 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Important is Importance Sampling for Deep Budgeted Training?
Oct 27, 2021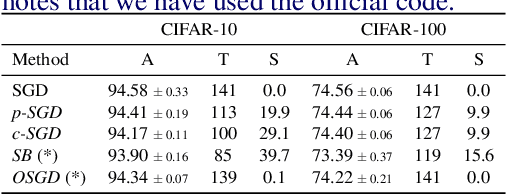
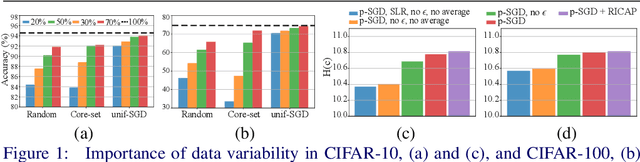
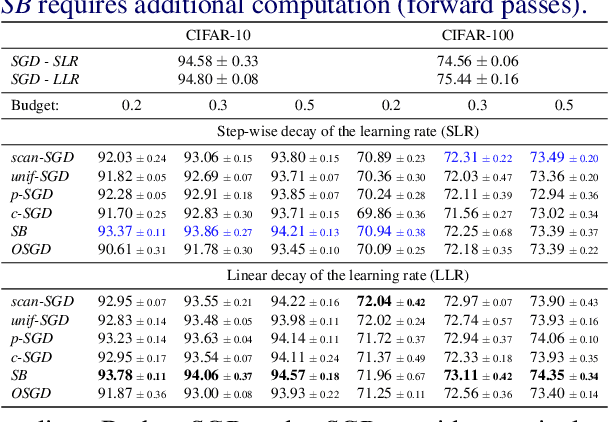
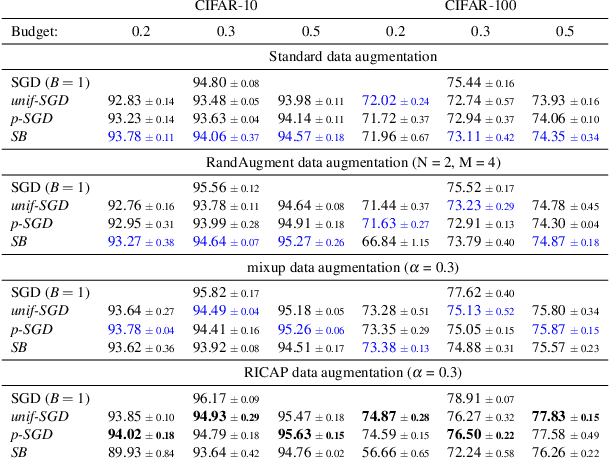
Long iterative training processes for Deep Neural Networks (DNNs) are commonly required to achieve state-of-the-art performance in many computer vision tasks. Importance sampling approaches might play a key role in budgeted training regimes, i.e. when limiting the number of training iterations. These approaches aim at dynamically estimating the importance of each sample to focus on the most relevant and speed up convergence. This work explores this paradigm and how a budget constraint interacts with importance sampling approaches and data augmentation techniques. We show that under budget restrictions, importance sampling approaches do not provide a consistent improvement over uniform sampling. We suggest that, given a specific budget, the best course of action is to disregard the importance and introduce adequate data augmentation; e.g. when reducing the budget to a 30% in CIFAR-10/100, RICAP data augmentation maintains accuracy, while importance sampling does not. We conclude from our work that DNNs under budget restrictions benefit greatly from variety in the training set and that finding the right samples to train on is not the most effective strategy when balancing high performance with low computational requirements. Source code available at https://git.io/JKHa3 .
