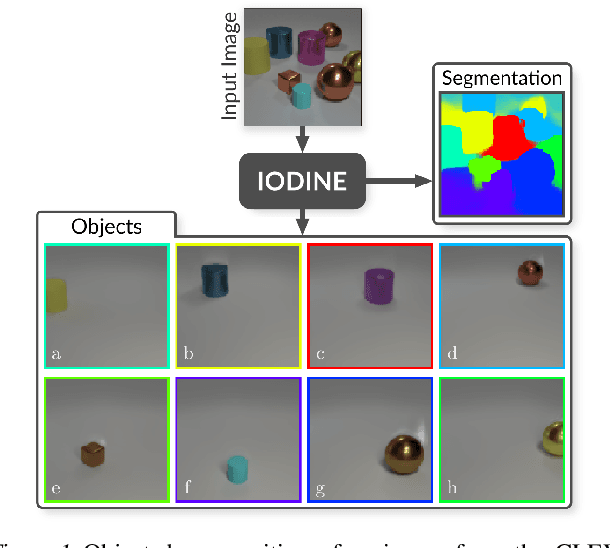

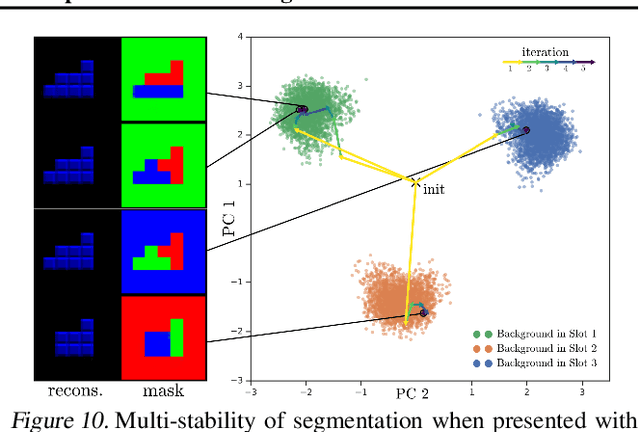

Human perception is structured around objects which form the basis for our higher-level cognition and impressive systematic generalization abilities. Yet most work on representation learning focuses on feature learning without even considering multiple objects, or treats segmentation as an (often supervised) preprocessing step. Instead, we argue for the importance of learning to segment and represent objects jointly. We demonstrate that, starting from the simple assumption that a scene is composed of multiple entities, it is possible to learn to segment images into interpretable objects with disentangled representations. Our method learns -- without supervision -- to inpaint occluded parts, and extrapolates to scenes with more objects and to unseen objects with novel feature combinations. We also show that, due to the use of iterative variational inference, our system is able to learn multi-modal posteriors for ambiguous inputs and extends naturally to sequences.
Relational Neural Expectation Maximization: Unsupervised Discovery of Objects and their Interactions
Feb 28, 2018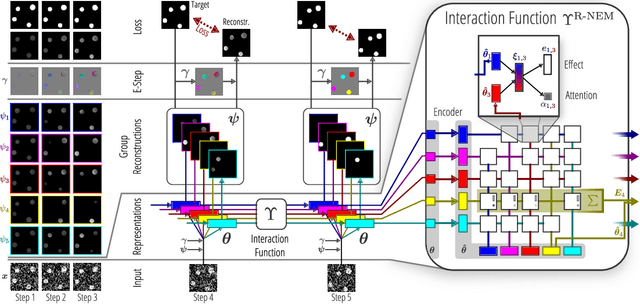

