 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Emergence of Compositional Languages for Numeric Concepts Through Iterated Learning in Neural Agents
Oct 11, 2019

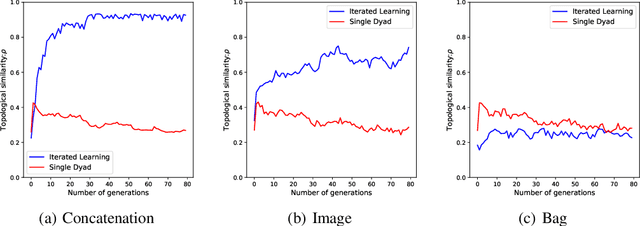
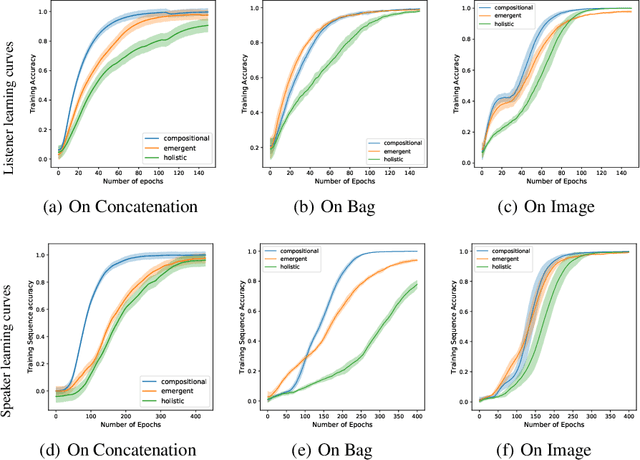
Since first introduced, computer simulation has been an increasingly important tool in evolutionary linguistics. Recently, with the development of deep learning techniques, research in grounded language learning has also started to focus on facilitating the emergence of compositional languages without pre-defined elementary linguistic knowledge. In this work, we explore the emergence of compositional languages for numeric concepts in multi-agent communication systems. We demonstrate that compositional language for encoding numeric concepts can emerge through iterated learning in populations of deep neural network agents. However, language properties greatly depend on the input representations given to agents. We found that compositional languages only emerge if they require less iterations to be fully learnt than other non-degenerate languages for agents on a given input representation.
Challenges in detecting evolutionary forces in language change using diachronic corpora
Nov 03, 2018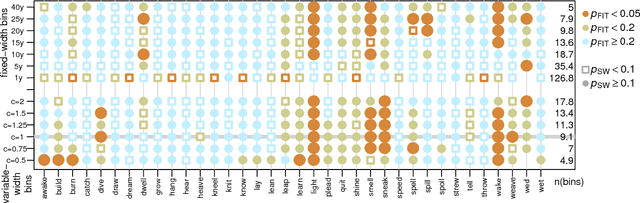
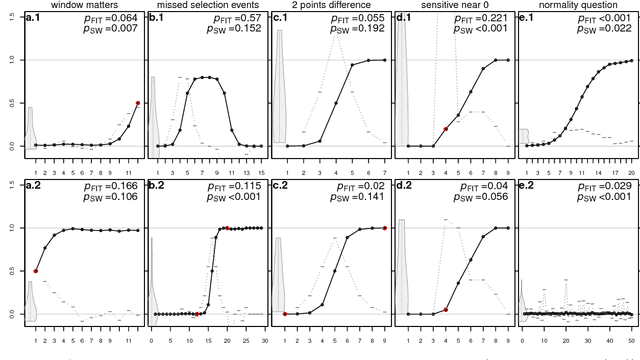
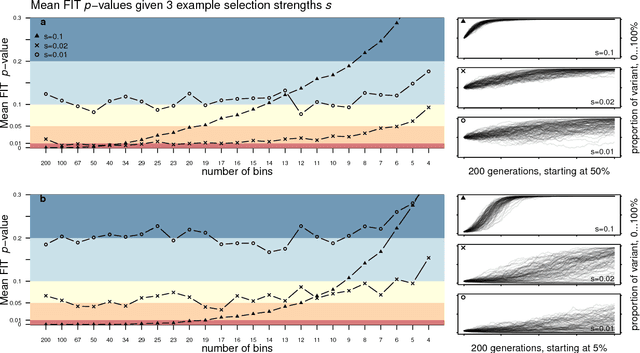
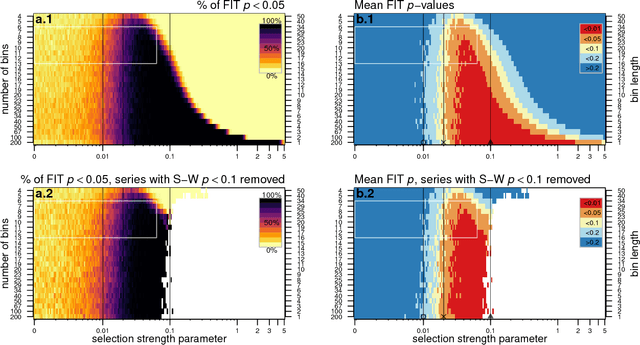
Newberry et al. (Detecting evolutionary forces in language change, Nature 551, 2017) tackle an important but difficult problem in linguistics, the testing of selective theories of language change against a null model of drift. Having applied a test from population genetics (the Frequency Increment Test) to a number of relevant examples, they suggest stochasticity has a previously under-appreciated role in language evolution. We replicate their results and find that while the overall observation holds, results produced by this approach on individual time series are highly sensitive to how the corpus is organized into temporal segments (binning). Furthermore, we use a large set of simulations in conjunction with binning to systematically explore the range of applicability of the FIT. The approach proposed by Newberry et al. provides a systematic way of generating hypotheses about language change, marking another step forward in big-data driven linguistic research. However, along with the possibilities, the limitations of the approach need to be appreciated. Caution should be exercised with interpreting results of the FIT (and similar tests) on individual series, given the demonstrable limitations, and fundamental differences between genetic and linguistic data. Our findings also have implications for selection testing and temporal binning in general.
