 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Umwelt Representation Hypothesis: Rethinking Universality
Apr 20, 2026Recent studies reveal striking representational alignment between artificial neural networks (ANNs) and biological brains, leading to proposals that all sufficiently capable systems converge on universal representations of reality. Here, we argue that this claim of Universality is premature. We introduce the Umwelt Representation Hypothesis (URH), proposing that alignment arises not from convergence toward a single global optimum, but from overlap in ecological constraints under which systems develop. We review empirical evidence showing that representational differences between species, individuals, and ANNs are systematic and adaptive, which is difficult to reconcile with Universality. Finally, we reframe ANN model comparison as a method for mapping clusters of alignment in ecological constraint space rather than searching for a single optimal world model.
Predicting upcoming visual features during eye movements yields scene representations aligned with human visual cortex
Nov 16, 2025

Scenes are complex, yet structured collections of parts, including objects and surfaces, that exhibit spatial and semantic relations to one another. An effective visual system therefore needs unified scene representations that relate scene parts to their location and their co-occurrence. We hypothesize that this structure can be learned self-supervised from natural experience by exploiting the temporal regularities of active vision: each fixation reveals a locally-detailed glimpse that is statistically related to the previous one via co-occurrence and saccade-conditioned spatial regularities. We instantiate this idea with Glimpse Prediction Networks (GPNs) -- recurrent models trained to predict the feature embedding of the next glimpse along human-like scanpaths over natural scenes. GPNs successfully learn co-occurrence structure and, when given relative saccade location vectors, show sensitivity to spatial arrangement. Furthermore, recurrent variants of GPNs were able to integrate information across glimpses into a unified scene representation. Notably, these scene representations align strongly with human fMRI responses during natural-scene viewing across mid/high-level visual cortex. Critically, GPNs outperform architecture- and dataset-matched controls trained with explicit semantic objectives, and match or exceed strong modern vision baselines, leaving little unique variance for those alternatives. These results establish next-glimpse prediction during active vision as a biologically plausible, self-supervised route to brain-aligned scene representations learned from natural visual experience.
Representations in vision and language converge in a shared, multidimensional space of perceived similarities
Jul 29, 2025

Humans can effortlessly describe what they see, yet establishing a shared representational format between vision and language remains a significant challenge. Emerging evidence suggests that human brain representations in both vision and language are well predicted by semantic feature spaces obtained from large language models (LLMs). This raises the possibility that sensory systems converge in their inherent ability to transform their inputs onto shared, embedding-like representational space. However, it remains unclear how such a space manifests in human behaviour. To investigate this, sixty-three participants performed behavioural similarity judgements separately on 100 natural scene images and 100 corresponding sentence captions from the Natural Scenes Dataset. We found that visual and linguistic similarity judgements not only converge at the behavioural level but also predict a remarkably similar network of fMRI brain responses evoked by viewing the natural scene images. Furthermore, computational models trained to map images onto LLM-embeddings outperformed both category-trained and AlexNet controls in explaining the behavioural similarity structure. These findings demonstrate that human visual and linguistic similarity judgements are grounded in a shared, modality-agnostic representational structure that mirrors how the visual system encodes experience. The convergence between sensory and artificial systems suggests a common capacity of how conceptual representations are formed-not as arbitrary products of first order, modality-specific input, but as structured representations that reflect the stable, relational properties of the external world.
Characterising representation dynamics in recurrent neural networks for object recognition
Aug 23, 2023Recurrent neural networks (RNNs) have yielded promising results for both recognizing objects in challenging conditions and modeling aspects of primate vision. However, the representational dynamics of recurrent computations remain poorly understood, especially in large-scale visual models. Here, we studied such dynamics in RNNs trained for object classification on MiniEcoset, a novel subset of ecoset. We report two main insights. First, upon inference, representations continued to evolve after correct classification, suggesting a lack of the notion of being ``done with classification''. Second, focusing on ``readout zones'' as a way to characterize the activation trajectories, we observe that misclassified representations exhibit activation patterns with lower L2 norm, and are positioned more peripherally in the readout zones. Such arrangements help the misclassified representations move into the correct zones as time progresses. Our findings generalize to networks with lateral and top-down connections, and include both additive and multiplicative interactions with the bottom-up sweep. The results therefore contribute to a general understanding of RNN dynamics in naturalistic tasks. We hope that the analysis framework will aid future investigations of other types of RNNs, including understanding of representational dynamics in primate vision.
