 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Brain Responses to Language with Sparse Features from Language Models
Jun 05, 2026A central goal of cognitive neuroscience is to characterize the features that are represented by human language cortex. Artificial language models (LMs) have emerged as a powerful tool to address this challenge, but studies relating biological and artificial representations are often criticized as relating one black box to another. The present work introduces Augmented Sparse Encoding Models, an encoding framework that replaces dense LM hidden states with hierarchically-organized sparse autoencoder (SAE) features, while explicitly including surprisal as a predictor. Using this approach, we (i) produce interpretations of neural responses and (ii) test whether model-brain alignment reflects primary or idiosyncratic variation in LM representations. Using a high-field 7T fMRI dataset of eight participants listening to 200 linguistically diverse sentences, we first validate our modeling framework by recovering previous interpretations of voxel populations tuned to processing difficulty and meaning abstractness. We then interpret a previously-uncharacterized (but reliable) voxel population and find that it is tuned to people-related content. Next, we show that the fronto-temporal human language network is predicted by a common set of features across its constituent regions, but find that frontal regions are relatively well-explained by surprisal alone, even in the absence of LM-based features. Finally, we show that brain responses during language processing are not merely predictable from an arbitrary set of LM features. Rather, brain responses are best explained by the features that tend to capture the most general information encoded in LM representations, suggesting a nontrivial correspondence between brain and LM language representation.
NSD-Imagery: A benchmark dataset for extending fMRI vision decoding methods to mental imagery
Jun 07, 2025