Semi-supervised dry herbage mass estimation using automatic data and synthetic images
Oct 26, 2021

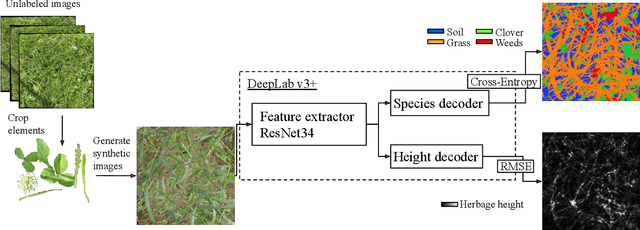

Monitoring species-specific dry herbage biomass is an important aspect of pasture-based milk production systems. Being aware of the herbage biomass in the field enables farmers to manage surpluses and deficits in herbage supply, as well as using targeted nitrogen fertilization when necessary. Deep learning for computer vision is a powerful tool in this context as it can accurately estimate the dry biomass of a herbage parcel using images of the grass canopy taken using a portable device. However, the performance of deep learning comes at the cost of an extensive, and in this case destructive, data gathering process. Since accurate species-specific biomass estimation is labor intensive and destructive for the herbage parcel, we propose in this paper to study low supervision approaches to dry biomass estimation using computer vision. Our contributions include: a synthetic data generation algorithm to generate data for a herbage height aware semantic segmentation task, an automatic process to label data using semantic segmentation maps, and a robust regression network trained to predict dry biomass using approximate biomass labels and a small trusted dataset with gold standard labels. We design our approach on a herbage mass estimation dataset collected in Ireland and also report state-of-the-art results on the publicly released Grass-Clover biomass estimation dataset from Denmark. Our code is available at https://git.io/J0L2a
Addressing out-of-distribution label noise in webly-labelled data
Oct 26, 2021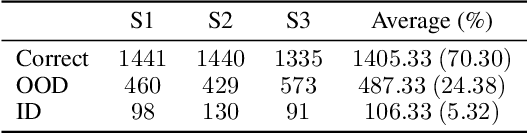
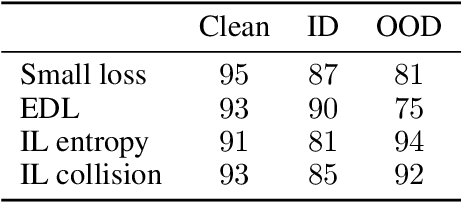
A recurring focus of the deep learning community is towards reducing the labeling effort. Data gathering and annotation using a search engine is a simple alternative to generating a fully human-annotated and human-gathered dataset. Although web crawling is very time efficient, some of the retrieved images are unavoidably noisy, i.e. incorrectly labeled. Designing robust algorithms for training on noisy data gathered from the web is an important research perspective that would render the building of datasets easier. In this paper we conduct a study to understand the type of label noise to expect when building a dataset using a search engine. We review the current limitations of state-of-the-art methods for dealing with noisy labels for image classification tasks in the case of web noise distribution. We propose a simple solution to bridge the gap with a fully clean dataset using Dynamic Softening of Out-of-distribution Samples (DSOS), which we design on corrupted versions of the CIFAR-100 dataset, and compare against state-of-the-art algorithms on the web noise perturbated MiniImageNet and Stanford datasets and on real label noise datasets: WebVision 1.0 and Clothing1M. Our work is fully reproducible https://git.io/JKGcj
Real Robot Challenge using Deep Reinforcement Learning
Sep 30, 2021


This paper details our winning submission to Phase 1 of the 2021 Real Robot Challenge, a challenge in which a three fingered robot must carry a cube along specified goal trajectories. To solve Phase 1, we use a pure reinforcement learning approach which requires minimal expert knowledge of the robotic system or of robotic grasping in general. A sparse goal-based reward is employed in conjunction with Hindsight Experience Replay to teach the control policy to move the cube to the desired x and y coordinates. Simultaneously, a dense distance-based reward is employed to teach the policy to lift the cube to the desired z coordinate. The policy is trained in simulation with domain randomization before being transferred to the real robot for evaluation. Although performance tends to worsen after this transfer, our best trained policy can successfully lift the real cube along goal trajectories via the use of an effective pinching grasp. Our approach outperforms all other submissions, including those leveraging more traditional robotic control techniques, and is the first learning-based approach to solve this challenge.
