 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Biasing of Language Models for Speech Recognition in Goal-Oriented Conversational Agents
Mar 19, 2021
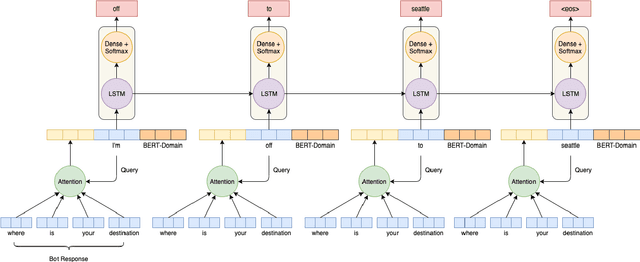
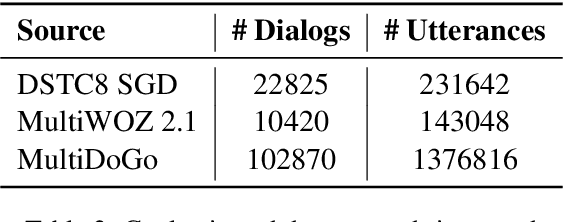
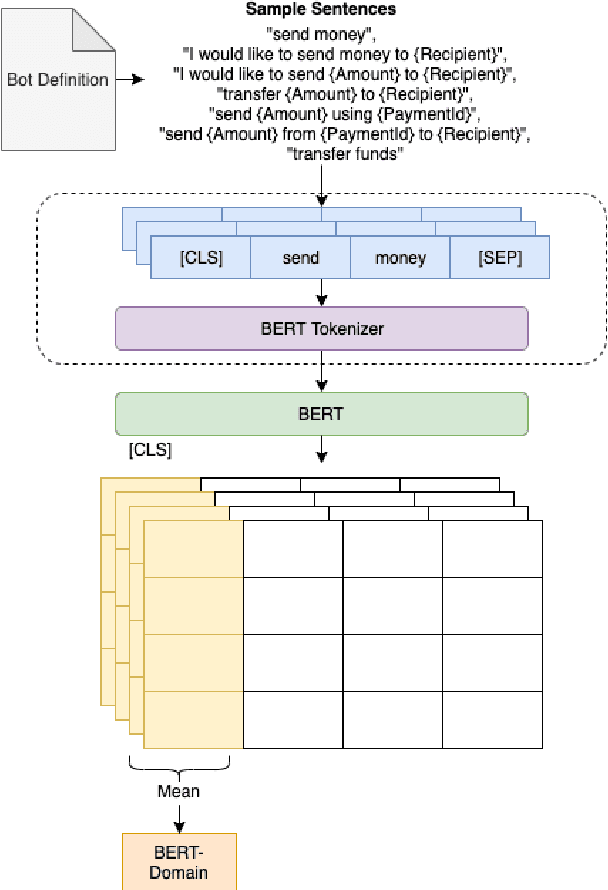
Goal-oriented conversational interfaces are designed to accomplish specific tasks and typically have interactions that tend to span multiple turns adhering to a pre-defined structure and a goal. However, conventional neural language models (NLM) in Automatic Speech Recognition (ASR) systems are mostly trained sentence-wise with limited context. In this paper, we explore different ways to incorporate context into a LSTM based NLM in order to model long range dependencies and improve speech recognition. Specifically, we use context carry over across multiple turns and use lexical contextual cues such as system dialog act from Natural Language Understanding (NLU) models and the user provided structure of the chatbot. We also propose a new architecture that utilizes context embeddings derived from BERT on sample utterances provided during inference time. Our experiments show a word error rate (WER) relative reduction of 7% over non-contextual utterance-level NLM rescorers on goal-oriented audio datasets.
