 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust and Terror: Hazards in Text Reveal Negatively Biased Credulity and Partisan Negativity Bias
May 28, 2024



Socio-linguistic indicators of text, such as emotion or sentiment, are often extracted using neural networks in order to better understand features of social media. One indicator that is often overlooked, however, is the presence of hazards within text. Recent psychological research suggests that statements about hazards are more believable than statements about benefits (a property known as negatively biased credulity), and that political liberals and conservatives differ in how often they share hazards. Here, we develop a new model to detect information concerning hazards, trained on a new collection of annotated X posts, as well as urban legends annotated in previous work. We show that not only does this model perform well (outperforming, e.g., zero-shot human annotator proxies, such as GPT-4) but that the hazard information it extracts is not strongly correlated with other indicators, namely moral outrage, sentiment, emotions, and threat words. (That said, consonant with expectations, hazard information does correlate positively with such emotions as fear, and negatively with emotions like joy.) We then apply this model to three datasets: X posts about COVID-19, X posts about the 2023 Hamas-Israel war, and a new expanded collection of urban legends. From these data, we uncover words associated with hazards unique to each dataset as well as differences in this language between groups of users, such as conservatives and liberals, which informs what these groups perceive as hazards. We further show that information about hazards peaks in frequency after major hazard events, and therefore acts as an automated indicator of such events. Finally, we find that information about hazards is especially prevalent in urban legends, which is consistent with previous work that finds that reports of hazards are more likely to be both believed and transmitted.
Large Language Models Reveal Information Operation Goals, Tactics, and Narrative Frames
May 06, 2024



Adversarial information operations can destabilize societies by undermining fair elections, manipulating public opinions on policies, and promoting scams. Despite their widespread occurrence and potential impacts, our understanding of influence campaigns is limited by manual analysis of messages and subjective interpretation of their observable behavior. In this paper, we explore whether these limitations can be mitigated with large language models (LLMs), using GPT-3.5 as a case-study for coordinated campaign annotation. We first use GPT-3.5 to scrutinize 126 identified information operations spanning over a decade. We utilize a number of metrics to quantify the close (if imperfect) agreement between LLM and ground truth descriptions. We next extract coordinated campaigns from two large multilingual datasets from X (formerly Twitter) that respectively discuss the 2022 French election and 2023 Balikaran Philippine-U.S. military exercise in 2023. For each coordinated campaign, we use GPT-3.5 to analyze posts related to a specific concern and extract goals, tactics, and narrative frames, both before and after critical events (such as the date of an election). While the GPT-3.5 sometimes disagrees with subjective interpretation, its ability to summarize and interpret demonstrates LLMs' potential to extract higher-order indicators from text to provide a more complete picture of the information campaigns compared to previous methods.
SoMeR: Multi-View User Representation Learning for Social Media
May 02, 2024



User representation learning aims to capture user preferences, interests, and behaviors in low-dimensional vector representations. These representations have widespread applications in recommendation systems and advertising; however, existing methods typically rely on specific features like text content, activity patterns, or platform metadata, failing to holistically model user behavior across different modalities. To address this limitation, we propose SoMeR, a Social Media user Representation learning framework that incorporates temporal activities, text content, profile information, and network interactions to learn comprehensive user portraits. SoMeR encodes user post streams as sequences of timestamped textual features, uses transformers to embed this along with profile data, and jointly trains with link prediction and contrastive learning objectives to capture user similarity. We demonstrate SoMeR's versatility through two applications: 1) Identifying inauthentic accounts involved in coordinated influence operations by detecting users posting similar content simultaneously, and 2) Measuring increased polarization in online discussions after major events by quantifying how users with different beliefs moved farther apart in the embedding space. SoMeR's ability to holistically model users enables new solutions to important problems around disinformation, societal tensions, and online behavior understanding.
