 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiframe Scene Flow with Piecewise Rigid Motion
Oct 05, 2017



We introduce a novel multiframe scene flow approach that jointly optimizes the consistency of the patch appearances and their local rigid motions from RGB-D image sequences. In contrast to the competing methods, we take advantage of an oversegmentation of the reference frame and robust optimization techniques. We formulate scene flow recovery as a global non-linear least squares problem which is iteratively solved by a damped Gauss-Newton approach. As a result, we obtain a qualitatively new level of accuracy in RGB-D based scene flow estimation which can potentially run in real-time. Our method can handle challenging cases with rigid, piecewise rigid, articulated and moderate non-rigid motion, and does not rely on prior knowledge about the types of motions and deformations. Extensive experiments on synthetic and real data show that our method outperforms state-of-the-art.
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting
Aug 04, 2017
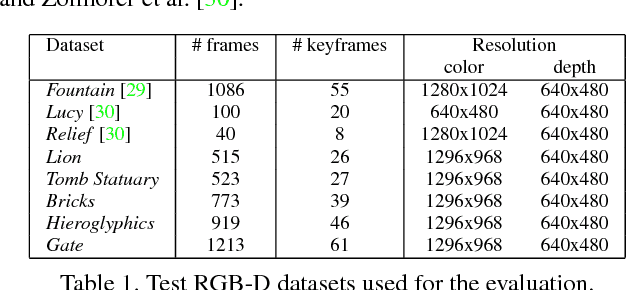

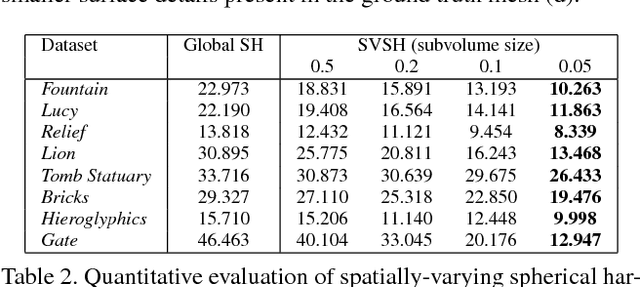
We introduce a novel method to obtain high-quality 3D reconstructions from consumer RGB-D sensors. Our core idea is to simultaneously optimize for geometry encoded in a signed distance field (SDF), textures from automatically-selected keyframes, and their camera poses along with material and scene lighting. To this end, we propose a joint surface reconstruction approach that is based on Shape-from-Shading (SfS) techniques and utilizes the estimation of spatially-varying spherical harmonics (SVSH) from subvolumes of the reconstructed scene. Through extensive examples and evaluations, we demonstrate that our method dramatically increases the level of detail in the reconstructed scene geometry and contributes highly to consistent surface texture recovery.