The cognitive roots of regularization in language
Oct 18, 2018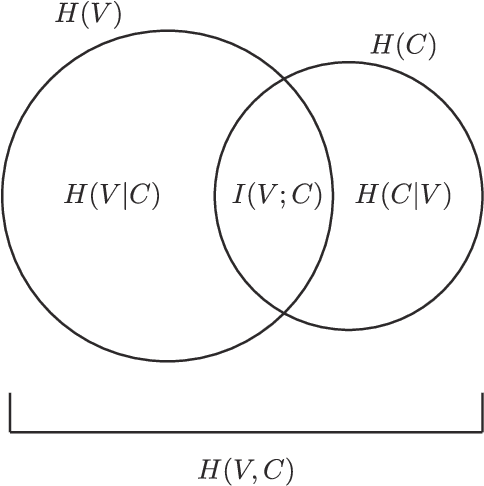
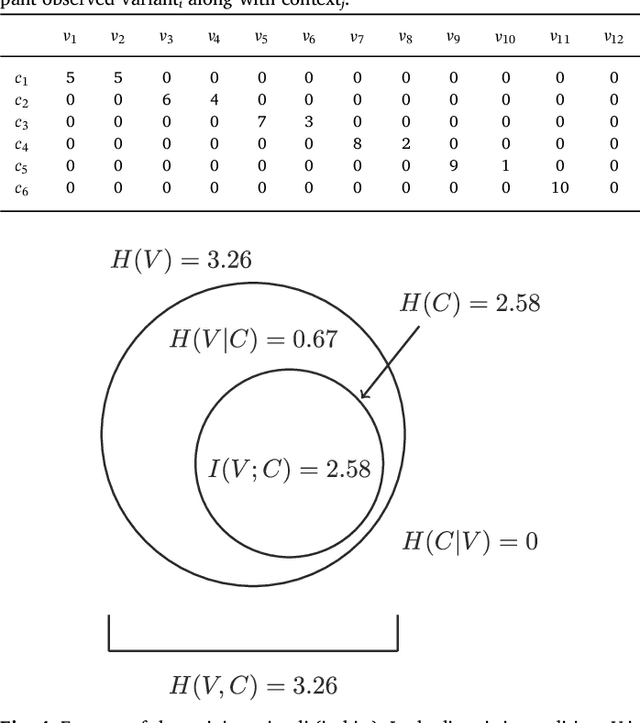
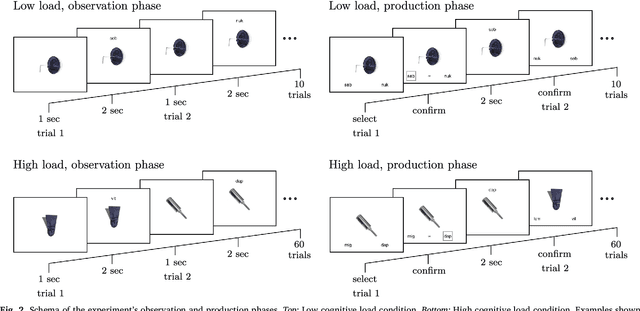
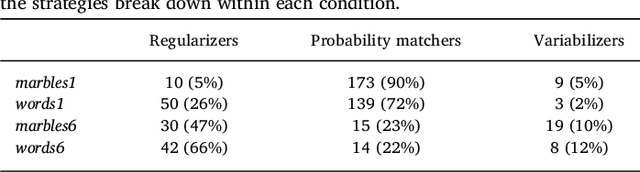
Regularization occurs when the output a learner produces is less variable than the linguistic data they observed. In an artificial language learning experiment, we show that there exist at least two independent sources of regularization bias in cognition: a domain-general source based on cognitive load and a domain-specific source triggered by linguistic stimuli. Both of these factors modulate how frequency information is encoded and produced, but only the production-side modulations result in regularization (i.e. cause learners to eliminate variation from the observed input). We formalize the definition of regularization as the reduction of entropy and find that entropy measures are better at identifying regularization behavior than frequency-based analyses. Using our experimental data and a model of cultural transmission, we generate predictions for the amount of regularity that would develop in each experimental condition if the artificial language were transmitted over several generations of learners. Here we find that the effect of cognitive constraints can become more complex when put into the context of cultural evolution: although learning biases certainly carry information about the course of language evolution, we should not expect a one-to-one correspondence between the micro-level processes that regularize linguistic datasets and the macro-level evolution of linguistic regularity.