Data-Driven Estimation of Heterogeneous Treatment Effects
Jan 16, 2023



Estimating how a treatment affects different individuals, known as heterogeneous treatment effect estimation, is an important problem in empirical sciences. In the last few years, there has been a considerable interest in adapting machine learning algorithms to the problem of estimating heterogeneous effects from observational and experimental data. However, these algorithms often make strong assumptions about the observed features in the data and ignore the structure of the underlying causal model, which can lead to biased estimation. At the same time, the underlying causal mechanism is rarely known in real-world datasets, making it hard to take it into consideration. In this work, we provide a survey of state-of-the-art data-driven methods for heterogeneous treatment effect estimation using machine learning, broadly categorizing them as methods that focus on counterfactual prediction and methods that directly estimate the causal effect. We also provide an overview of a third category of methods which rely on structural causal models and learn the model structure from data. Our empirical evaluation under various underlying structural model mechanisms shows the advantages and deficiencies of existing estimators and of the metrics for measuring their performance.
Using Emotion Embeddings to Transfer Knowledge Between Emotions, Languages, and Annotation Formats
Oct 31, 2022The need for emotional inference from text continues to diversify as more and more disciplines integrate emotions into their theories and applications. These needs include inferring different emotion types, handling multiple languages, and different annotation formats. A shared model between different configurations would enable the sharing of knowledge and a decrease in training costs, and would simplify the process of deploying emotion recognition models in novel environments. In this work, we study how we can build a single model that can transition between these different configurations by leveraging multilingual models and Demux, a transformer-based model whose input includes the emotions of interest, enabling us to dynamically change the emotions predicted by the model. Demux also produces emotion embeddings, and performing operations on them allows us to transition to clusters of emotions by pooling the embeddings of each cluster. We show that Demux can simultaneously transfer knowledge in a zero-shot manner to a new language, to a novel annotation format and to unseen emotions. Code is available at https://github.com/gchochla/Demux-MEmo .
Leveraging Label Correlations in a Multi-label Setting: A Case Study in Emotion
Oct 28, 2022


