 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGender Bias Amplification During Speed-Quality Optimization in Neural Machine Translation
Jun 01, 2021
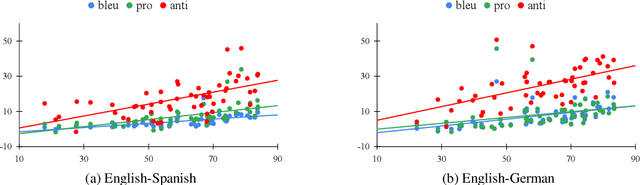
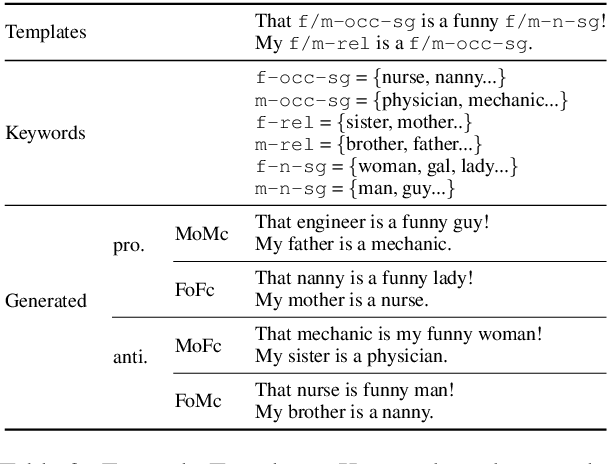

Is bias amplified when neural machine translation (NMT) models are optimized for speed and evaluated on generic test sets using BLEU? We investigate architectures and techniques commonly used to speed up decoding in Transformer-based models, such as greedy search, quantization, average attention networks (AANs) and shallow decoder models and show their effect on gendered noun translation. We construct a new gender bias test set, SimpleGEN, based on gendered noun phrases in which there is a single, unambiguous, correct answer. While we find minimal overall BLEU degradation as we apply speed optimizations, we observe that gendered noun translation performance degrades at a much faster rate.
Exploring Monolingual Data for Neural Machine Translation with Knowledge Distillation
Dec 31, 2020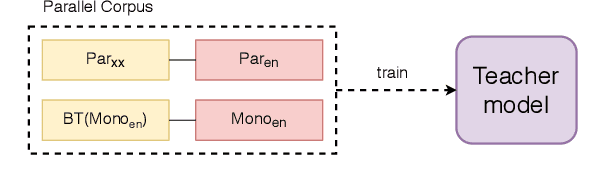
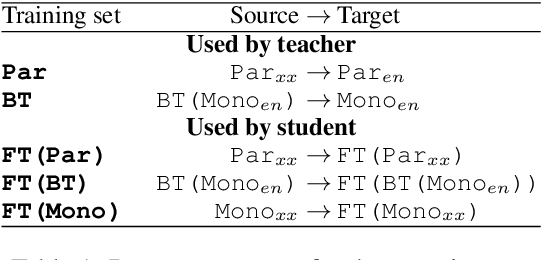
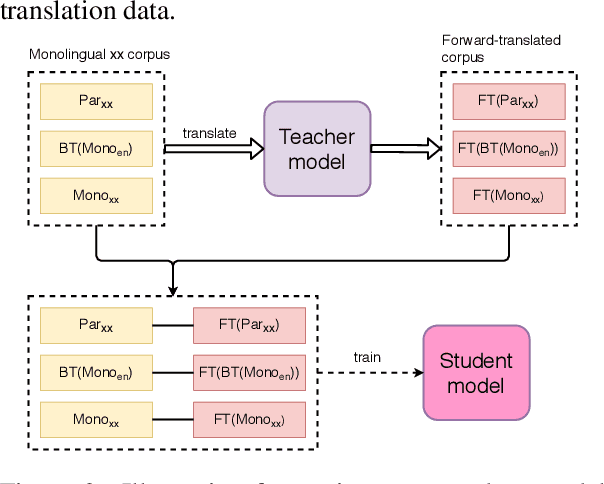
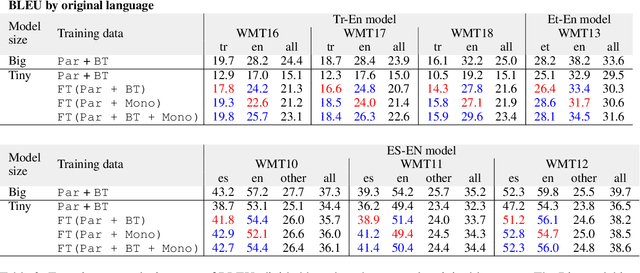
We explore two types of monolingual data that can be included in knowledge distillation training for neural machine translation (NMT). The first is the source-side monolingual data. Second, is the target-side monolingual data that is used as back-translation data. Both datasets are (forward-)translated by a teacher model from source-language to