 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCT-CryptoNets: Scaling Private Inference in the Frequency Domain
Aug 27, 2024The convergence of fully homomorphic encryption (FHE) and machine learning offers unprecedented opportunities for private inference of sensitive data. FHE enables computation directly on encrypted data, safeguarding the entire machine learning pipeline, including data and model confidentiality. However, existing FHE-based implementations for deep neural networks face significant challenges in computational cost, latency, and scalability, limiting their practical deployment. This paper introduces DCT-CryptoNets, a novel approach that leverages frequency-domain learning to tackle these issues. Our method operates directly in the frequency domain, utilizing the discrete cosine transform (DCT) commonly employed in JPEG compression. This approach is inherently compatible with remote computing services, where images are usually transmitted and stored in compressed formats. DCT-CryptoNets reduces the computational burden of homomorphic operations by focusing on perceptually relevant low-frequency components. This is demonstrated by substantial latency reduction of up to 5.3$\times$ compared to prior work on image classification tasks, including a novel demonstration of ImageNet inference within 2.5 hours, down from 12.5 hours compared to prior work on equivalent compute resources. Moreover, DCT-CryptoNets improves the reliability of encrypted accuracy by reducing variability (e.g., from $\pm$2.5\% to $\pm$1.0\% on ImageNet). This study demonstrates a promising avenue for achieving efficient and practical privacy-preserving deep learning on high resolution images seen in real-world applications.
Approximate ADCs for In-Memory Computing
Aug 11, 2024
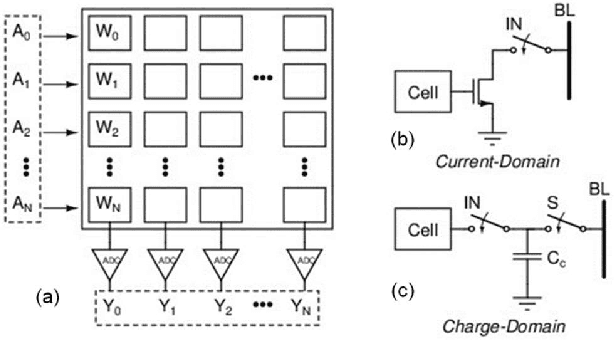


In memory computing (IMC) architectures for deep learning (DL) accelerators leverage energy-efficient and highly parallel matrix vector multiplication (MVM) operations, implemented directly in memory arrays. Such IMC designs have been explored based on CMOS as well as emerging non-volatile memory (NVM) technologies like RRAM. IMC architectures generally involve a large number of cores consisting of memory arrays, storing the trained weights of the DL model. Peripheral units like DACs and ADCs are also used for applying inputs and reading out the output values. Recently reported designs reveal that the ADCs required for reading out the MVM results, consume more than 85% of the total compute power and also dominate the area, thereby eschewing the benefits of the IMC scheme. Mitigation of imperfections in the ADCs, namely, non-linearity and variations, incur significant design overheads, due to dedicated calibration units. In this work we present peripheral aware design of IMC cores, to mitigate such overheads. It involves incorporating the non-idealities of ADCs in the training of the DL models, along with that of the memory units. The proposed approach applies equally well to both current mode as well as charge mode MVM operations demonstrated in recent years., and can significantly simplify the design of mixed-signal IMC units.
Eigen Attention: Attention in Low-Rank Space for KV Cache Compression
Aug 10, 2024



