 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Temporal Encoding Network for Video Instance-level Human Parsing
Aug 10, 2018
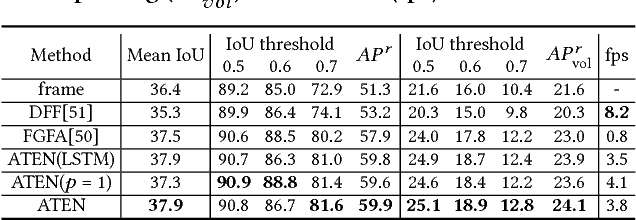
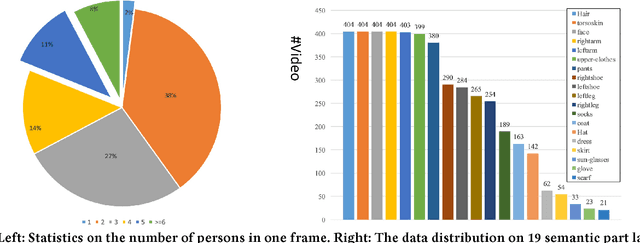
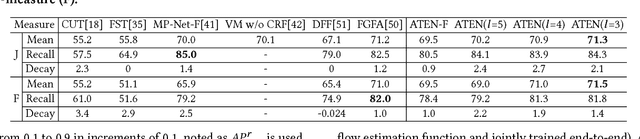
Beyond the existing single-person and multiple-person human parsing tasks in static images, this paper makes the first attempt to investigate a more realistic video instance-level human parsing that simultaneously segments out each person instance and parses each instance into more fine-grained parts (e.g., head, leg, dress). We introduce a novel Adaptive Temporal Encoding Network (ATEN) that alternatively performs temporal encoding among key frames and flow-guided feature propagation from other consecutive frames between two key frames. Specifically, ATEN first incorporates a Parsing-RCNN to produce the instance-level parsing result for each key frame, which integrates both the global human parsing and instance-level human segmentation into a unified model. To balance between accuracy and efficiency, the flow-guided feature propagation is used to directly parse consecutive frames according to their identified temporal consistency with key frames. On the other hand, ATEN leverages the convolution gated recurrent units (convGRU) to exploit temporal changes over a series of key frames, which are further used to facilitate the frame-level instance-level parsing. By alternatively performing direct feature propagation between consistent frames and temporal encoding network among key frames, our ATEN achieves a good balance between frame-level accuracy and time efficiency, which is a common crucial problem in video object segmentation research. To demonstrate the superiority of our ATEN, extensive experiments are conducted on the most popular video segmentation benchmark (DAVIS) and a newly collected Video Instance-level Parsing (VIP) dataset, which is the first video instance-level human parsing dataset comprised of 404 sequences and over 20k frames with instance-level and pixel-wise annotations.
Instance-level Human Parsing via Part Grouping Network
Aug 01, 2018
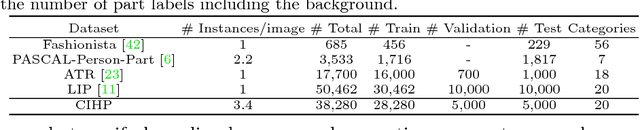

Instance-level human parsing towards real-world human analysis scenarios is still under-explored due to the absence of sufficient data resources and technical difficulty in parsing multiple instances in a single pass. Several related works all follow the "parsing-by-detection" pipeline that heavily relies on separately trained detection models to localize instances and then performs human parsing for each instance sequentially. Nonetheless, two discrepant optimization targets of detection and parsing lead to suboptimal representation learning and error accumulation for final results. In this work, we make the first attempt to explore a detection-free Part Grouping Network (PGN) for efficiently parsing multiple people in an image in a single pass. Our PGN reformulates instance-level human parsing as two twinned sub-tasks that can be jointly learned and mutually refined via a unified network: 1) semantic part segmentation for assigning each pixel as a human part (e.g., face, arms); 2) instance-aware edge detection to group semantic parts into distinct person instances. Thus the shared intermediate representation would be endowed with capabilities in both characterizing fine-grained parts and inferring instance belongings of each part. Finally, a simple instance partition process is employed to get final results during inference. We conducted experiments on PASCAL-Person-Part dataset and our PGN outperforms all state-of-the-art methods. Furthermore, we show its superiority on a newly collected multi-person parsing dataset (CIHP) including 38,280 diverse images, which is the largest dataset so far and can facilitate more advanced human analysis. The CIHP benchmark and our source code are available at http://sysu-hcp.net/lip/.