Neural Inverse Text Normalization
Feb 12, 2021
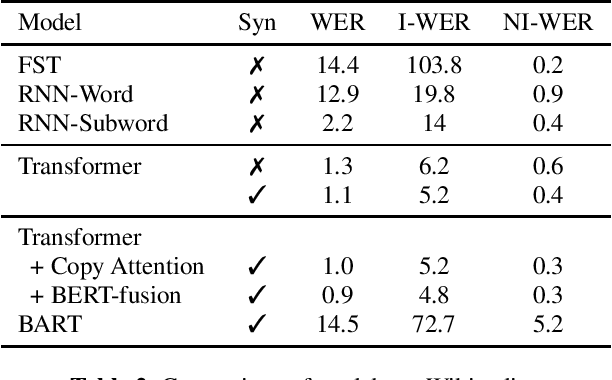
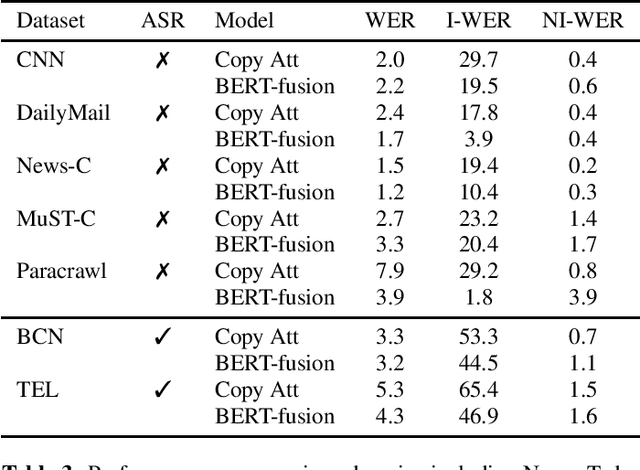
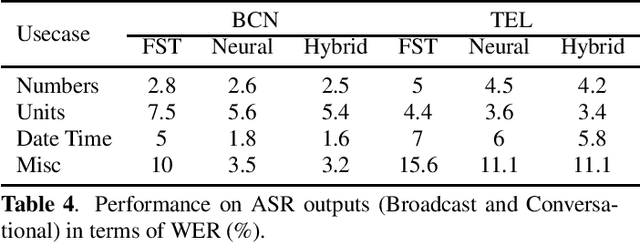
While there have been several contributions exploring state of the art techniques for text normalization, the problem of inverse text normalization (ITN) remains relatively unexplored. The best known approaches leverage finite state transducer (FST) based models which rely on manually curated rules and are hence not scalable. We propose an efficient and robust neural solution for ITN leveraging transformer based seq2seq models and FST-based text normalization techniques for data preparation. We show that this can be easily extended to other languages without the need for a linguistic expert to manually curate them. We then present a hybrid framework for integrating Neural ITN with an FST to overcome common recoverable errors in production environments. Our empirical evaluations show that the proposed solution minimizes incorrect perturbations (insertions, deletions and substitutions) to ASR output and maintains high quality even on out of domain data. A transformer based model infused with pretraining consistently achieves a lower WER across several datasets and is able to outperform baselines on English, Spanish, German and Italian datasets.
Transformer-Transducers for Code-Switched Speech Recognition
Nov 30, 2020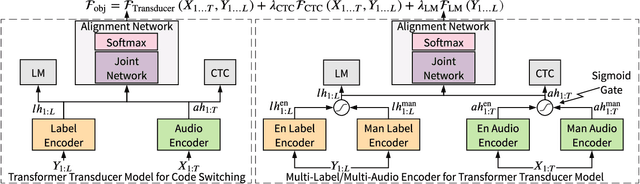
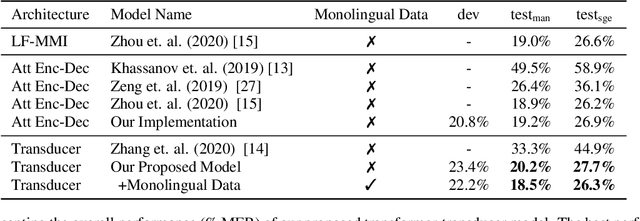


We live in a world where 60% of the population can speak two or more languages fluently. Members of these communities constantly switch between languages when having a conversation. As automatic speech recognition (ASR) systems are being deployed to the real-world, there is a need for practical systems that can handle multiple languages both within an utterance or across utterances. In this paper, we present an end-to-end ASR system using a transformer-transducer model architecture for code-switched speech recognition. We propose three modifications over the vanilla model in order to handle various aspects of code-switching. First, we introduce two auxiliary loss functions to handle the low-resource scenario of code-switching. Second, we propose a novel mask-based training strategy with language ID information to improve the label encoder training towards intra-sentential code-switching. Finally, we propose a multi-label/multi-audio encoder structure to leverage the vast monolingual speech corpora towards code-switching. We demonstrate the efficacy of our proposed approaches on the SEAME dataset, a public Mandarin-English code-switching corpus, achieving a mixed error rate of 18.5% and 26.3% on test_man and test_sge sets respectively.