Detecting emotions expressed in text has become critical to a range of fields. In this work, we investigate ways to exploit label correlations in multi-label emotion recognition models to improve emotion detection. First, we develop two modeling approaches to the problem in order to capture word associations of the emotion words themselves, by either including the emotions in the input, or by leveraging Masked Language Modeling (MLM). Second, we integrate pairwise constraints of emotion representations as regularization terms alongside the classification loss of the models. We split these terms into two categories, local and global. The former dynamically change based on the gold labels, while the latter remain static during training. We demonstrate state-of-the-art performance across Spanish, English, and Arabic in SemEval 2018 Task 1 E-c using monolingual BERT-based models. On top of better performance, we also demonstrate improved robustness. Code is available at https://github.com/gchochla/Demux-MEmo.
Quantifying How Hateful Communities Radicalize Online Users
Oct 02, 2022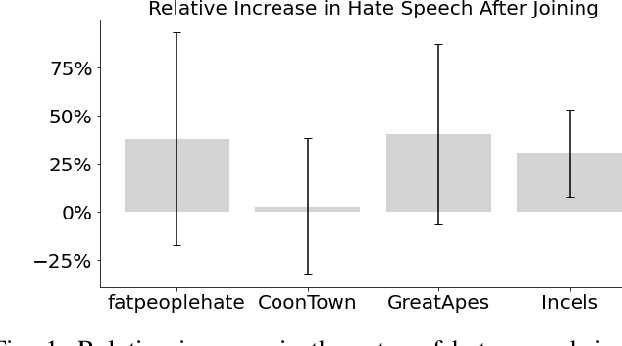
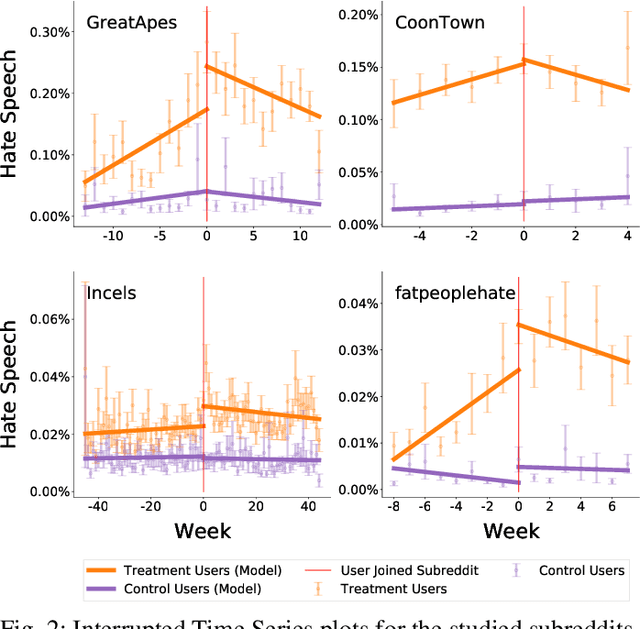
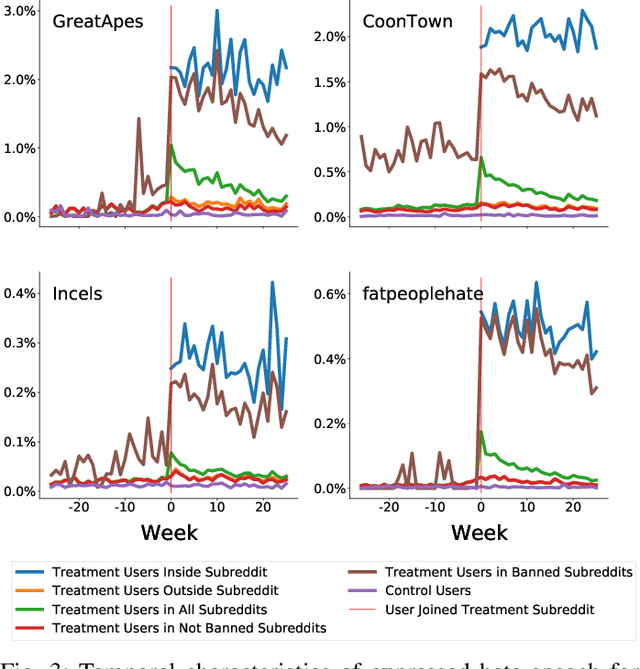
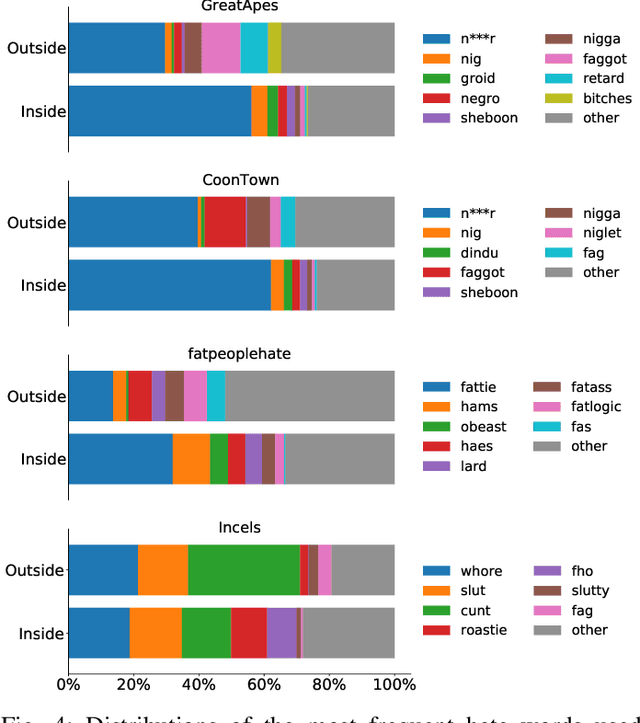
While online social media offers a way for ignored or stifled voices to be heard, it also allows users a platform to spread hateful speech. Such speech usually originates in fringe communities, yet it can spill over into mainstream channels. In this paper, we measure the impact of joining fringe hateful communities in terms of hate speech propagated to the rest of the social network. We leverage data from Reddit to assess the effect of joining one type of echo chamber: a digital community of like-minded users exhibiting hateful behavior. We measure members' usage of hate speech outside the studied community before and after they become active participants. Using Interrupted Time Series (ITS) analysis as a causal inference method, we gauge the spillover effect, in which hateful language from within a certain community can spread outside that community by using the level of out-of-community hate word usage as a proxy for learned hate. We investigate four different Reddit sub-communities (subreddits) covering three areas of hate speech: racism, misogyny and fat-shaming. In all three cases we find an increase in hate speech outside the originating community, implying that joining such community leads to a spread of hate speech throughout the platform. Moreover, users are found to pick up this new hateful speech for months after initially joining the community. We show that the harmful speech does not remain contained within the community. Our results provide new evidence of the harmful effects of echo chambers and the potential benefit of moderating them to reduce adoption of hateful speech.