We release NSD-Imagery, a benchmark dataset of human fMRI activity paired with mental images, to complement the existing Natural Scenes Dataset (NSD), a large-scale dataset of fMRI activity paired with seen images that enabled unprecedented improvements in fMRI-to-image reconstruction efforts. Recent models trained on NSD have been evaluated only on seen image reconstruction. Using NSD-Imagery, it is possible to assess how well these models perform on mental image reconstruction. This is a challenging generalization requirement because mental images are encoded in human brain activity with relatively lower signal-to-noise and spatial resolution; however, generalization from seen to mental imagery is critical for real-world applications in medical domains and brain-computer interfaces, where the desired information is always internally generated. We provide benchmarks for a suite of recent NSD-trained open-source visual decoding models (MindEye1, MindEye2, Brain Diffuser, iCNN, Takagi et al.) on NSD-Imagery, and show that the performance of decoding methods on mental images is largely decoupled from performance on vision reconstruction. We further demonstrate that architectural choices significantly impact cross-decoding performance: models employing simple linear decoding architectures and multimodal feature decoding generalize better to mental imagery, while complex architectures tend to overfit visual training data. Our findings indicate that mental imagery datasets are critical for the development of practical applications, and establish NSD-Imagery as a useful resource for better aligning visual decoding methods with this goal.
Semantic scene descriptions as an objective of human vision
Sep 23, 2022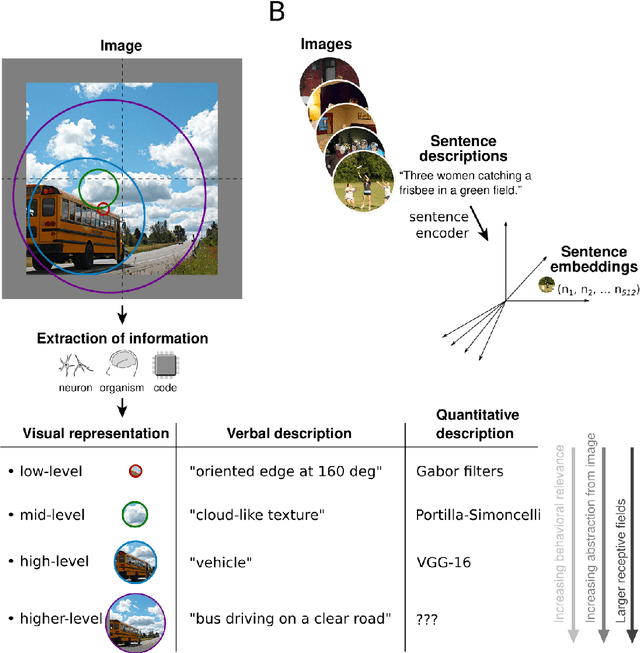
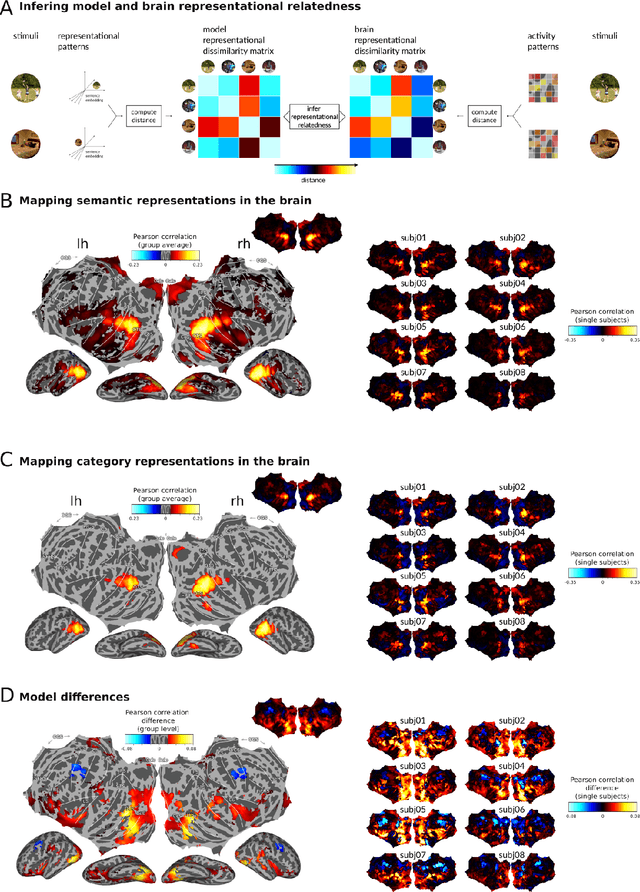
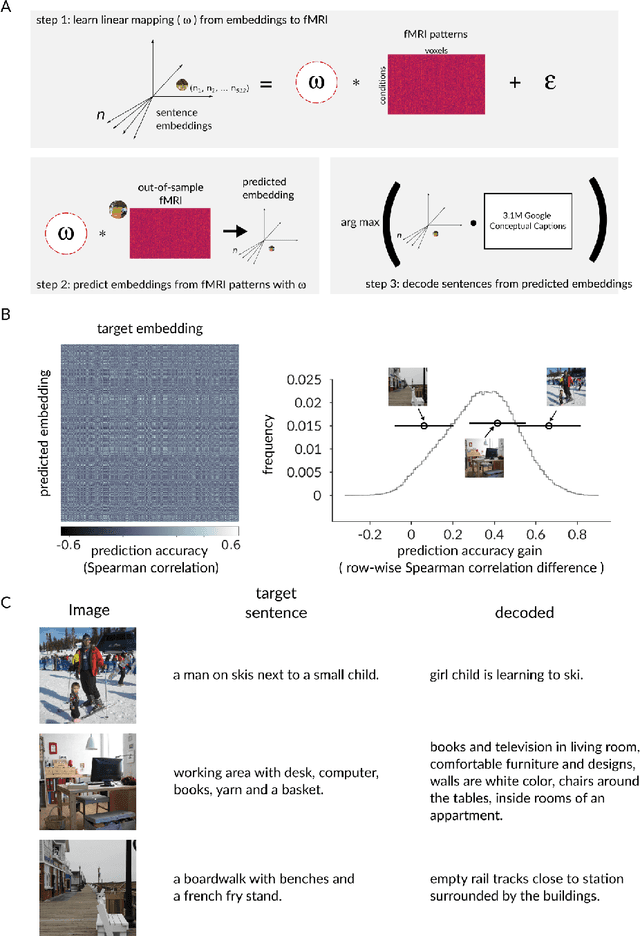
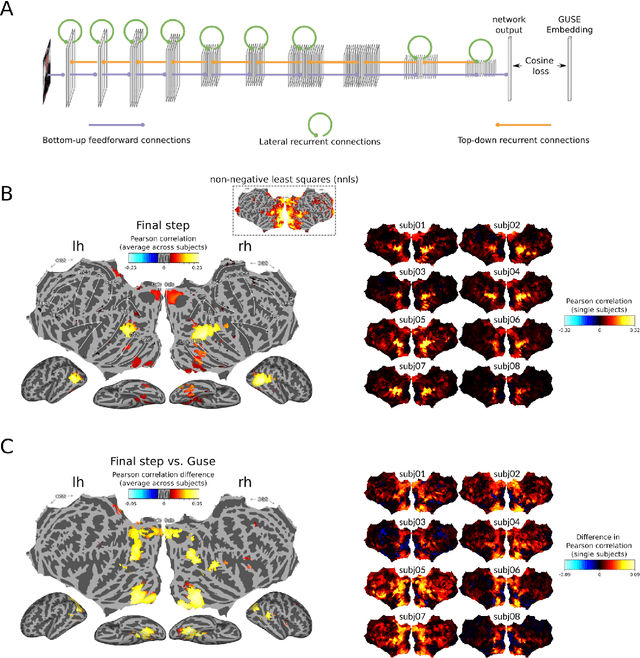
Interpreting the meaning of a visual scene requires not only identification of its constituent objects, but also a rich semantic characterization of object interrelations. Here, we study the neural mechanisms underlying visuo-semantic transformations by applying modern computational techniques to a large-scale 7T fMRI dataset of human brain responses elicited by complex natural scenes. Using semantic embeddings obtained by applying linguistic deep learning models to human-generated scene descriptions, we identify a widely distributed network of brain regions that encode semantic scene descriptions. Importantly, these semantic embeddings better explain activity in these regions than traditional