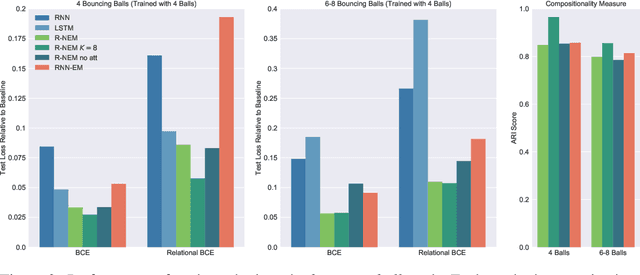

Common-sense physical reasoning is an essential ingredient for any intelligent agent operating in the real-world. For example, it can be used to simulate the environment, or to infer the state of parts of the world that are currently unobserved. In order to match real-world conditions this causal knowledge must be learned without access to supervised data. To address this problem we present a novel method that learns to discover objects and model their physical interactions from raw visual images in a purely \emph{unsupervised} fashion. It incorporates prior knowledge about the compositional nature of human perception to factor interactions between object-pairs and learn efficiently. On videos of bouncing balls we show the superior modelling capabilities of our method compared to other unsupervised neural approaches that do not incorporate such prior knowledge. We demonstrate its ability to handle occlusion and show that it can extrapolate learned knowledge to scenes with different numbers of objects.
Neural Expectation Maximization
Nov 04, 2017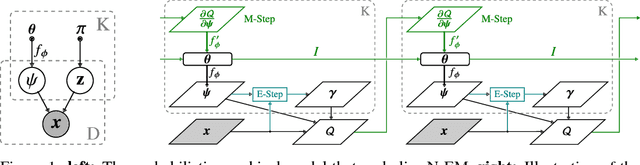