Large language models (LLMs) represent a groundbreaking advancement in the domain of natural language processing due to their impressive reasoning abilities. Recently, there has been considerable interest in increasing the context lengths for these models to enhance their applicability to complex tasks. However, at long context lengths and large batch sizes, the key-value (KV) cache, which stores the attention keys and values, emerges as the new bottleneck in memory usage during inference. To address this, we propose Eigen Attention, which performs the attention operation in a low-rank space, thereby reducing the KV cache memory overhead. Our proposed approach is orthogonal to existing KV cache compression techniques and can be used synergistically with them. Through extensive experiments over OPT, MPT, and Llama model families, we demonstrate that Eigen Attention results in up to 40% reduction in KV cache sizes and up to 60% reduction in attention operation latency with minimal drop in performance.
SHA-CNN: Scalable Hierarchical Aware Convolutional Neural Network for Edge AI
Jul 31, 2024This paper introduces a Scalable Hierarchical Aware Convolutional Neural Network (SHA-CNN) model architecture for Edge AI applications. The proposed hierarchical CNN model is meticulously crafted to strike a balance between computational efficiency and accuracy, addressing the challenges posed by resource-constrained edge devices. SHA-CNN demonstrates its efficacy by achieving accuracy comparable to state-of-the-art hierarchical models while outperforming baseline models in accuracy metrics. The key innovation lies in the model's hierarchical awareness, enabling it to discern and prioritize relevant features at multiple levels of abstraction. The proposed architecture classifies data in a hierarchical manner, facilitating a nuanced understanding of complex features within the datasets. Moreover, SHA-CNN exhibits a remarkable capacity for scalability, allowing for the seamless incorporation of new classes. This flexibility is particularly advantageous in dynamic environments where the model needs to adapt to evolving datasets and accommodate additional classes without the need for extensive retraining. Testing has been conducted on the PYNQ Z2 FPGA board to validate the proposed model. The results achieved an accuracy of 99.34%, 83.35%, and 63.66% for MNIST, CIFAR-10, and CIFAR-100 datasets, respectively. For CIFAR-100, our proposed architecture performs hierarchical classification with 10% reduced computation while compromising only 0.7% accuracy with the state-of-the-art. The adaptability of SHA-CNN to FPGA architecture underscores its potential for deployment in edge devices, where computational resources are limited. The SHA-CNN framework thus emerges as a promising advancement in the intersection of hierarchical CNNs, scalability, and FPGA-based Edge AI.
Neurosymbolic AI for Enhancing Instructability in Generative AI
Jul 26, 2024



