 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixInWav: Residual Steganography for Hiding Pixels in Audio
Jun 17, 2021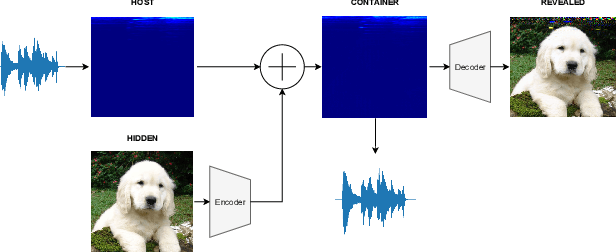
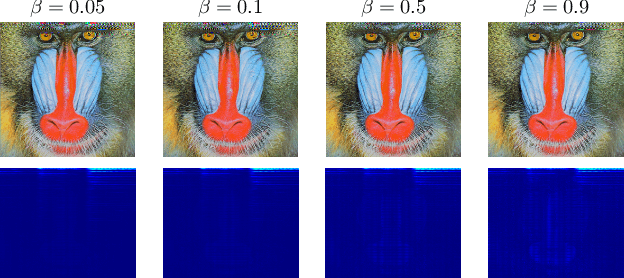
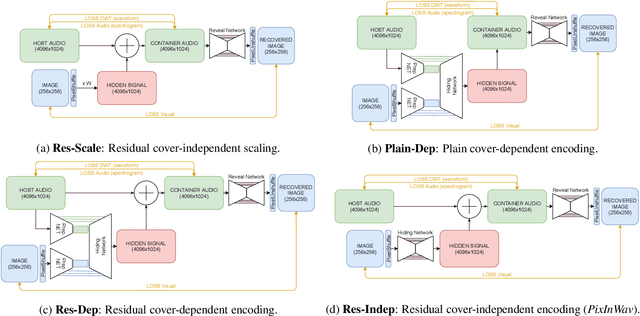
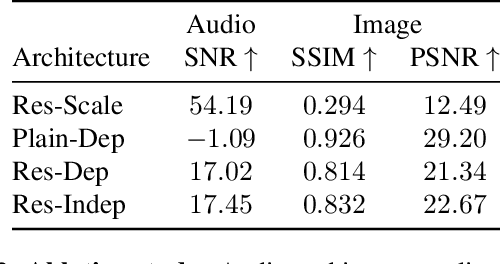
Steganography comprises the mechanics of hiding data in a host media that may be publicly available. While previous works focused on unimodal setups (e.g., hiding images in images, or hiding audio in audio), PixInWav targets the multimodal case of hiding images in audio. To this end, we propose a novel residual architecture operating on top of short-time discrete cosine transform (STDCT) audio spectrograms. Among our results, we find that the residual audio steganography setup we propose allows independent encoding of the hidden image from the host audio without compromising quality. Accordingly, while previous works require both host and hidden signals to hide a signal, PixInWav can encode images offline -- which can be later hidden, in a residual fashion, into any audio signal. Finally, we test our scheme in a lab setting to transmit images over airwaves from a loudspeaker to a microphone verifying our theoretical insights and obtaining promising results.