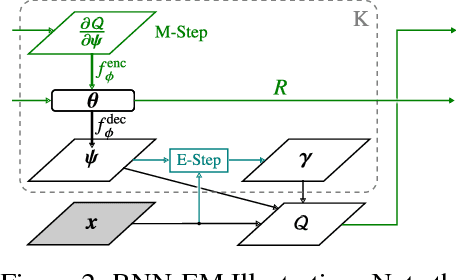

Many real world tasks such as reasoning and physical interaction require identification and manipulation of conceptual entities. A first step towards solving these tasks is the automated discovery of distributed symbol-like representations. In this paper, we explicitly formalize this problem as inference in a spatial mixture model where each component is parametrized by a neural network. Based on the Expectation Maximization framework we then derive a differentiable clustering method that simultaneously learns how to group and represent individual entities. We evaluate our method on the (sequential) perceptual grouping task and find that it is able to accurately recover the constituent objects. We demonstrate that the learned representations are useful for next-step prediction.
LSTM: A Search Space Odyssey
Oct 04, 2017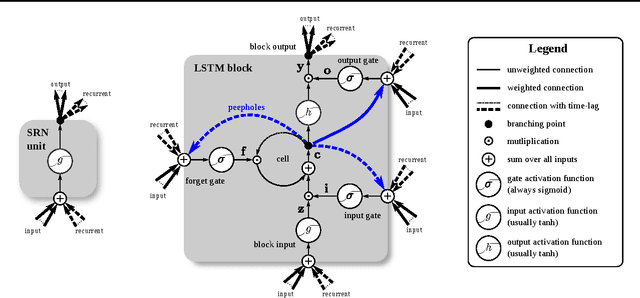
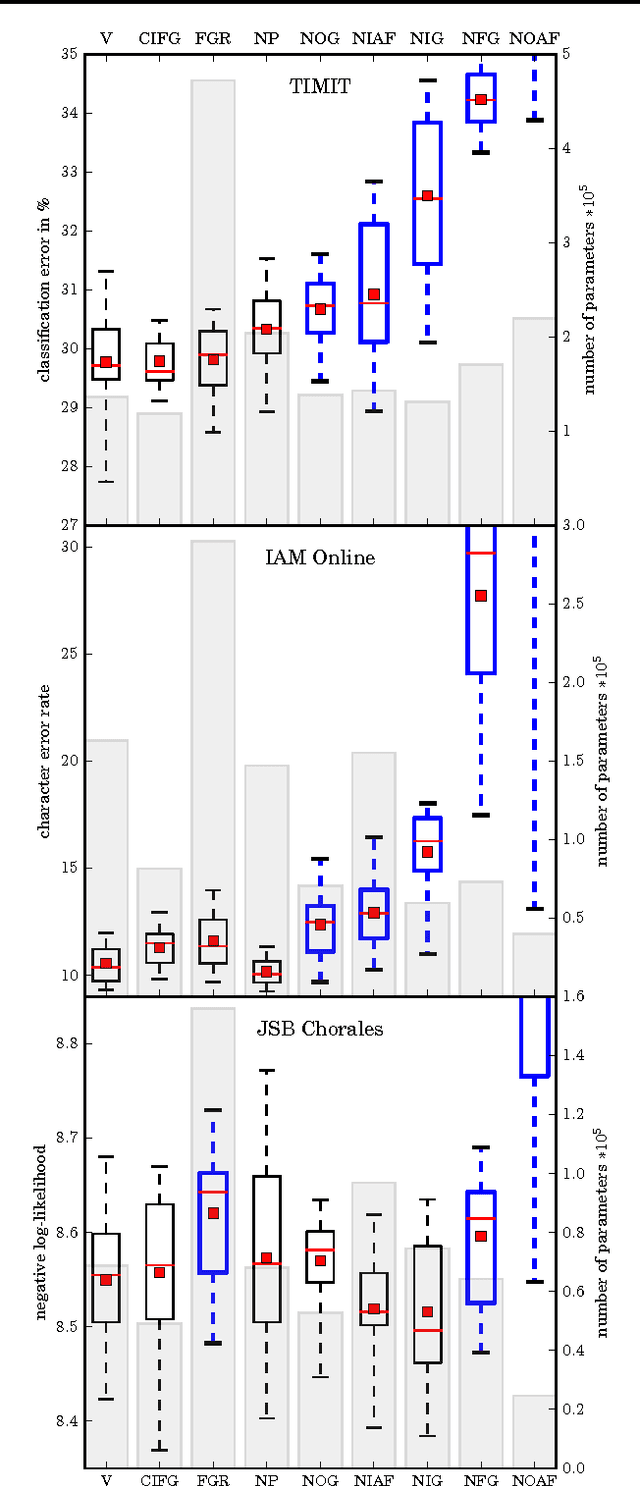
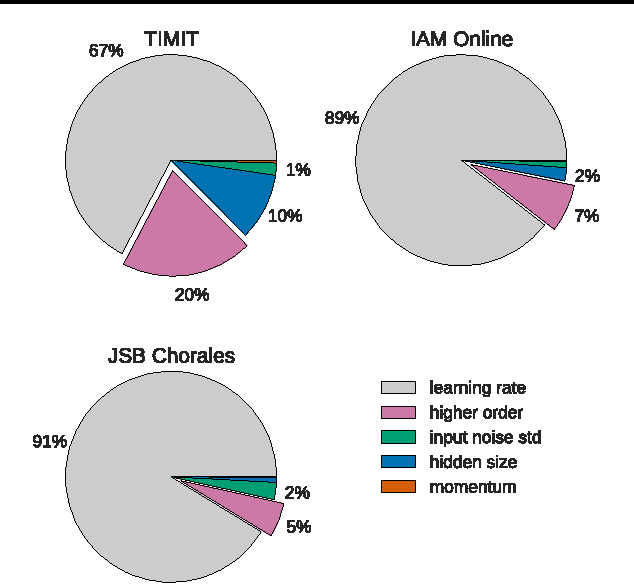
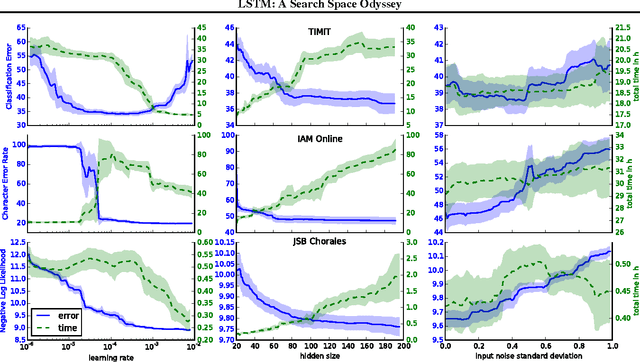
Several variants of the Long Short-Term Memory (LSTM) architecture for recurrent neural networks have been proposed since its inception in 1995. In recent years, these networks have become the state-of-the-art models for a variety of machine learning problems. This has led to a renewed interest in understanding the role and utility of various computational components of typical LSTM variants. In this paper, we present the first large-scale analysis of eight LSTM variants on three representative tasks: speech recognition, handwriting recognition, and polyphonic music modeling. The hyperparameters of all LSTM variants for each task were optimized separately using random search, and their importance was assessed using the powerful fANOVA framework. In total, we summarize the results of 5400 experimental runs ($\approx 15$ years of CPU time), which makes our study the largest of its kind on LSTM networks. Our results show that none of the variants can improve upon the standard LSTM architecture significantly, and demonstrate the forget gate and the output activation function to be its most critical components. We further observe that the studied hyperparameters are virtually independent and derive guidelines for their efficient adjustment.
* 12 pages, 6 figures
Highway and Residual Networks learn Unrolled Iterative Estimation
Mar 14, 2017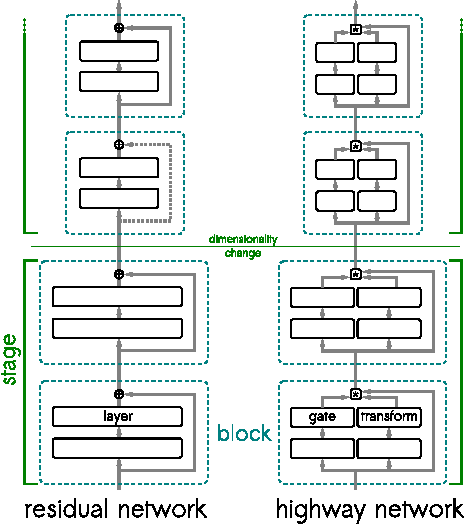