End-to-end topographic networks as models of cortical map formation and human visual behaviour: moving beyond convolutions
Aug 18, 2023Computational models are an essential tool for understanding the origin and functions of the topographic organisation of the primate visual system. Yet, vision is most commonly modelled by convolutional neural networks that ignore topography by learning identical features across space. Here, we overcome this limitation by developing All-Topographic Neural Networks (All-TNNs). Trained on visual input, several features of primate topography emerge in All-TNNs: smooth orientation maps and cortical magnification in their first layer, and category-selective areas in their final layer. In addition, we introduce a novel dataset of human spatial biases in object recognition, which enables us to directly link models to behaviour. We demonstrate that All-TNNs significantly better align with human behaviour than previous state-of-the-art convolutional models due to their topographic nature. All-TNNs thereby mark an important step forward in understanding the spatial organisation of the visual brain and how it mediates visual behaviour.
Semantic scene descriptions as an objective of human vision
Sep 23, 2022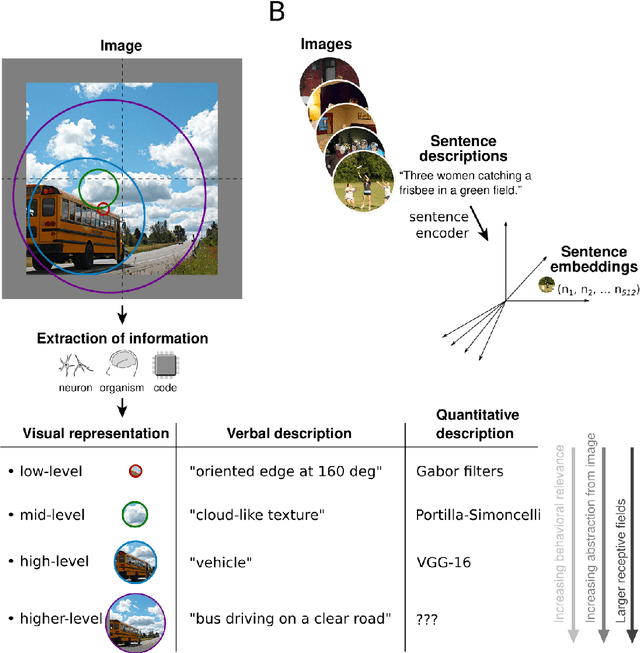
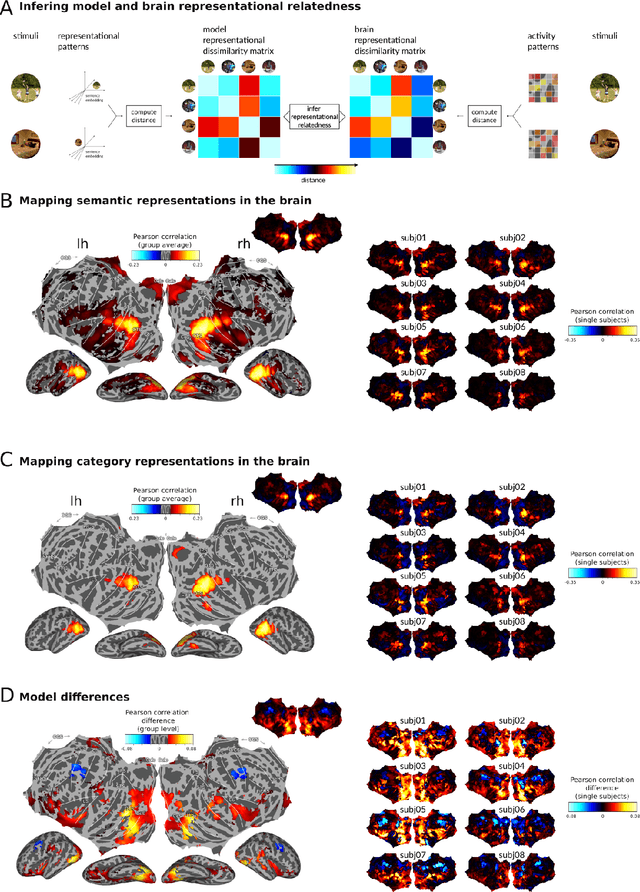
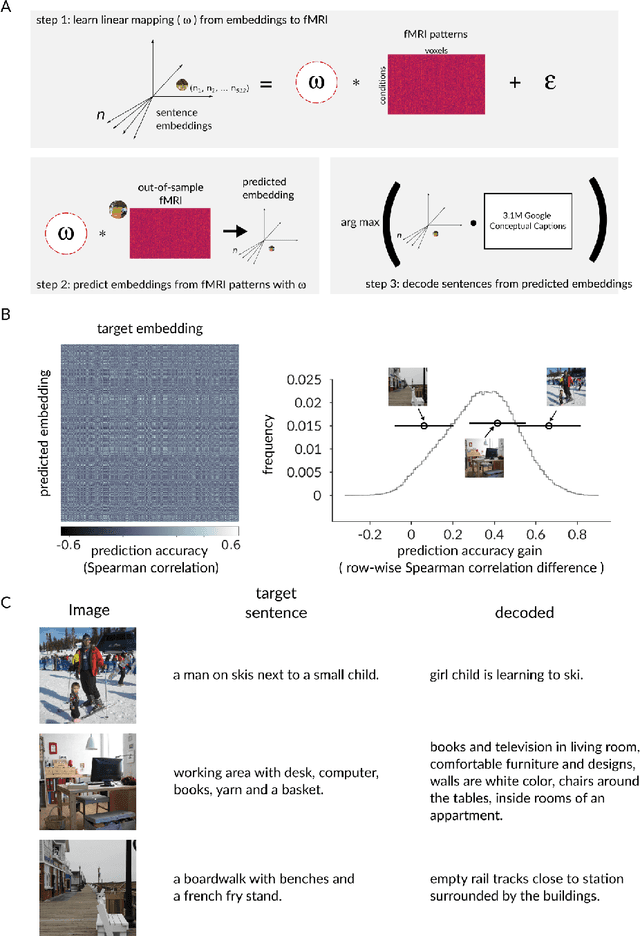
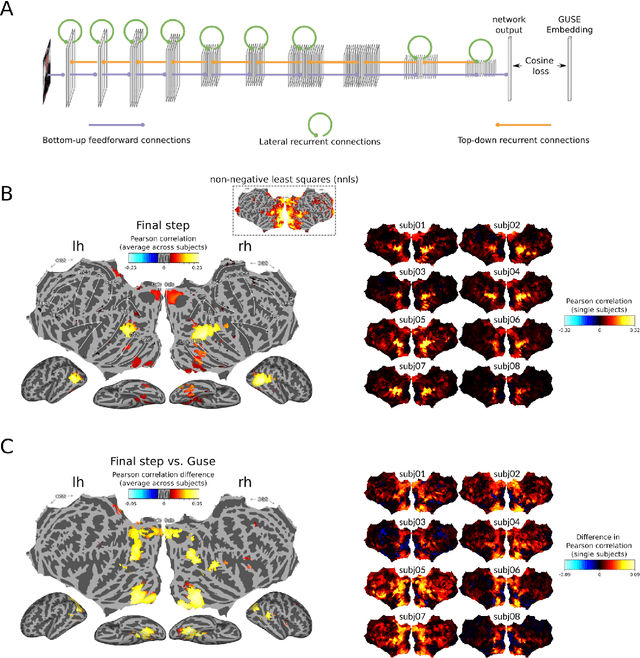
Interpreting the meaning of a visual scene requires not only identification of its constituent objects, but also a rich semantic characterization of object interrelations. Here, we study the neural mechanisms underlying visuo-semantic transformations by applying modern computational techniques to a large-scale 7T fMRI dataset of human brain responses elicited by complex natural scenes. Using semantic embeddings obtained by applying linguistic deep learning models to human-generated scene descriptions, we identify a widely distributed network of brain regions that encode semantic scene descriptions. Importantly, these semantic embeddings better explain activity in these regions than traditional object category labels. In addition, they are effective predictors of activity despite the fact that the participants did not actively engage in a semantic task, suggesting that visuo-semantic transformations are a default mode of vision. In support of this view, we then show that highly accurate reconstructions of scene captions can be directly linearly decoded from patterns of brain activity. Finally, a recurrent convolutional neural network trained on semantic embeddings further outperforms semantic embeddings in predicting brain activity, providing a mechanistic model of the brain's visuo-semantic transformations. Together, these experimental and computational results suggest that transforming visual input into rich semantic scene descriptions may be a central objective of the visual system, and that focusing efforts on this new objective may lead to improved models of visual information processing in the human brain.