Discerning Generic Event Boundaries in Long-Form Wild Videos
Jun 18, 2021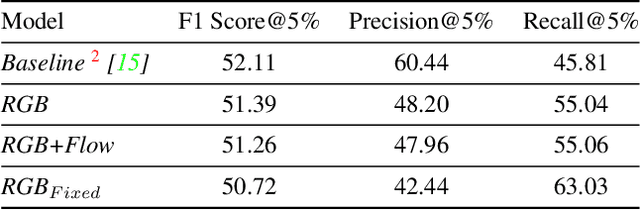
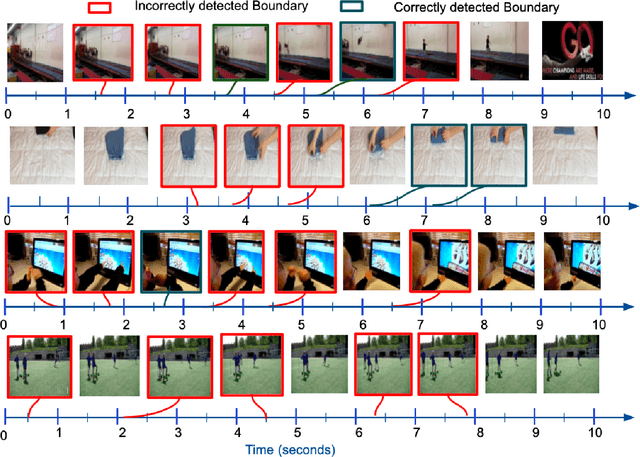
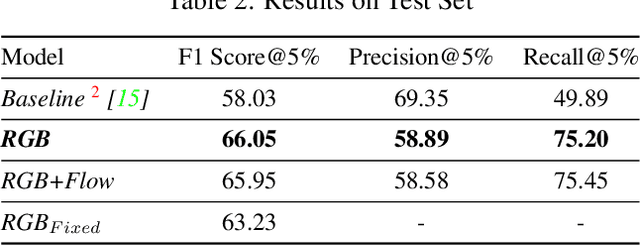
Detecting generic, taxonomy-free event boundaries invideos represents a major stride forward towards holisticvideo understanding. In this paper we present a technique forgeneric event boundary detection based on a two stream in-flated 3D convolutions architecture, which can learn spatio-temporal features from videos. Our work is inspired from theGeneric Event Boundary Detection Challenge (part of CVPR2021 Long Form Video Understanding- LOVEU Workshop).Throughout the paper we provide an in-depth analysis ofthe experiments performed along with an interpretation ofthe results obtained.
PixInWav: Residual Steganography for Hiding Pixels in Audio
Jun 17, 2021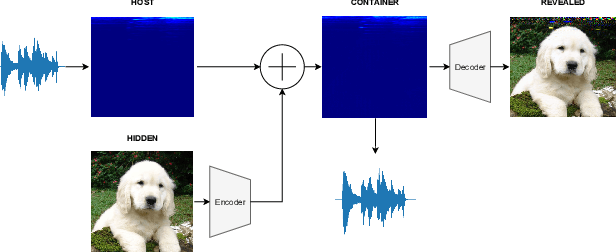
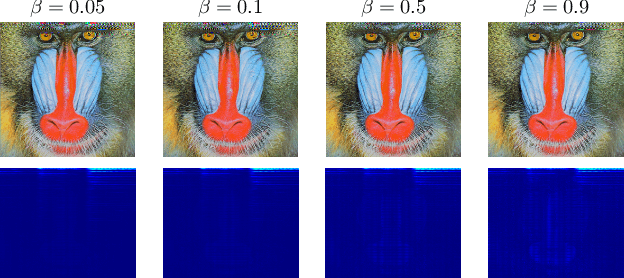
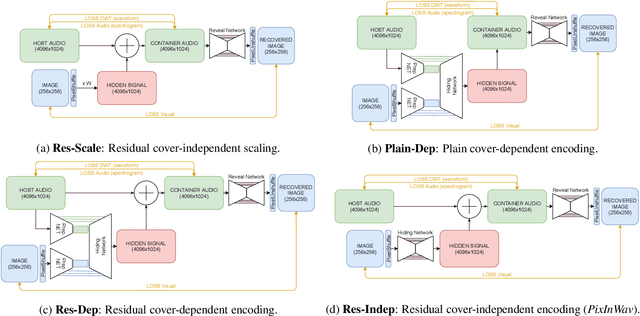
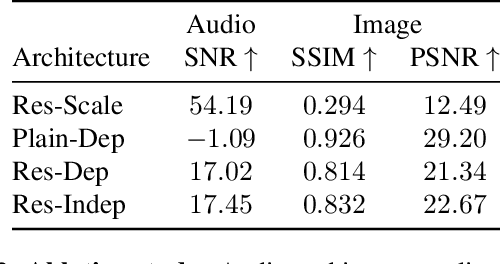
Steganography comprises the mechanics of hiding data in a host media that may be publicly available. While previous works focused on unimodal setups (e.g., hiding images in images, or hiding audio in audio), PixInWav targets the multimodal case of hiding images in audio. To this end, we propose a novel residual architecture operating on top of short-time discrete cosine transform (STDCT) audio spectrograms. Among our results, we find that the residual audio steganography setup we propose allows independent encoding of the hidden image from the host audio without compromising quality. Accordingly, while previous works require both host and hidden signals to hide a signal, PixInWav can encode images offline -- which can be later hidden, in a residual fashion, into any audio signal. Finally, we test our scheme in a lab setting to transmit images over airwaves from a loudspeaker to a microphone verifying our theoretical insights and obtaining promising results.