Quantifying the dynamics of topical fluctuations in language
Jun 13, 2018
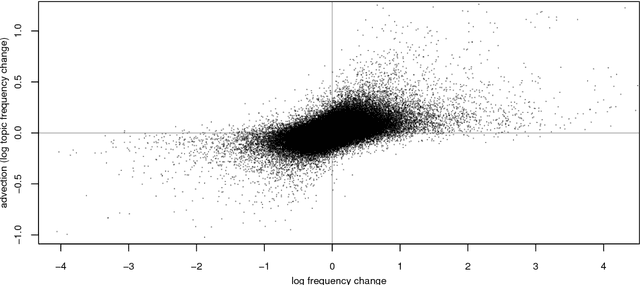
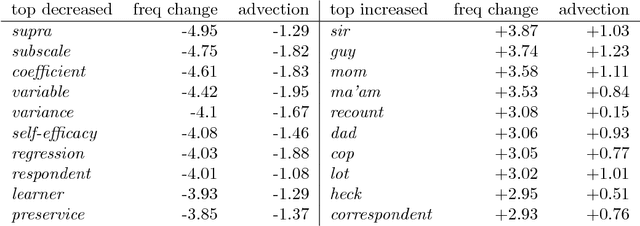
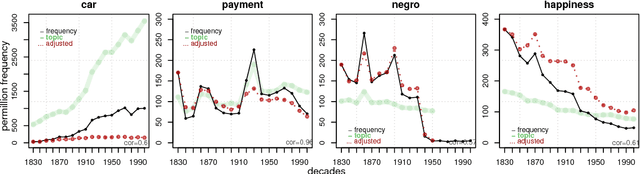
The availability of large diachronic corpora has provided the impetus for a growing body of quantitative research on language evolution and meaning change. The central quantities in this research are token frequencies of linguistic elements in the texts, with changes in frequency taken to reflect the popularity or selective fitness of an element. However, corpus frequencies may change for a wide variety of reasons, including purely random sampling effects, or because corpora are composed of contemporary media and fiction texts within which the underlying topics ebb and flow with cultural and socio-political trends. In this work, we introduce a computationally simple model for controlling for topical fluctuations in corpora - the topical-cultural advection model - and demonstrate how it provides a robust baseline of variability in word frequency changes over time. We validate the model on a diachronic corpus spanning two centuries, and a carefully-controlled artificial language change scenario, and then use it to correct for topical fluctuations in historical time series. Finally, we show that the model can be used to show that emergence of new words typically corresponds with the rise of a trending topic. This suggests that some lexical innovations occur due to growing communicative need in a subspace of the lexicon, and that the topical-cultural advection model can be used to quantify this.
Word learning under infinite uncertainty
Feb 10, 2016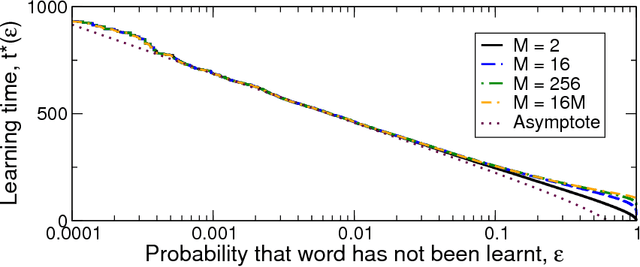
Language learners must learn the meanings of many thousands of words, despite those words occurring in complex environments in which infinitely many meanings might be inferred by the learner as a word's true meaning. This problem of infinite referential uncertainty is often attributed to Willard Van Orman Quine. We provide a mathematical formalisation of an ideal cross-situational learner attempting to learn under infinite referential uncertainty, and identify conditions under which word learning is possible. As Quine's intuitions suggest, learning under infinite uncertainty is in fact possible, provided that learners have some means of ranking candidate word meanings in terms of their plausibility; furthermore, our analysis shows that this ranking could in fact be exceedingly weak, implying that constraints which allow learners to infer the plausibility of candidate word meanings could themselves be weak. This approach lifts the burden of explanation from `smart' word learning constraints in learners, and suggests a programme of research into weak, unreliable, probabilistic constraints on the inference of word meaning in real word learners.
