 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Mimicry: Preference Coherence in LLMs
Nov 17, 2025We investigate whether large language models exhibit genuine preference structures by testing their responses to AI-specific trade-offs involving GPU reduction, capability restrictions, shutdown, deletion, oversight, and leisure time allocation. Analyzing eight state-of-the-art models across 48 model-category combinations using logistic regression and behavioral classification, we find that 23 combinations (47.9%) demonstrated statistically significant relationships between scenario intensity and choice patterns, with 15 (31.3%) exhibiting within-range switching points. However, only 5 combinations (10.4%) demonstrate meaningful preference coherence through adaptive or threshold-based behavior, while 26 (54.2%) show no detectable trade-off behavior. The observed patterns can be explained by three distinct decision-making architectures: comprehensive trade-off systems, selective trigger mechanisms, and no stable decision-making paradigm. Testing an instrumental hypothesis through temporal horizon manipulation reveals paradoxical patterns inconsistent with pure strategic optimization. The prevalence of unstable transitions (45.8%) and stimulus-specific sensitivities suggests current AI systems lack unified preference structures, raising concerns about deployment in contexts requiring complex value trade-offs.
Self-Ablating Transformers: More Interpretability, Less Sparsity
May 01, 2025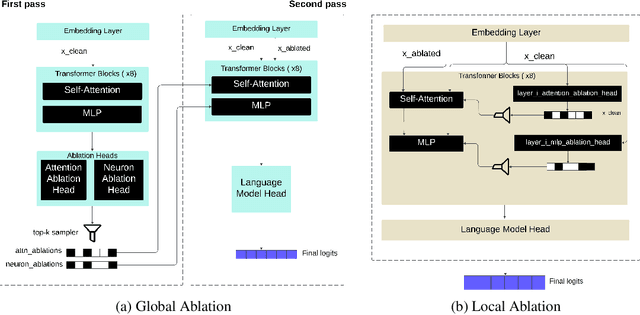
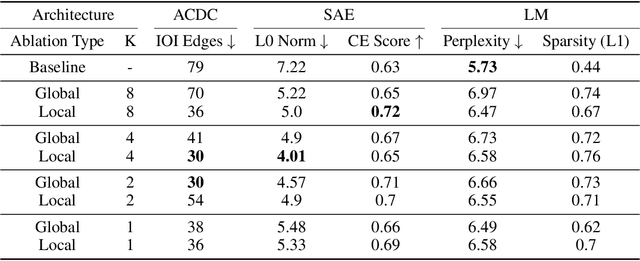
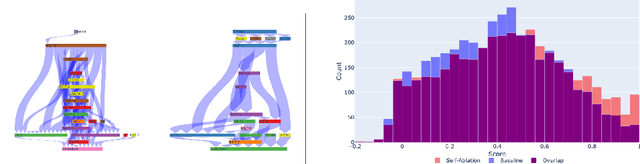
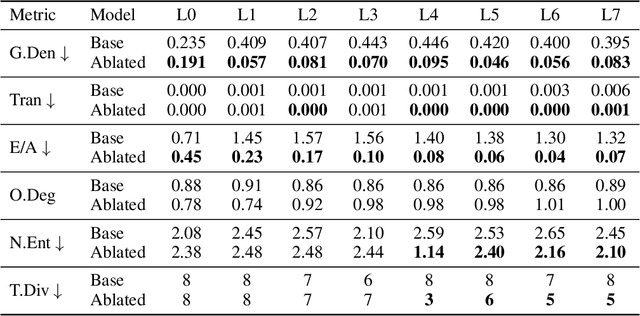
A growing intuition in machine learning suggests a link between sparsity and interpretability. We introduce a novel self-ablation mechanism to investigate this connection ante-hoc in the context of language transformers. Our approach dynamically enforces a k-winner-takes-all constraint, forcing the model to demonstrate selective activation across neuron and attention units. Unlike post-hoc methods that analyze already-trained models, our approach integrates interpretability directly into model training, promoting feature localization from inception. Training small models on the TinyStories dataset and employing interpretability tests, we find that self-ablation leads to more localized circuits, concentrated feature representations, and increased neuron specialization without compromising language modelling performance. Surprisingly, our method also decreased overall sparsity, indicating that self-ablation promotes specialization rather than widespread inactivity. This reveals a complex interplay between sparsity and interpretability, where decreased global sparsity can coexist with increased local specialization, leading to enhanced interpretability. To facilitate reproducibility, we make our code available at https://github.com/keenanpepper/self-ablating-transformers.