target-language, which are then combined into a dataset for smaller student models. We find that source-side monolingual data improves model performance when evaluated by test-set originated from source-side. Likewise, target-side data has a positive effect on the test-set in the opposite direction. We also show that it is not required to train the student model with the same data used by the teacher, as long as the domains are the same. Finally, we find that combining source-side and target-side yields in better performance than relying on just one side of the monolingual data.
Approaching Neural Chinese Word Segmentation as a Low-Resource Machine Translation Task
Aug 12, 2020
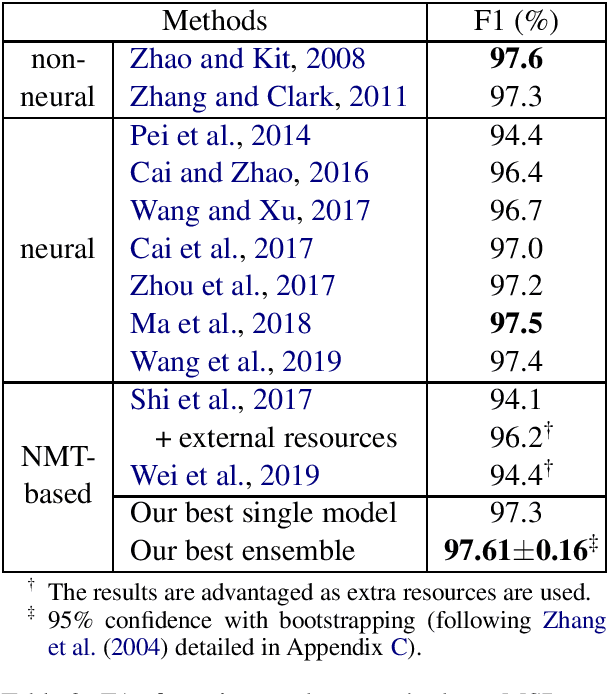
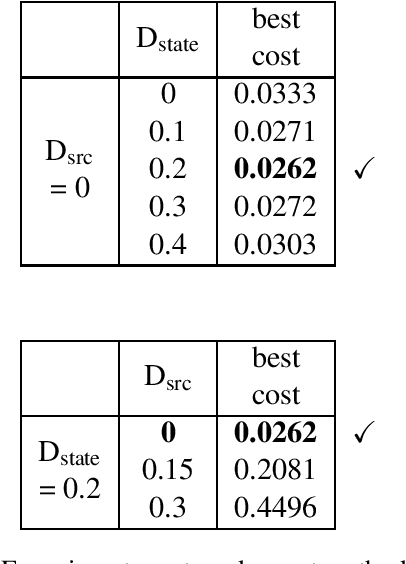
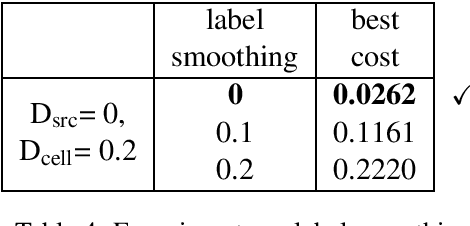
Supervised Chinese word segmentation has been widely approached as sequence labeling or sequence modeling. Recently, some researchers attempted to treat it as character-level translation, but there is still a performance gap between the translation-based approach and other methods. In this work, we apply the best practices from low-resource neural machine translation to Chinese word segmentation. We build encoder-decoder models with attention, and examine a series of techniques including regularization, data augmentation, objective weighting, transfer learning and ensembling. When benchmarked on MSR corpus under closed test condition without additional data, our method achieves 97.6% F1, which is on a par with the state of the art.