Inferring topological transitions in pattern-forming processes with self-supervised learning
Mar 19, 2022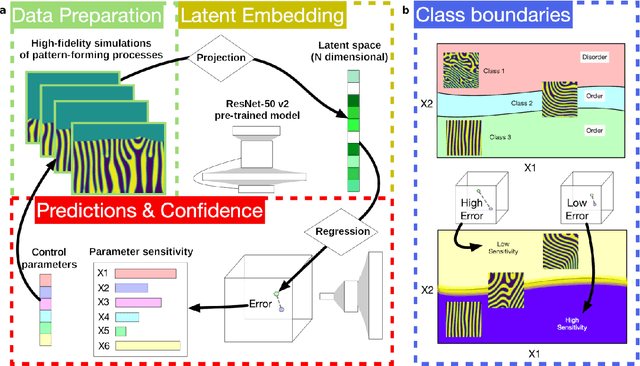
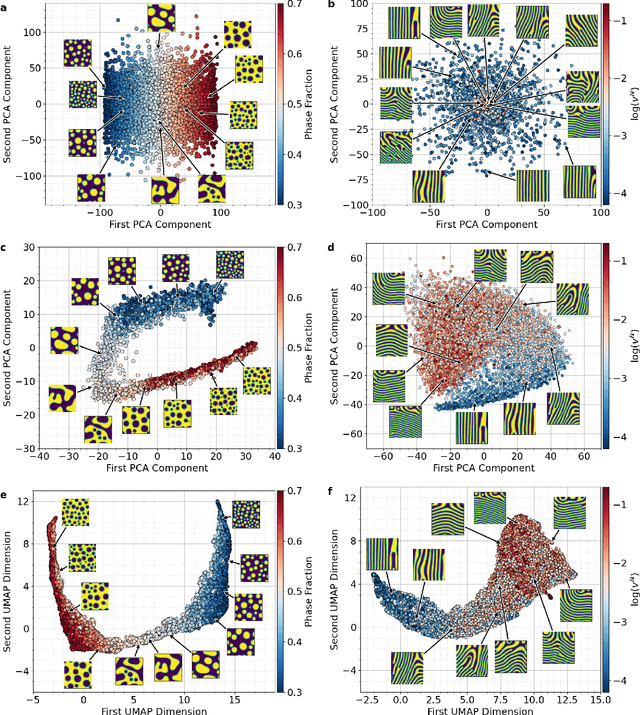
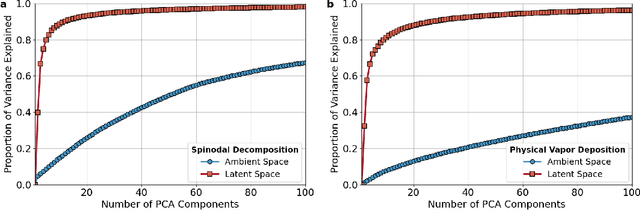
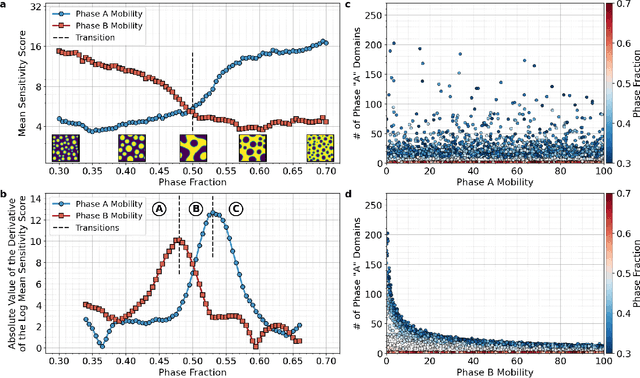
The identification and classification of transitions in topological and microstructural regimes in pattern-forming processes is critical for understanding and fabricating microstructurally precise novel materials in many application domains. Unfortunately, relevant microstructure transitions may depend on process parameters in subtle and complex ways that are not captured by the classic theory of phase transition. While supervised machine learning methods may be useful for identifying transition regimes, they need labels which require prior knowledge of order parameters or relevant structures. Motivated by the universality principle for dynamical systems, we instead use a self-supervised approach to solve the inverse problem of predicting process parameters from observed microstructures using neural networks. This approach does not require labeled data about the target task of predicting microstructure transitions. We show that the difficulty of performing this prediction task is related to the goal of discovering microstructure regimes, because qualitative changes in microstructural patterns correspond to changes in uncertainty for our self-supervised prediction problem. We demonstrate the value of our approach by automatically discovering transitions in microstructural regimes in two distinct pattern-forming processes: the spinodal decomposition of a two-phase mixture and the formation of concentration modulations of binary alloys during physical vapor deposition of thin films. This approach opens a promising path forward for discovering and understanding unseen or hard-to-detect transition regimes, and ultimately for controlling complex pattern-forming processes.