Align-Refine: Non-Autoregressive Speech Recognition via Iterative Realignment
Oct 24, 2020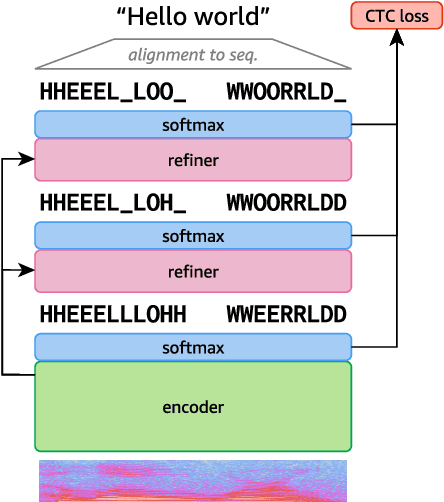
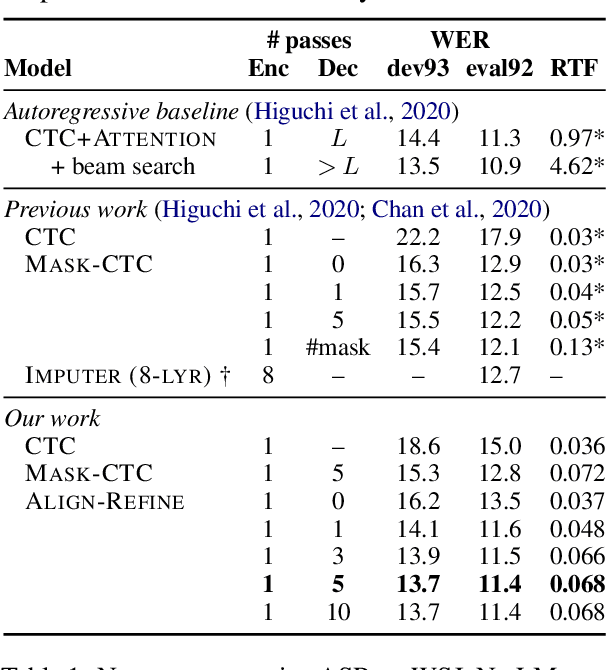
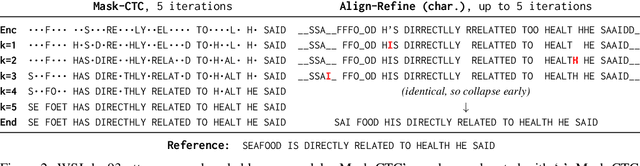
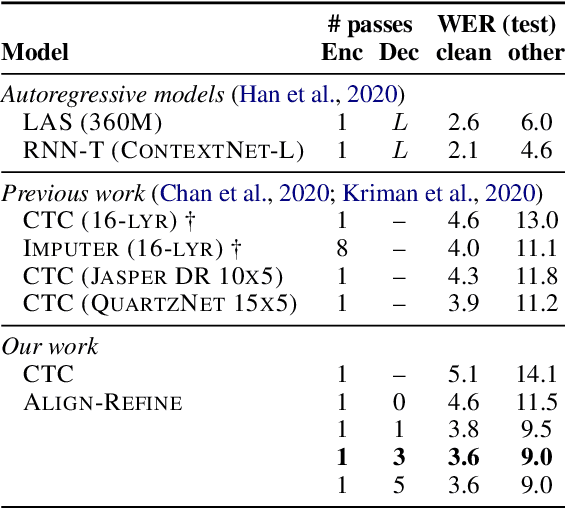
Non-autoregressive models greatly improve decoding speed over typical sequence-to-sequence models, but suffer from degraded performance. Infilling and iterative refinement models make up some of this gap by editing the outputs of a non-autoregressive model, but are constrained in the edits that they can make. We propose iterative realignment, where refinements occur over latent alignments rather than output sequence space. We demonstrate this in speech recognition with Align-Refine, an end-to-end Transformer-based model which refines connectionist temporal classification (CTC) alignments to allow length-changing insertions and deletions. Align-Refine outperforms Imputer and Mask-CTC, matching an autoregressive baseline on WSJ at 1/14th the real-time factor and attaining a LibriSpeech test-other WER of 9.0% without an LM. Our model is strong even in one iteration with a shallower decoder.