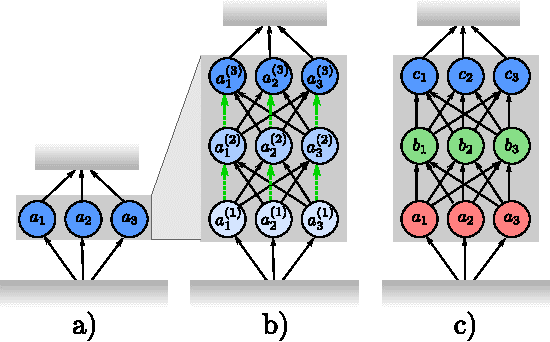
The past year saw the introduction of new architectures such as Highway networks and Residual networks which, for the first time, enabled the training of feedforward networks with dozens to hundreds of layers using simple gradient descent. While depth of representation has been posited as a primary reason for their success, there are indications that these architectures defy a popular view of deep learning as a hierarchical computation of increasingly abstract features at each layer. In this report, we argue that this view is incomplete and does not adequately explain several recent findings. We propose an alternative viewpoint based on unrolled iterative estimation -- a group of successive layers iteratively refine their estimates of the same features instead of computing an entirely new representation. We demonstrate that this viewpoint directly leads to the construction of Highway and Residual networks. Finally we provide preliminary experiments to discuss the similarities and differences between the two architectures.
Tagger: Deep Unsupervised Perceptual Grouping
Nov 28, 2016