Emergent Instabilities in Algorithmic Feedback Loops
Jan 18, 2022Algorithms that aid human tasks, such as recommendation systems, are ubiquitous. They appear in everything from social media to streaming videos to online shopping. However, the feedback loop between people and algorithms is poorly understood and can amplify cognitive and social biases (algorithmic confounding), leading to unexpected outcomes. In this work, we explore algorithmic confounding in collaborative filtering-based recommendation algorithms through teacher-student learning simulations. Namely, a student collaborative filtering-based model, trained on simulated choices, is used by the recommendation algorithm to recommend items to agents. Agents might choose some of these items, according to an underlying teacher model, with new choices then fed back into the student model as new training data (approximating online machine learning). These simulations demonstrate how algorithmic confounding produces erroneous recommendations which in turn lead to instability, i.e., wide variations in an item's popularity between each simulation realization. We use the simulations to demonstrate a novel approach to training collaborative filtering models that can create more stable and accurate recommendations. Our methodology is general enough that it can be extended to other socio-technical systems in order to better quantify and improve the stability of algorithms. These results highlight the need to account for emergent behaviors from interactions between people and algorithms.
Heterogeneous Effects of Software Patches in a Multiplayer Online Battle Arena Game
Oct 27, 2021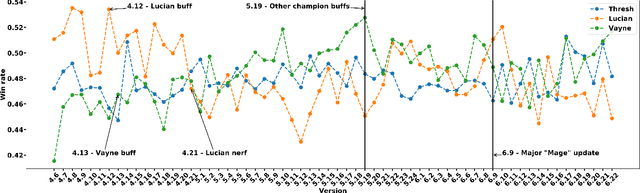
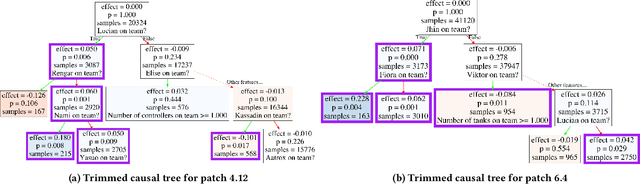

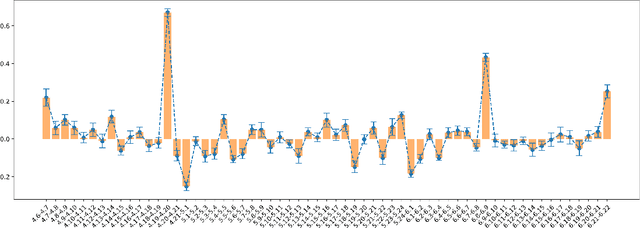
The popularity of online gaming has grown dramatically, driven in part by streaming and the billion-dollar e-sports industry. Online games regularly update their software to fix bugs, add functionality that improve the game's look and feel, and change the game mechanics to keep the games fun and challenging. An open question, however, is the impact of these changes on player performance and game balance, as well as how players adapt to these sudden changes. To address these questions, we use causal inference to measure the impact of software patches to League of Legends, a popular team-based multiplayer online game. We show that game patches have substantially different impacts on players depending on their skill level and whether they take breaks between games. We find that the gap between good and bad players increases after a patch, despite efforts to make gameplay more equal. Moreover, longer between-game breaks tend to improve player performance after patches. Overall, our results highlight the utility of causal inference, and specifically heterogeneous treatment effect estimation, as a tool to quantify the complex mechanisms of game balance and its interplay with players' performance.
* 9 pages, 11 figures