Evaluating Contrastive Models for Instance-based Image Retrieval
Apr 30, 2021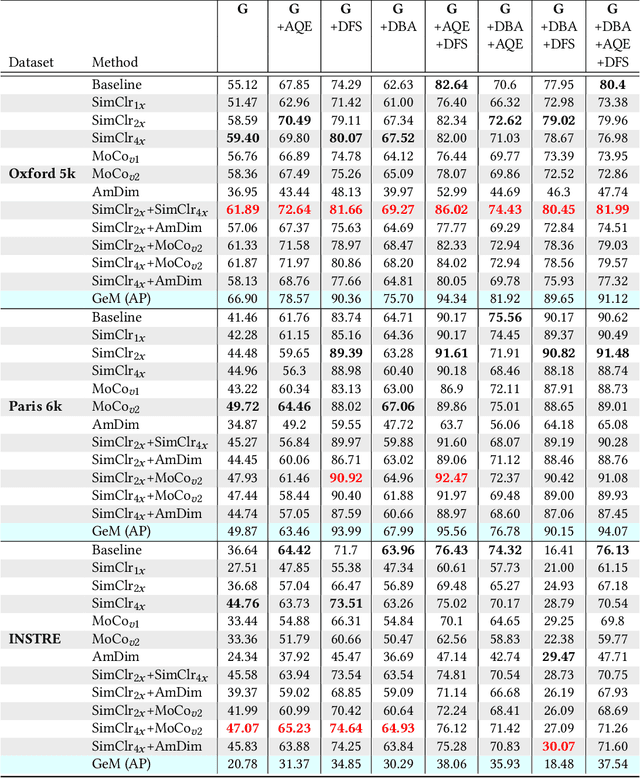
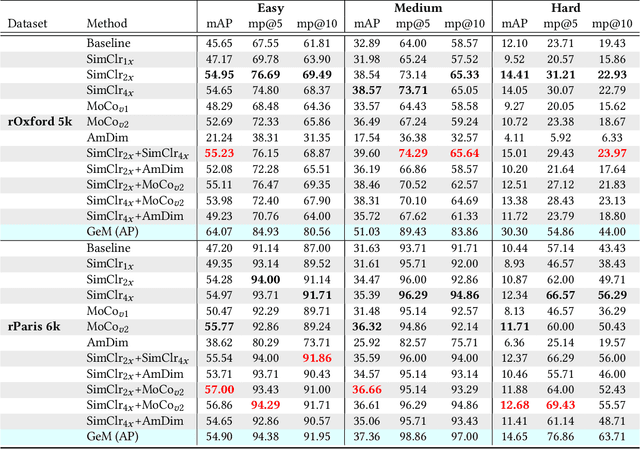
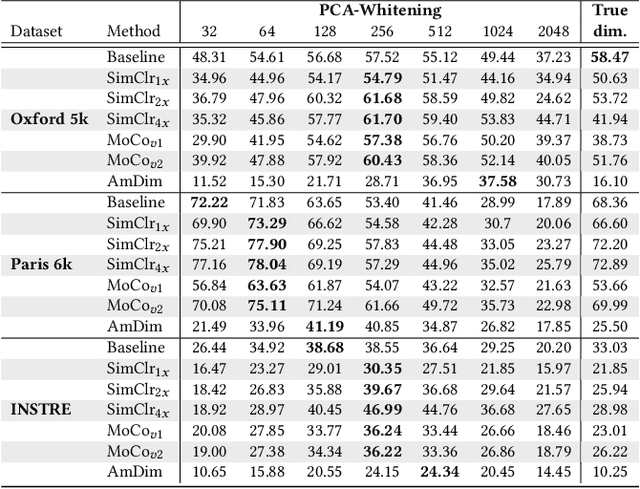
In this work, we evaluate contrastive models for the task of image retrieval. We hypothesise that models that are learned to encode semantic similarity among instances via discriminative learning should perform well on the task of image retrieval, where relevancy is defined in terms of instances of the same object. Through our extensive evaluation, we find that representations from models trained using contrastive methods perform on-par with (and outperforms) a pre-trained supervised baseline trained on the ImageNet labels in retrieval tasks under various configurations. This is remarkable given that the contrastive models require no explicit supervision. Thus, we conclude that these models can be used to bootstrap base models to build more robust image retrieval engines.
Extracting Pasture Phenotype and Biomass Percentages using Weakly Supervised Multi-target Deep Learning on a Small Dataset
Jan 08, 2021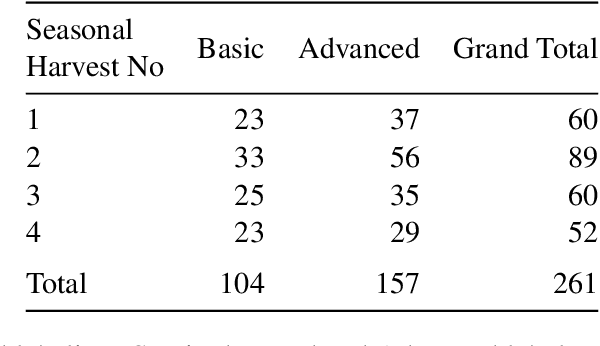


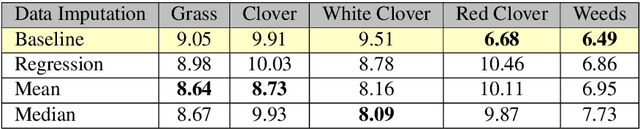
The dairy industry uses clover and grass as fodder for cows. Accurate estimation of grass and clover biomass yield enables smart decisions in optimizing fertilization and seeding density, resulting in increased productivity and positive environmental impact. Grass and clover are usually planted together, since clover is a nitrogen-fixing plant that brings nutrients to the soil. Adjusting the right percentages of clover and grass in a field reduces the need for external fertilization. Existing approaches for estimating the grass-clover composition of a field are expensive and time consuming - random samples of the pasture are clipped and then the components are physically separated to weigh and calculate percentages of dry grass, clover and weeds in each sample. There is growing interest in developing novel deep learning based approaches to non-destructively extract pasture phenotype indicators and biomass yield predictions of different plant species from agricultural imagery collected from the field. Providing these indicators and predictions from images alone remains a significant challenge. Heavy occlusions in the dense mixture of grass, clover and weeds make it difficult to estimate each component accurately. Moreover, although supervised deep learning models perform well with large datasets, it is tedious to acquire large and diverse collections of field images with precise ground truth for different biomass yields. In this paper, we demonstrate that applying data augmentation and transfer learning is effective in predicting multi-target biomass percentages of different plant species, even with a small training dataset. The scheme proposed in this paper used a training set of only 261 images and provided predictions of biomass percentages of grass, clover, white clover, red clover, and weeds with mean absolute error of 6.77%, 6.92%, 6.21%, 6.89%, and 4.80% respectively.