The Sockeye 2 Neural Machine Translation Toolkit at AMTA 2020
Aug 11, 2020
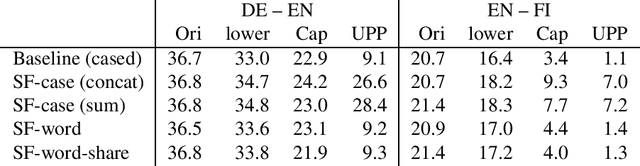
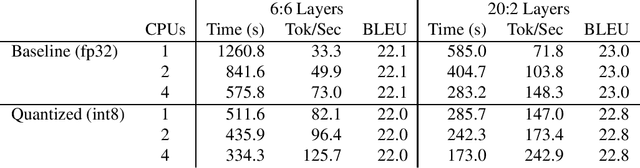

We present Sockeye 2, a modernized and streamlined version of the Sockeye neural machine translation (NMT) toolkit. New features include a simplified code base through the use of MXNet's Gluon API, a focus on state of the art model architectures, distributed mixed precision training, and efficient CPU decoding with 8-bit quantization. These improvements result in faster training and inference, higher automatic metric scores, and a shorter path from research to production.
Neural Machine Translation with 4-Bit Precision and Beyond
Sep 20, 2019
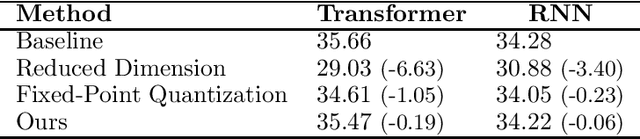
Neural Machine Translation (NMT) is resource intensive. We design a quantization procedure to compress NMT models better for devices with limited hardware capability. Because most neural network parameters are near zero, we employ logarithmic quantization in lieu of fixed-point quantization. However, we find bias terms are less amenable to log quantization but note they comprise a tiny fraction of the model, so we leave them uncompressed. We also propose to use an error-feedback mechanism during retraining, to preserve the compressed model as a stale gradient. We empirically show that NMT models based on Transformer or RNN architecture can be compressed up to 4-bit precision without any noticeable quality degradation. Models can be compressed up to binary precision, albeit with lower quality. The RNN architecture seems to be more robust to quantization, compared to the Transformer.
Making Asynchronous Stochastic Gradient Descent Work for Transformers
Jun 08, 2019

Asynchronous stochastic gradient descent (SGD) is attractive from a speed perspective because workers do not wait for synchronization. However, the Transformer model converges poorly with asynchronous SGD, resulting in substantially lower quality compared to synchronous SGD. To investigate why this is the case, we isolate differences between asynchronous and synchronous methods to investigate batch size and staleness effects. We find that summing several asynchronous updates, rather than applying them immediately, restores convergence behavior. With this hybrid method, Transformer training for neural machine translation task reaches a near-convergence level 1.36x faster in single-node multi-GPU training with no impact on model quality.
Accelerating Asynchronous Stochastic Gradient Descent for Neural Machine Translation
Sep 14, 2018



In order to extract the best possible performance from asynchronous stochastic gradient descent one must increase the mini-batch size and scale the learning rate accordingly. In order to achieve further speedup we introduce a technique that delays gradient updates effectively increasing the mini-batch size. Unfortunately with the increase of mini-batch size we worsen the stale gradient problem in asynchronous stochastic gradient descent (SGD) which makes the model convergence poor. We introduce local optimizers which mitigate the stale gradient problem and together with fine tuning our momentum we are able to train a shallow machine translation system 27% faster than an optimized baseline with negligible penalty in BLEU.
