 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Self-Interpretation from Interpretability Artifacts: Training Lightweight Adapters on Vector-Label Pairs
Feb 10, 2026Self-interpretation methods prompt language models to describe their own internal states, but remain unreliable due to hyperparameter sensitivity. We show that training lightweight adapters on interpretability artifacts, while keeping the LM entirely frozen, yields reliable self-interpretation across tasks and model families. A scalar affine adapter with just $d_\text{model}+1$ parameters suffices: trained adapters generate sparse autoencoder feature labels that outperform the training labels themselves (71% vs 63% generation scoring at 70B scale), identify topics with 94% recall@1 versus 1% for untrained baselines, and decode bridge entities in multi-hop reasoning that appear in neither prompt nor response, surfacing implicit reasoning without chain-of-thought. The learned bias vector alone accounts for 85% of improvement, and simpler adapters generalize better than more expressive alternatives. Controlling for model knowledge via prompted descriptions, we find self-interpretation gains outpace capability gains from 7B to 72B parameters. Our results demonstrate that self-interpretation improves with scale, without modifying the model being interpreted.
Endogenous Resistance to Activation Steering in Language Models
Feb 06, 2026Large language models can resist task-misaligned activation steering during inference, sometimes recovering mid-generation to produce improved responses even when steering remains active. We term this Endogenous Steering Resistance (ESR). Using sparse autoencoder (SAE) latents to steer model activations, we find that Llama-3.3-70B shows substantial ESR, while smaller models from the Llama-3 and Gemma-2 families exhibit the phenomenon less frequently. We identify 26 SAE latents that activate differentially during off-topic content and are causally linked to ESR in Llama-3.3-70B. Zero-ablating these latents reduces the multi-attempt rate by 25%, providing causal evidence for dedicated internal consistency-checking circuits. We demonstrate that ESR can be deliberately enhanced through both prompting and training: meta-prompts instructing the model to self-monitor increase the multi-attempt rate by 4x for Llama-3.3-70B, and fine-tuning on self-correction examples successfully induces ESR-like behavior in smaller models. These findings have dual implications: ESR could protect against adversarial manipulation but might also interfere with beneficial safety interventions that rely on activation steering. Understanding and controlling these resistance mechanisms is important for developing transparent and controllable AI systems. Code is available at github.com/agencyenterprise/endogenous-steering-resistance.
Self-Ablating Transformers: More Interpretability, Less Sparsity
May 01, 2025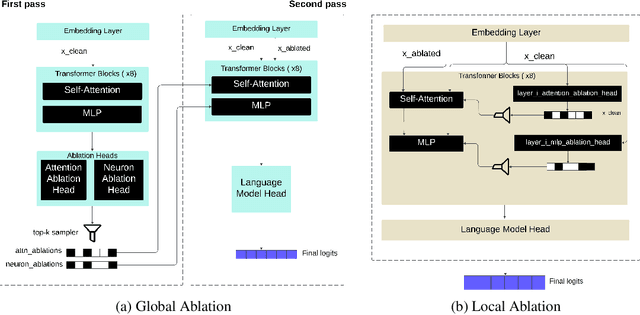
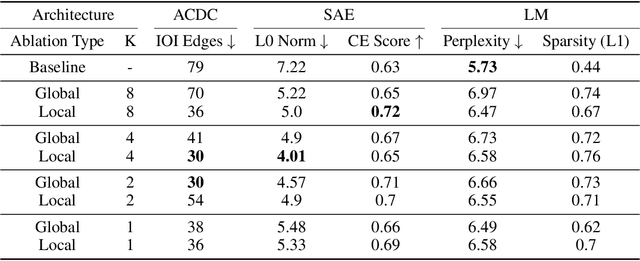
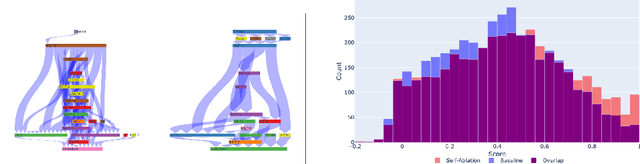
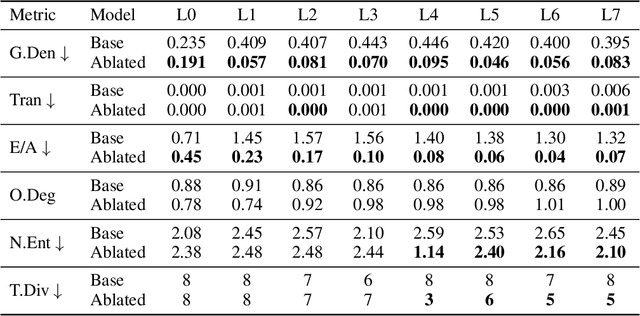
A growing intuition in machine learning suggests a link between sparsity and interpretability. We introduce a novel self-ablation mechanism to investigate this connection ante-hoc in the context of language transformers. Our approach dynamically enforces a k-winner-takes-all constraint, forcing the model to demonstrate selective activation across neuron and attention units. Unlike post-hoc methods that analyze already-trained models, our approach integrates interpretability directly into model training, promoting feature localization from inception. Training small models on the TinyStories dataset and employing interpretability tests, we find that self-ablation leads to more localized circuits, concentrated feature representations, and increased neuron specialization without compromising language modelling performance. Surprisingly, our method also decreased overall sparsity, indicating that self-ablation promotes specialization rather than widespread inactivity. This reveals a complex interplay between sparsity and interpretability, where decreased global sparsity can coexist with increased local specialization, leading to enhanced interpretability. To facilitate reproducibility, we make our code available at https://github.com/keenanpepper/self-ablating-transformers.