Look into Person: Joint Body Parsing & Pose Estimation Network and A New Benchmark
Apr 05, 2018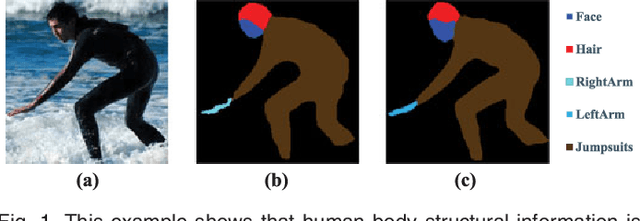
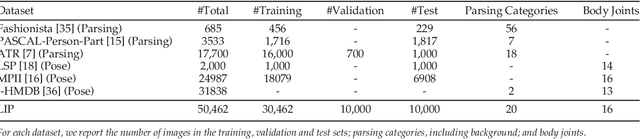

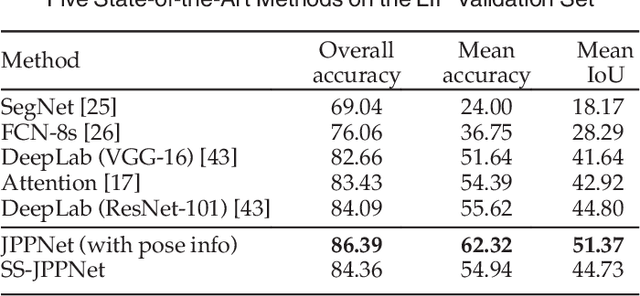
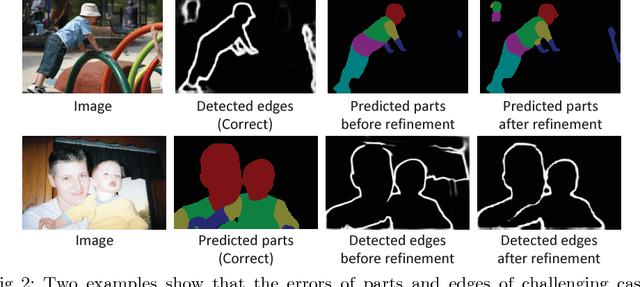
Human parsing and pose estimation have recently received considerable interest due to their substantial application potentials. However, the existing datasets have limited numbers of images and annotations and lack a variety of human appearances and coverage of challenging cases in unconstrained environments. In this paper, we introduce a new benchmark named "Look into Person (LIP)" that provides a significant advancement in terms of scalability, diversity, and difficulty, which are crucial for future developments in human-centric analysis. This comprehensive dataset contains over 50,000 elaborately annotated images with 19 semantic part labels and 16 body joints, which are captured from a broad range of viewpoints, occlusions, and background complexities. Using these rich annotations, we perform detailed analyses of the leading human parsing and pose estimation approaches, thereby obtaining insights into the successes and failures of these methods. To further explore and take advantage of the semantic correlation of these two tasks, we propose a novel joint human parsing and pose estimation network to explore efficient context modeling, which can simultaneously predict parsing and pose with extremely high quality. Furthermore, we simplify the network to solve human parsing by exploring a novel self-supervised structure-sensitive learning approach, which imposes human pose structures into the parsing results without resorting to extra supervision. The dataset, code and models are available at http://www.sysu-hcp.net/lip/.
Look into Person: Self-supervised Structure-sensitive Learning and A New Benchmark for Human Parsing
Jul 28, 2017
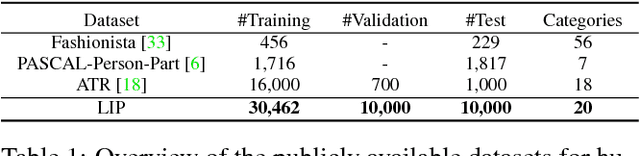
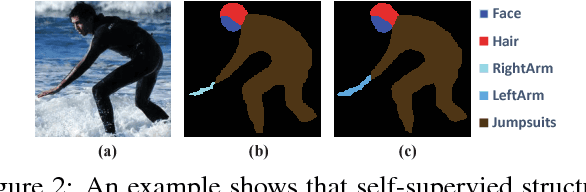
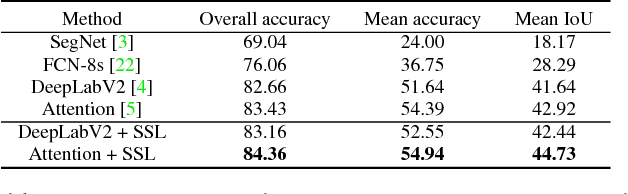
Human parsing has recently attracted a lot of research interests due to its huge application potentials. However existing datasets have limited number of images and annotations, and lack the variety of human appearances and the coverage of challenging cases in unconstrained environment. In this paper, we introduce a new benchmark "Look into Person (LIP)" that makes a significant advance in terms of scalability, diversity and difficulty, a contribution that we feel is crucial for future developments in human-centric analysis. This comprehensive dataset contains over 50,000 elaborately annotated images with 19 semantic part labels, which are captured from a wider range of viewpoints, occlusions and background complexity. Given these rich annotations we perform detailed analyses of the leading human parsing approaches, gaining insights into the success and failures of these methods. Furthermore, in contrast to the existing efforts on improving the feature discriminative capability, we solve human parsing by exploring a novel self-supervised structure-sensitive learning approach, which imposes human pose structures into parsing results without resorting to extra supervision (i.e., no need for specifically labeling human joints in model training). Our self-supervised learning framework can be injected into any advanced neural networks to help incorporate rich high-level knowledge regarding human joints from a global perspective and improve the parsing results. Extensive evaluations on our LIP and the public PASCAL-Person-Part dataset demonstrate the superiority of our method.