object category labels. In addition, they are effective predictors of activity despite the fact that the participants did not actively engage in a semantic task, suggesting that visuo-semantic transformations are a default mode of vision. In support of this view, we then show that highly accurate reconstructions of scene captions can be directly linearly decoded from patterns of brain activity. Finally, a recurrent convolutional neural network trained on semantic embeddings further outperforms semantic embeddings in predicting brain activity, providing a mechanistic model of the brain's visuo-semantic transformations. Together, these experimental and computational results suggest that transforming visual input into rich semantic scene descriptions may be a central objective of the visual system, and that focusing efforts on this new objective may lead to improved models of visual information processing in the human brain.
The risk of bias in denoising methods
Jan 26, 2022



Experimental datasets are growing rapidly in size, scope, and detail, but the value of these datasets is limited by unwanted measurement noise. It is therefore tempting to apply analysis techniques that attempt to reduce noise and enhance signals of interest. In this paper, we draw attention to the possibility that denoising methods may introduce bias and lead to incorrect scientific inferences. To present our case, we first review the basic statistical concepts of bias and variance. Denoising techniques typically reduce variance observed across repeated measurements, but this can come at the expense of introducing bias to the average expected outcome. We then conduct three simple simulations that provide concrete examples of how bias may manifest in everyday situations. These simulations reveal several findings that may be surprising and counterintuitive: (i) different methods can be equally effective at reducing variance but some incur bias while others do not, (ii) identifying methods that better recover ground truth does not guarantee the absence of bias, (iii) bias can arise even if one has specific knowledge of properties of the signal of interest. We suggest that researchers should consider and possibly quantify bias before deploying denoising methods on important research data.