Generative AI, especially via Large Language Models (LLMs), has transformed content creation across text, images, and music, showcasing capabilities in following instructions through prompting, largely facilitated by instruction tuning. Instruction tuning is a supervised fine-tuning method where LLMs are trained on datasets formatted with specific tasks and corresponding instructions. This method systematically enhances the model's ability to comprehend and execute the provided directives. Despite these advancements, LLMs still face challenges in consistently interpreting complex, multi-step instructions and generalizing them to novel tasks, which are essential for broader applicability in real-world scenarios. This article explores why neurosymbolic AI offers a better path to enhance the instructability of LLMs. We explore the use a symbolic task planner to decompose high-level instructions into structured tasks, a neural semantic parser to ground these tasks into executable actions, and a neuro-symbolic executor to implement these actions while dynamically maintaining an explicit representation of state. We also seek to show that neurosymbolic approach enhances the reliability and context-awareness of task execution, enabling LLMs to dynamically interpret and respond to a wider range of instructional contexts with greater precision and flexibility.
A Hybrid Spiking-Convolutional Neural Network Approach for Advancing Machine Learning Models
Jul 11, 2024In this article, we propose a novel standalone hybrid Spiking-Convolutional Neural Network (SC-NN) model and test on using image inpainting tasks. Our approach uses the unique capabilities of SNNs, such as event-based computation and temporal processing, along with the strong representation learning abilities of CNNs, to generate high-quality inpainted images. The model is trained on a custom dataset specifically designed for image inpainting, where missing regions are created using masks. The hybrid model consists of SNNConv2d layers and traditional CNN layers. The SNNConv2d layers implement the leaky integrate-and-fire (LIF) neuron model, capturing spiking behavior, while the CNN layers capture spatial features. In this study, a mean squared error (MSE) loss function demonstrates the training process, where a training loss value of 0.015, indicates accurate performance on the training set and the model achieved a validation loss value as low as 0.0017 on the testing set. Furthermore, extensive experimental results demonstrate state-of-the-art performance, showcasing the potential of integrating temporal dynamics and feature extraction in a single network for image inpainting.
* 7 Pages, 3 figures, and 2 tables
Curvature Clues: Decoding Deep Learning Privacy with Input Loss Curvature
Jul 03, 2024In this paper, we explore the properties of loss curvature with respect to input data in deep neural networks. Curvature of loss with respect to input (termed input loss curvature) is the trace of the Hessian of the loss with respect to the input. We investigate how input loss curvature varies between train and test sets, and its implications for train-test distinguishability. We develop a theoretical framework that derives an upper bound on the train-test distinguishability based on privacy and the size of the training set. This novel insight fuels the development of a new black box membership inference attack utilizing input loss curvature. We validate our theoretical findings through experiments in computer vision classification tasks, demonstrating that input loss curvature surpasses existing methods in membership inference effectiveness. Our analysis highlights how the performance of membership inference attack (MIA) methods varies with the size of the training set, showing that curvature-based MIA outperforms other methods on sufficiently large datasets. This condition is often met by real datasets, as demonstrated by our results on CIFAR10, CIFAR100, and ImageNet. These findings not only advance our understanding of deep neural network behavior but also improve the ability to test privacy-preserving techniques in machine learning.
Advancing Compressed Video Action Recognition through Progressive Knowledge Distillation
Jul 02, 2024Compressed video action recognition classifies video samples by leveraging the different modalities in compressed videos, namely motion vectors, residuals, and intra-frames. For this purpose, three neural networks are deployed, each dedicated to processing one modality. Our observations indicate that the network processing intra-frames tend to converge to a flatter minimum than the network processing residuals, which in turn converges to a flatter minimum than the motion vector network. This hierarchy in convergence motivates our strategy for knowledge transfer among modalities to achieve flatter minima, which are generally associated with better generalization. With this insight, we propose Progressive Knowledge Distillation (PKD), a technique that incrementally transfers knowledge across the modalities. This method involves attaching early exits (Internal Classifiers - ICs) to the three networks. PKD distills knowledge starting from the motion vector network, followed by the residual, and finally, the intra-frame network, sequentially improving IC accuracy. Further, we propose the Weighted Inference with Scaled Ensemble (WISE), which combines outputs from the ICs using learned weights, boosting accuracy during inference. Our experiments demonstrate the effectiveness of training the ICs with PKD compared to standard cross-entropy-based training, showing IC accuracy improvements of up to 5.87% and 11.42% on the UCF-101 and HMDB-51 datasets, respectively. Additionally, WISE improves accuracy by up to 4.28% and 9.30% on UCF-101 and HMDB-51, respectively.
Roadmap to Neuromorphic Computing with Emerging Technologies
Jul 02, 2024



The roadmap is organized into several thematic sections, outlining current computing challenges, discussing the neuromorphic computing approach, analyzing mature and currently utilized technologies, providing an overview of emerging technologies, addressing material challenges, exploring novel computing concepts, and finally examining the maturity level of emerging technologies while determining the next essential steps for their advancement.
Real-Time Neuromorphic Navigation: Integrating Event-Based Vision and Physics-Driven Planning on a Parrot Bebop2 Quadrotor
Jul 01, 2024

In autonomous aerial navigation, real-time and energy-efficient obstacle avoidance remains a significant challenge, especially in dynamic and complex indoor environments. This work presents a novel integration of neuromorphic event cameras with physics-driven planning algorithms implemented on a Parrot Bebop2 quadrotor. Neuromorphic event cameras, characterized by their high dynamic range and low latency, offer significant advantages over traditional frame-based systems, particularly in poor lighting conditions or during high-speed maneuvers. We use a DVS camera with a shallow Spiking Neural Network (SNN) for event-based object detection of a moving ring in real-time in an indoor lab. Further, we enhance drone control with physics-guided empirical knowledge inside a neural network training mechanism, to predict energy-efficient flight paths to fly through the moving ring. This integration results in a real-time, low-latency navigation system capable of dynamically responding to environmental changes while minimizing energy consumption. We detail our hardware setup, control loop, and modifications necessary for real-world applications, including the challenges of sensor integration without burdening the flight capabilities. Experimental results demonstrate the effectiveness of our approach in achieving robust, collision-free, and energy-efficient flight paths, showcasing the potential of neuromorphic vision and physics-driven planning in enhancing autonomous navigation systems.