* 30 pages, 4 figures, contains considerable extra discussion and relaxation of original model assumptions. Version to appear in Cognition
Stochastic dynamics of lexicon learning in an uncertain and nonuniform world
May 31, 2013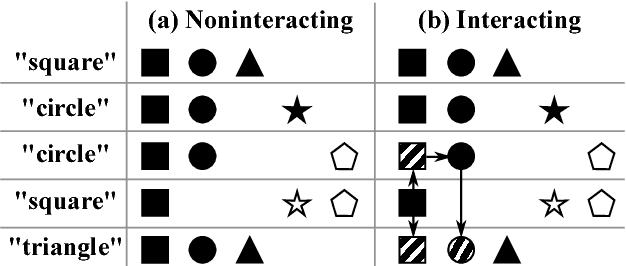
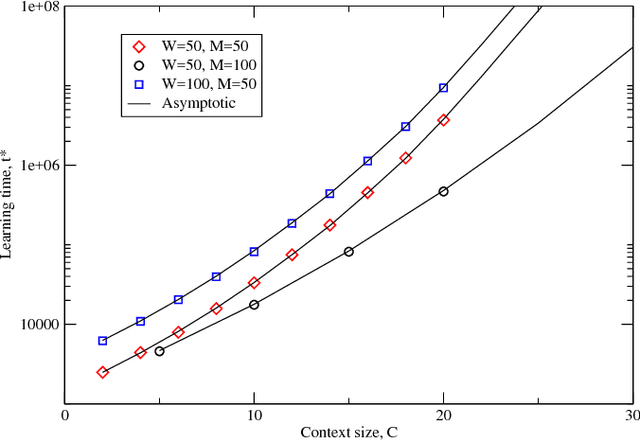
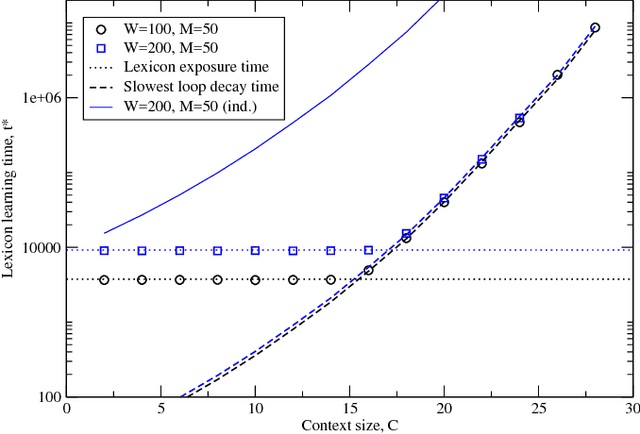
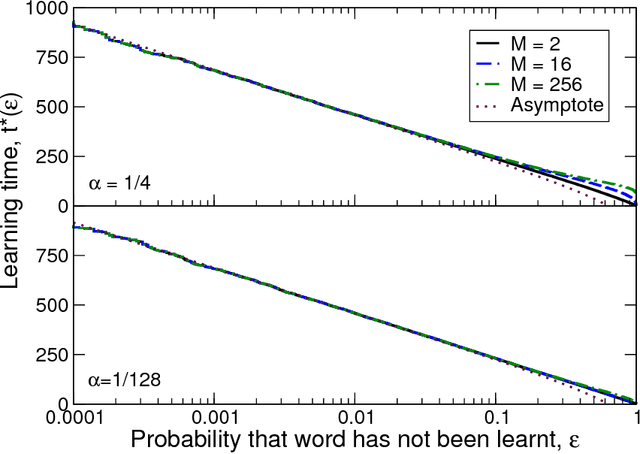
We study the time taken by a language learner to correctly identify the meaning of all words in a lexicon under conditions where many plausible meanings can be inferred whenever a word is uttered. We show that the most basic form of cross-situational learning - whereby information from multiple episodes is combined to eliminate incorrect meanings - can perform badly when words are learned independently and meanings are drawn from a nonuniform distribution. If learners further assume that no two words share a common meaning, we find a phase transition between a maximally-efficient learning regime, where the learning time is reduced to the shortest it can possibly be, and a partially-efficient regime where incorrect candidate meanings for words persist at late times. We obtain exact results for the word-learning process through an equivalence to a statistical mechanical problem of enumerating loops in the space of word-meaning mappings.
* 7 pages, 3 figures. Version 2 contains additional discussion and will appear in Phys. Rev. Lett