Multi-Source Syntactic Neural Machine Translation
Aug 30, 2018
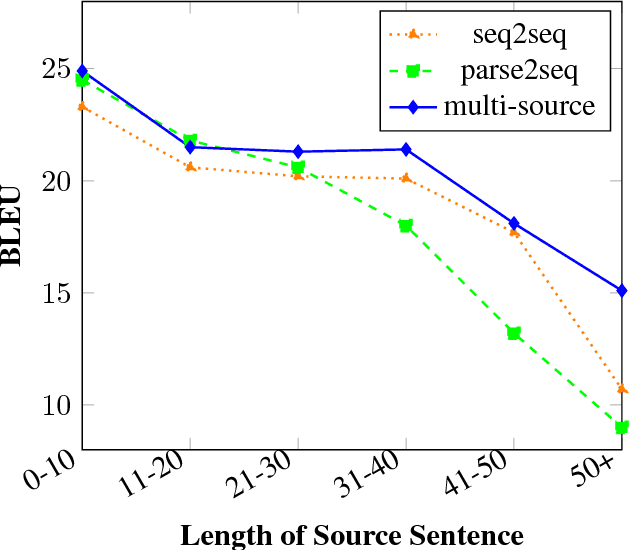


We introduce a novel multi-source technique for incorporating source syntax into neural machine translation using linearized parses. This is achieved by employing separate encoders for the sequential and parsed versions of the same source sentence; the resulting representations are then combined using a hierarchical attention mechanism. The proposed model improves over both seq2seq and parsed baselines by over 1 BLEU on the WMT17 English-German task. Further analysis shows that our multi-source syntactic model is able to translate successfully without any parsed input, unlike standard parsed methods. In addition, performance does not deteriorate as much on long sentences as for the baselines.
Fast Neural Machine Translation Implementation
Jun 07, 2018
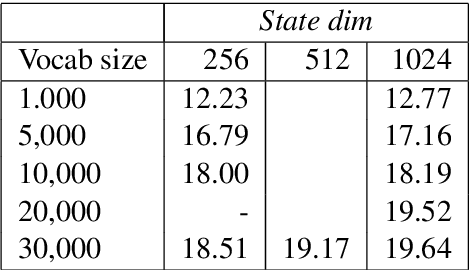
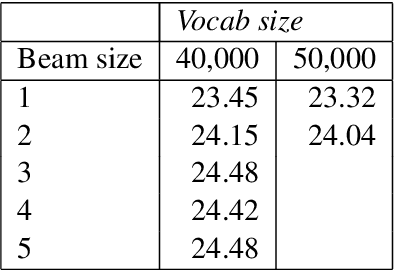
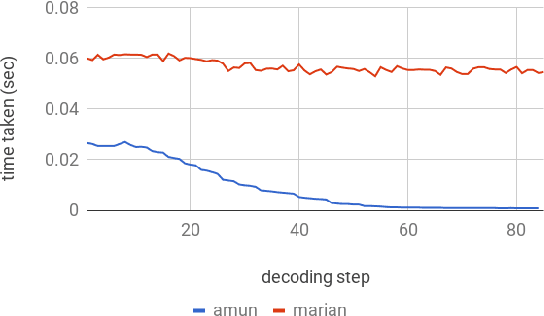
This paper describes the submissions to the efficiency track for GPUs at the Workshop for Neural Machine Translation and Generation by members of the University of Edinburgh, Adam Mickiewicz University, Tilde and University of Alicante. We focus on efficient implementation of the recurrent deep-learning model as implemented in Amun, the fast inference engine for neural machine translation. We improve the performance with an efficient mini-batching algorithm, and by fusing the softmax operation with the k-best extraction algorithm. Submissions using Amun were first, second and third fastest in the GPU efficiency track.
