 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentations in vision and language converge in a shared, multidimensional space of perceived similarities
Jul 29, 2025

Humans can effortlessly describe what they see, yet establishing a shared representational format between vision and language remains a significant challenge. Emerging evidence suggests that human brain representations in both vision and language are well predicted by semantic feature spaces obtained from large language models (LLMs). This raises the possibility that sensory systems converge in their inherent ability to transform their inputs onto shared, embedding-like representational space. However, it remains unclear how such a space manifests in human behaviour. To investigate this, sixty-three participants performed behavioural similarity judgements separately on 100 natural scene images and 100 corresponding sentence captions from the Natural Scenes Dataset. We found that visual and linguistic similarity judgements not only converge at the behavioural level but also predict a remarkably similar network of fMRI brain responses evoked by viewing the natural scene images. Furthermore, computational models trained to map images onto LLM-embeddings outperformed both category-trained and AlexNet controls in explaining the behavioural similarity structure. These findings demonstrate that human visual and linguistic similarity judgements are grounded in a shared, modality-agnostic representational structure that mirrors how the visual system encodes experience. The convergence between sensory and artificial systems suggests a common capacity of how conceptual representations are formed-not as arbitrary products of first order, modality-specific input, but as structured representations that reflect the stable, relational properties of the external world.
Semantic scene descriptions as an objective of human vision
Sep 23, 2022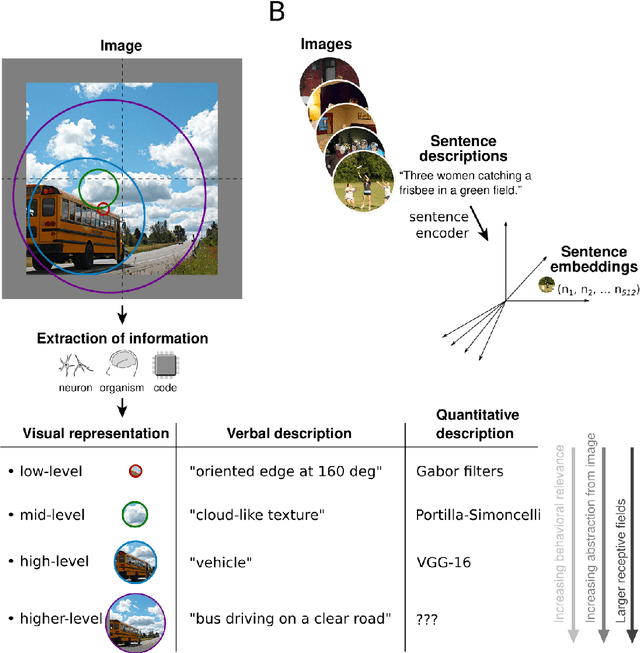
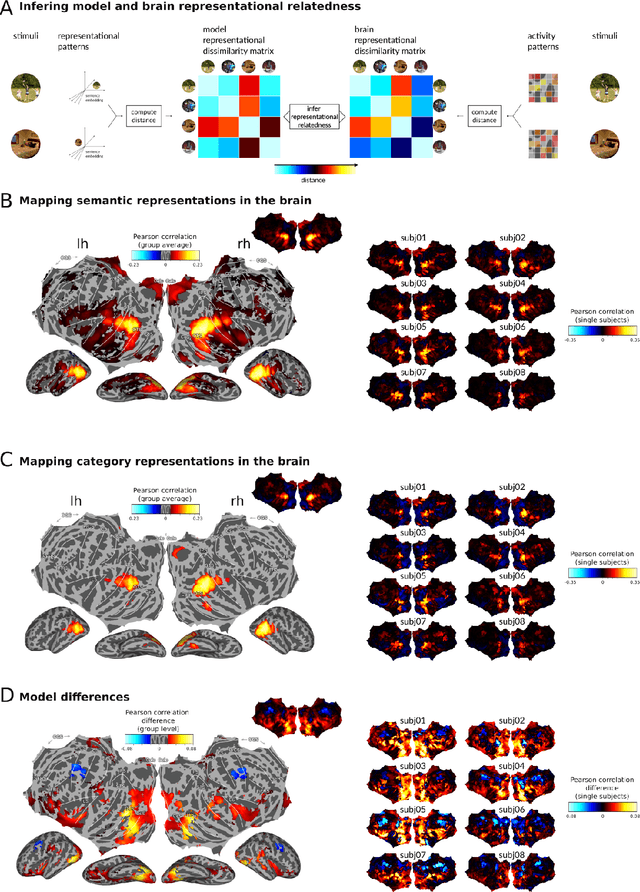
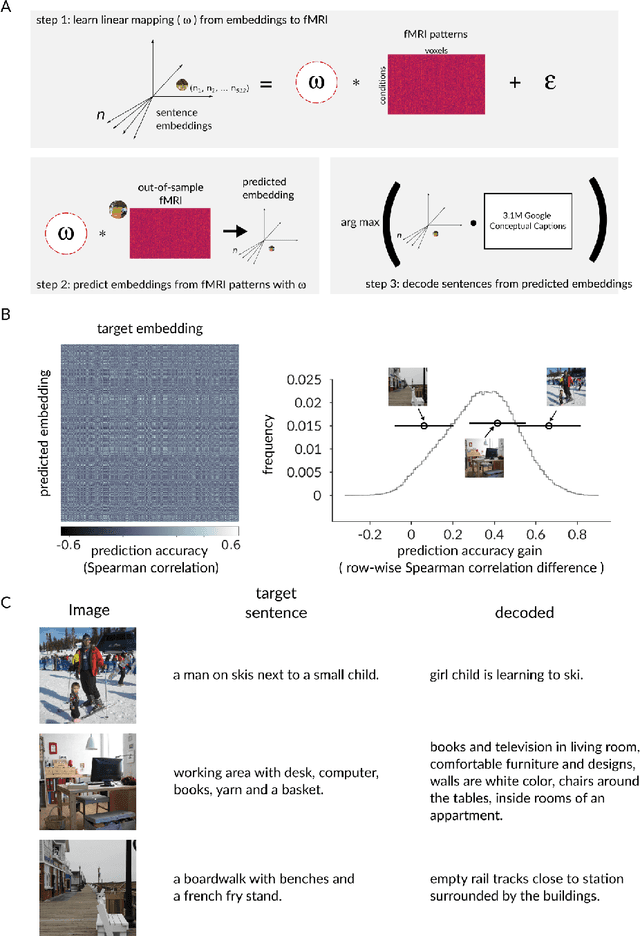
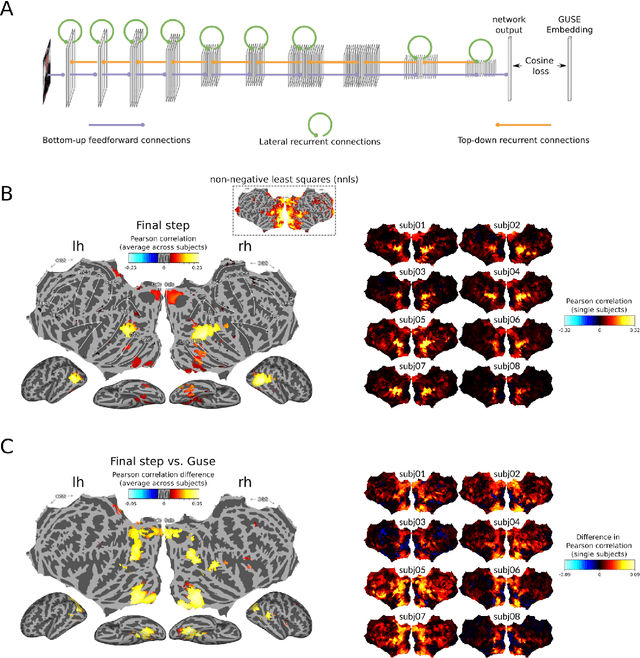
Interpreting the meaning of a visual scene requires not only identification of its constituent objects, but also a rich semantic characterization of object interrelations. Here, we study the neural mechanisms underlying visuo-semantic transformations by applying modern computational techniques to a large-scale 7T fMRI dataset of human brain responses elicited by complex natural scenes. Using semantic embeddings obtained by applying linguistic deep learning models to human-generated scene descriptions, we identify a widely distributed network of brain regions that encode semantic scene descriptions. Importantly, these semantic embeddings better explain activity in these regions than traditional object category labels. In addition, they are effective predictors of activity despite the fact that the participants did not actively engage in a semantic task, suggesting that visuo-semantic transformations are a default mode of vision. In support of this view, we then show that highly accurate reconstructions of scene captions can be directly linearly decoded from patterns of brain activity. Finally, a recurrent convolutional neural network trained on semantic embeddings further outperforms semantic embeddings in predicting brain activity, providing a mechanistic model of the brain's visuo-semantic transformations. Together, these experimental and computational results suggest that transforming visual input into rich semantic scene descriptions may be a central objective of the visual system, and that focusing efforts on this new objective may lead to improved models of visual information processing in the human brain.