NeuroGen: activation optimized image synthesis for discovery neuroscience
May 15, 2021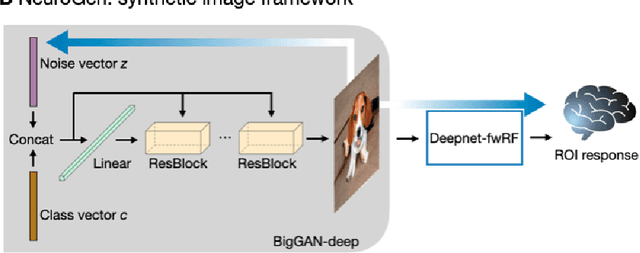
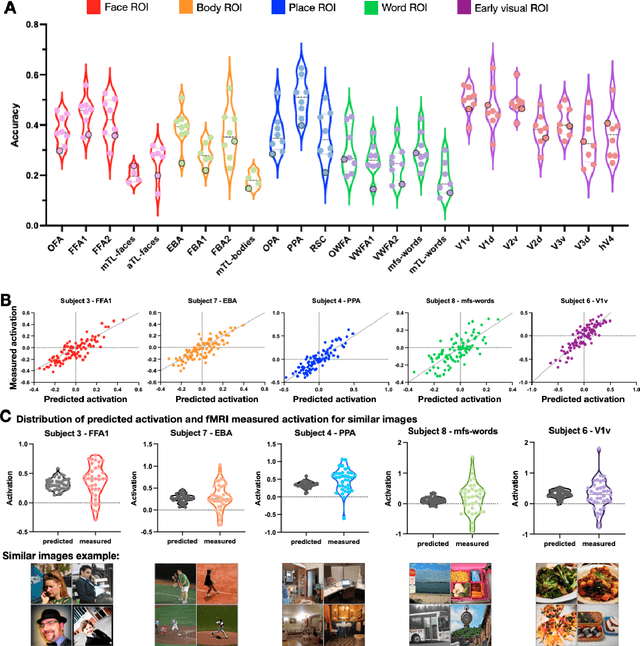

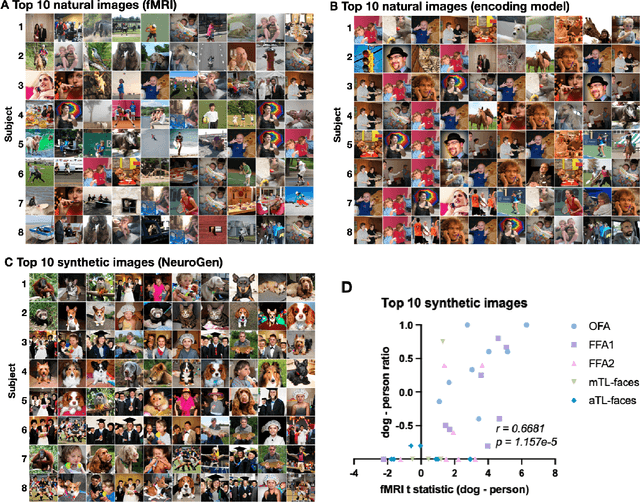
Functional MRI (fMRI) is a powerful technique that has allowed us to characterize visual cortex responses to stimuli, yet such experiments are by nature constructed based on a priori hypotheses, limited to the set of images presented to the individual while they are in the scanner, are subject to noise in the observed brain responses, and may vary widely across individuals. In this work, we propose a novel computational strategy, which we call NeuroGen, to overcome these limitations and develop a powerful tool for human vision neuroscience discovery. NeuroGen combines an fMRI-trained neural encoding model of human vision with a deep generative network to synthesize images predicted to achieve a target pattern of macro-scale brain activation. We demonstrate that the reduction of noise that the encoding model provides, coupled with the generative network's ability to produce images of high fidelity, results in a robust discovery architecture for visual neuroscience. By using only a small number of synthetic images created by NeuroGen, we demonstrate that we can detect and amplify differences in regional and individual human brain response patterns to visual stimuli. We then verify that these discoveries are reflected in the several thousand observed image responses measured with fMRI. We further demonstrate that NeuroGen can create synthetic images predicted to achieve regional response patterns not achievable by the best-matching natural images. The NeuroGen framework extends the utility of brain encoding models and opens up a new avenue for exploring, and possibly precisely controlling, the human visual system.
Fractional ridge regression: a fast, interpretable reparameterization of ridge regression
May 07, 2020


Ridge regression (RR) is a regularization technique that penalizes the L2-norm of the coefficients in linear regression. One of the challenges of using RR is the need to set a hyperparameter ($\alpha$) that controls the amount of regularization. Cross-validation is typically used to select the best $\alpha$ from a set of candidates. However, efficient and appropriate selection of $\alpha$ can be challenging, particularly where large amounts of data are analyzed. Because the selected $\alpha$ depends on the scale of the data and predictors, it is not straightforwardly interpretable. Here, we propose to reparameterize RR in terms of the ratio $\gamma$ between the L2-norms of the regularized and unregularized coefficients. This approach, called fractional RR (FRR), has several benefits: the solutions obtained for different $\gamma$ are guaranteed to vary, guarding against wasted calculations, and automatically span the relevant range of regularization, avoiding the need for arduous manual exploration. We provide an algorithm to solve FRR, as well as open-source software implementations in Python and MATLAB (https://github.com/nrdg/fracridge). We show that the proposed method is fast and scalable for large-scale data problems, and delivers results that are straightforward to interpret and compare across models and datasets.