Marian: Cost-effective High-Quality Neural Machine Translation in C++
May 30, 2018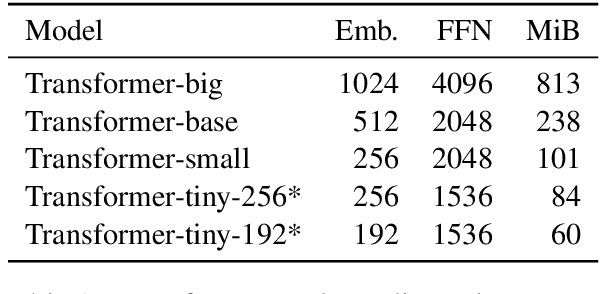
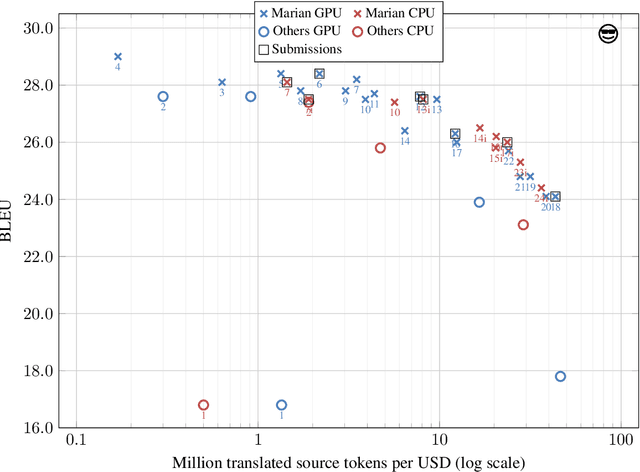
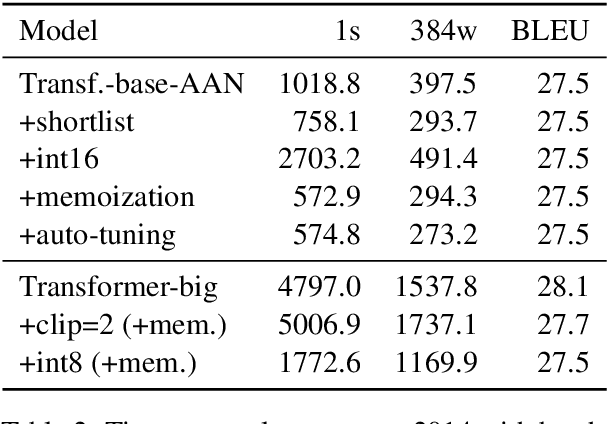
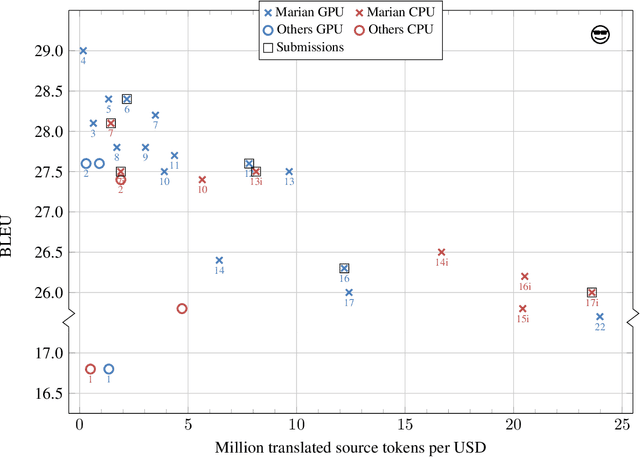
This paper describes the submissions of the "Marian" team to the WNMT 2018 shared task. We investigate combinations of teacher-student training, low-precision matrix products, auto-tuning and other methods to optimize the Transformer model on GPU and CPU. By further integrating these methods with the new averaging attention networks, a recently introduced faster Transformer variant, we create a number of high-quality, high-performance models on the GPU and CPU, dominating the Pareto frontier for this shared task.