We present a framework for efficient perceptual inference that explicitly reasons about the segmentation of its inputs and features. Rather than being trained for any specific segmentation, our framework learns the grouping process in an unsupervised manner or alongside any supervised task. By enriching the representations of a neural network, we enable it to group the representations of different objects in an iterative manner. By allowing the system to amortize the iterative inference of the groupings, we achieve very fast convergence. In contrast to many other recently proposed methods for addressing multi-object scenes, our system does not assume the inputs to be images and can therefore directly handle other modalities. For multi-digit classification of very cluttered images that require texture segmentation, our method offers improved classification performance over convolutional networks despite being fully connected. Furthermore, we observe that our system greatly improves on the semi-supervised result of a baseline Ladder network on our dataset, indicating that segmentation can also improve sample efficiency.
Scalable Gradient-Based Tuning of Continuous Regularization Hyperparameters
Jun 17, 2016
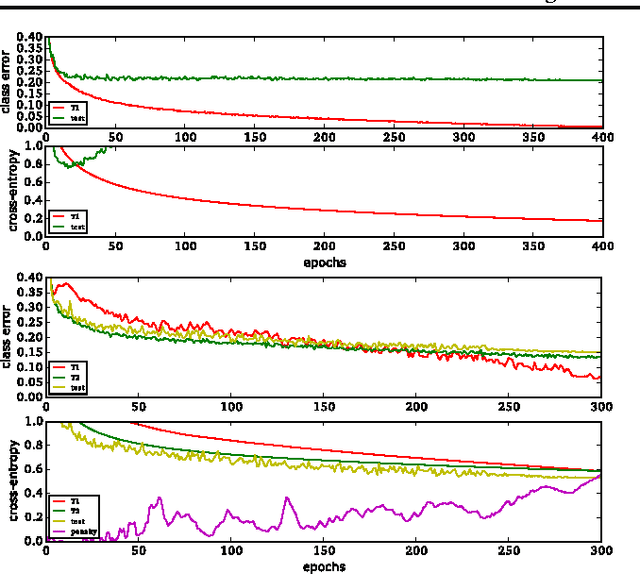
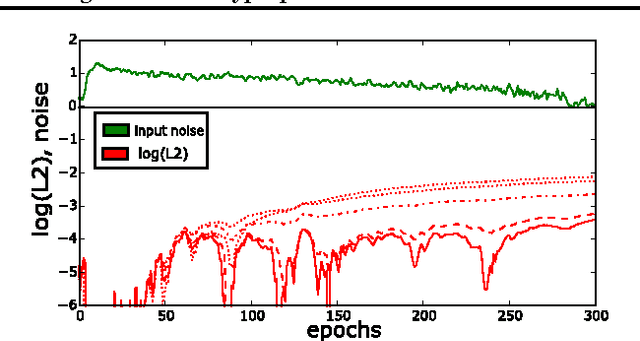
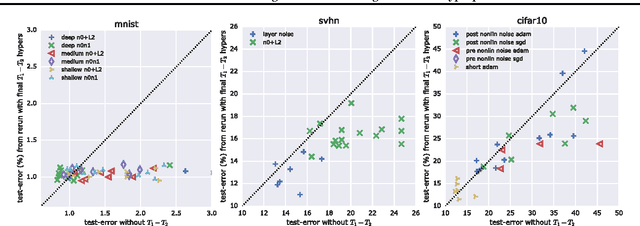
Hyperparameter selection generally relies on running multiple full training trials, with selection based on validation set performance. We propose a gradient-based approach for locally adjusting hyperparameters during training of the model. Hyperparameters are adjusted so as to make the model parameter gradients, and hence updates, more advantageous for the validation cost. We explore the approach for tuning regularization hyperparameters and find that in experiments on MNIST, SVHN and CIFAR-10, the resulting regularization levels are within the optimal regions. The additional computational cost depends on how frequently the hyperparameters are trained, but the tested scheme adds only 30% computational overhead regardless of the model size. Since the method is significantly less computationally demanding compared to similar gradient-based approaches to hyperparameter optimization, and consistently finds good hyperparameter values, it can be a useful tool for training neural network models.
Binding via Reconstruction Clustering
Jan 20, 2016