Temporal Bilinear Encoding Network of Audio-Visual Features at Low Sampling Rates
Dec 18, 2020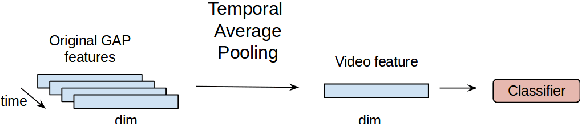

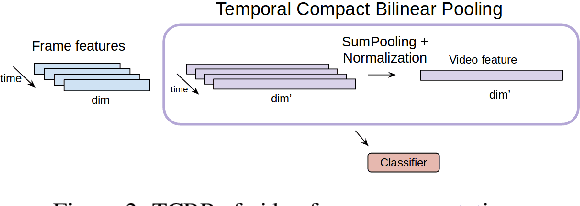
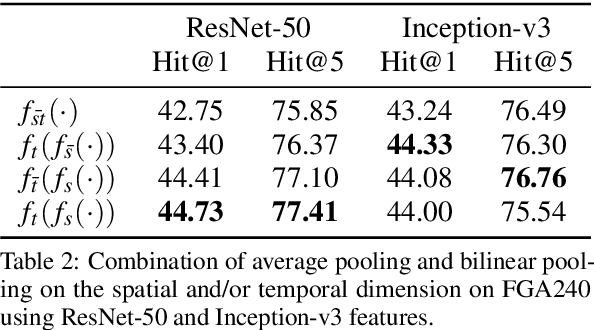
Current deep learning based video classification architectures are typically trained end-to-end on large volumes of data and require extensive computational resources. This paper aims to exploit audio-visual information in video classification with a 1 frame per second sampling rate. We propose Temporal Bilinear Encoding Networks (TBEN) for encoding both audio and visual long range temporal information using bilinear pooling and demonstrate bilinear pooling is better than average pooling on the temporal dimension for videos with low sampling rate. We also embed the label hierarchy in TBEN to further improve the robustness of the classifier. Experiments on the FGA240 fine-grained classification dataset using TBEN achieve a new state-of-the-art (hit@1=47.95%). We also exploit the possibility of incorporating TBEN with multiple decoupled modalities like visual semantic and motion features: experiments on UCF101 sampled at 1 FPS achieve close to state-of-the-art accuracy (hit@1=91.03%) while requiring significantly less computational resources than competing approaches for both training and prediction.
Multi-Objective Interpolation Training for Robustness to Label Noise
Dec 08, 2020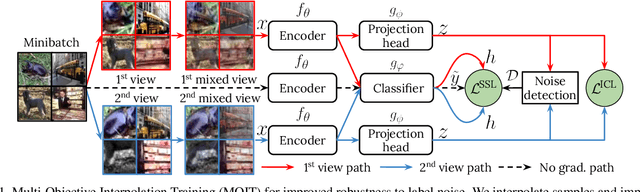
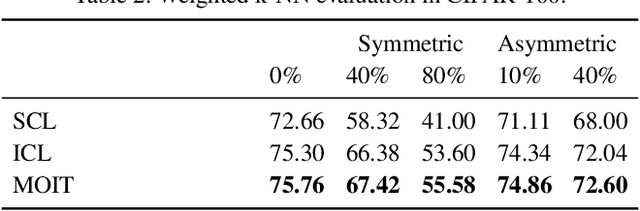

Deep neural networks trained with standard cross-entropy loss memorize noisy labels, which degrades their performance. Most research to mitigate this memorization proposes new robust classification loss functions. Conversely, we explore the behavior of supervised contrastive learning under label noise to understand how it can improve image classification in these scenarios. In particular, we propose a Multi-Objective Interpolation Training (MOIT) approach that jointly exploits contrastive learning and classification. We show that standard contrastive learning degrades in the presence of label noise and propose an interpolation training strategy to mitigate this behavior. We further propose a novel label noise detection method that exploits the robust feature representations learned via contrastive learning to estimate per-sample soft-labels whose disagreements with the original labels accurately identify noisy samples. This detection allows treating noisy samples as unlabeled and training a classifier in a semi-supervised manner. We further propose MOIT+, a refinement of MOIT by fine-tuning on detected clean samples. Hyperparameter and ablation studies verify the key components of our method. Experiments on synthetic and real-world noise benchmarks demonstrate that MOIT/MOIT+ achieves state-of-the-art results. Code is available at https://git.io/JI40X.