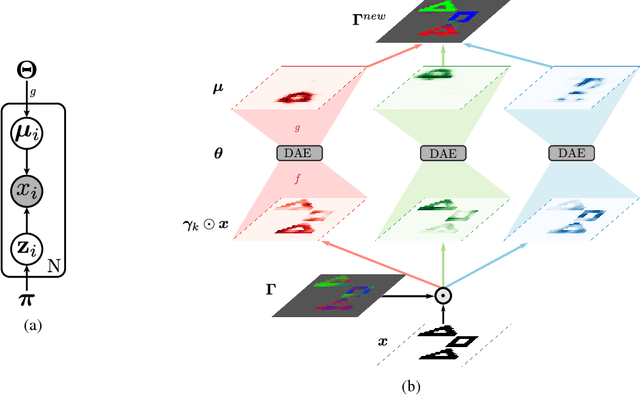

Disentangled distributed representations of data are desirable for machine learning, since they are more expressive and can generalize from fewer examples. However, for complex data, the distributed representations of multiple objects present in the same input can interfere and lead to ambiguities, which is commonly referred to as the binding problem. We argue for the importance of the binding problem to the field of representation learning, and develop a probabilistic framework that explicitly models inputs as a composition of multiple objects. We propose an unsupervised algorithm that uses denoising autoencoders to dynamically bind features together in multi-object inputs through an Expectation-Maximization-like clustering process. The effectiveness of this method is demonstrated on artificially generated datasets of binary images, showing that it can even generalize to bind together new objects never seen by the autoencoder during training.
Training Very Deep Networks
Nov 23, 2015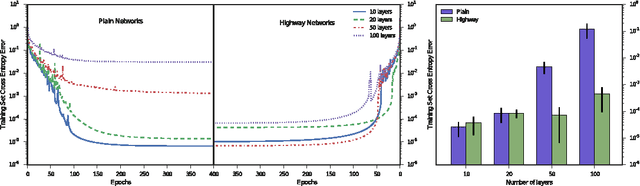


Theoretical and empirical evidence indicates that the depth of neural networks is crucial for their success. However, training becomes more difficult as depth increases, and training of very deep networks remains an open problem. Here we introduce a new architecture designed to overcome this. Our so-called highway networks allow unimpeded information flow across many layers on information highways. They are inspired by Long Short-Term Memory recurrent networks and use adaptive gating units to regulate the information flow. Even with hundreds of layers, highway networks can be trained directly through simple gradient descent. This enables the study of extremely deep and efficient architectures.
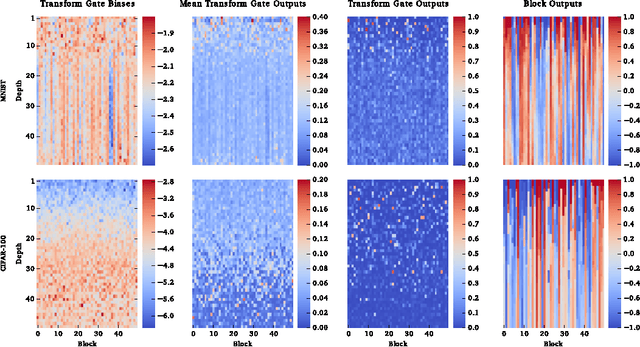
Highway Networks
Nov 03, 2015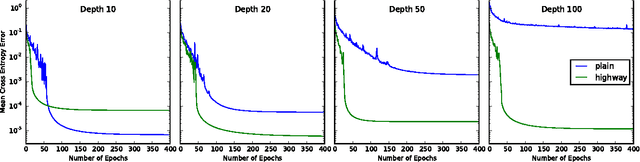
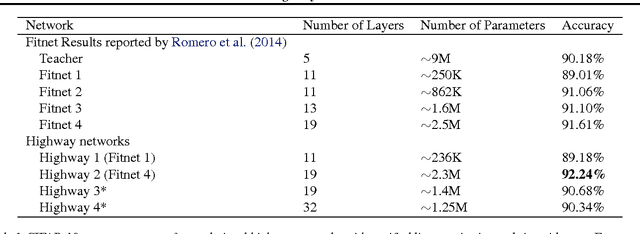
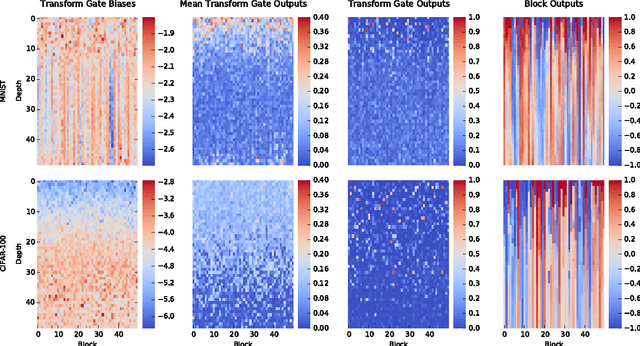
There is plenty of theoretical and empirical evidence that depth of neural networks is a crucial ingredient for their success. However, network training becomes more difficult with increasing depth and training of very deep networks remains an open problem. In this extended abstract, we introduce a new architecture designed to ease gradient-based training of very deep networks. We refer to networks with this architecture as highway networks, since they allow unimpeded information flow across several layers on "information highways". The architecture is characterized by the use of gating units which learn to regulate the flow of information through a network. Highway networks with hundreds of layers can be trained directly using stochastic gradient descent and with a variety of activation functions, opening up the possibility of studying extremely deep and efficient architectures.