Multimodal Semi-supervised Learning Framework for Punctuation Prediction in Conversational Speech
Aug 03, 2020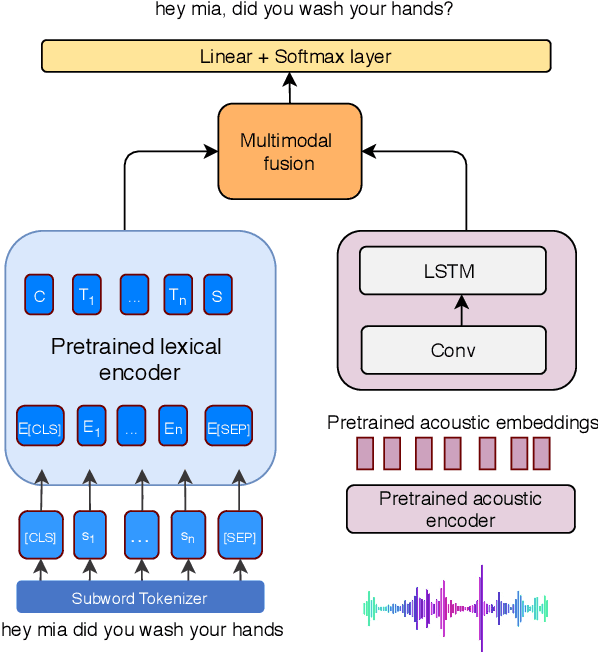
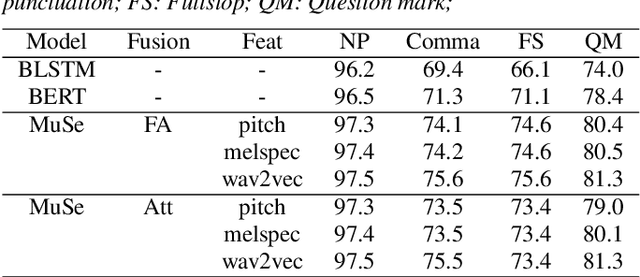
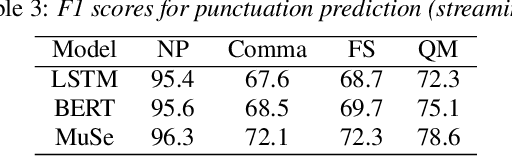
In this work, we explore a multimodal semi-supervised learning approach for punctuation prediction by learning representations from large amounts of unlabelled audio and text data. Conventional approaches in speech processing typically use forced alignment to encoder per frame acoustic features to word level features and perform multimodal fusion of the resulting acoustic and lexical representations. As an alternative, we explore attention based multimodal fusion and compare its performance with forced alignment based fusion. Experiments conducted on the Fisher corpus show that our proposed approach achieves ~6-9% and ~3-4% absolute improvement (F1 score) over the baseline BLSTM model on reference transcripts and ASR outputs respectively. We further improve the model robustness to ASR errors by performing data augmentation with N-best lists which achieves up to an additional ~2-6% improvement on ASR outputs. We also demonstrate the effectiveness of semi-supervised learning approach by performing ablation study on various sizes of the corpus. When trained on 1 hour of speech and text data, the proposed model achieved ~9-18% absolute improvement over baseline model.
Robust Prediction of Punctuation and Truecasing for Medical ASR
Jul 11, 2020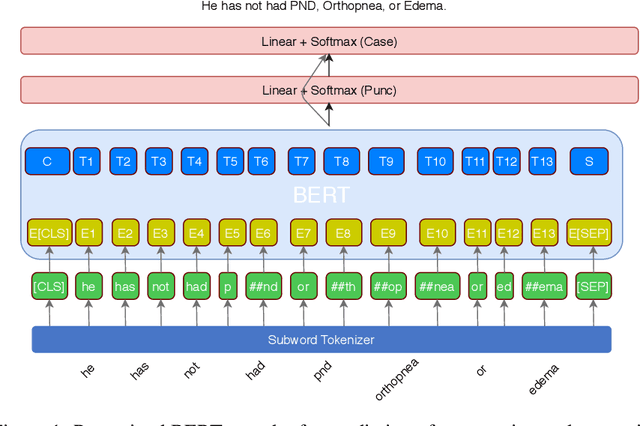
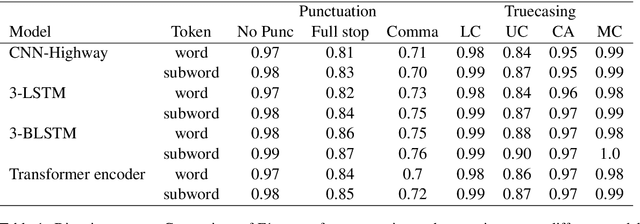
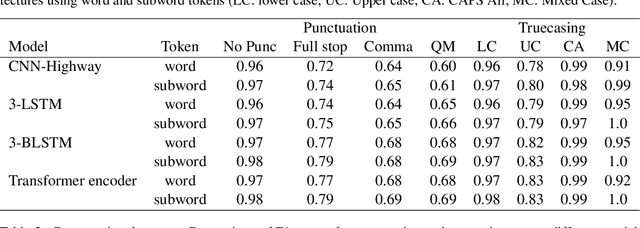
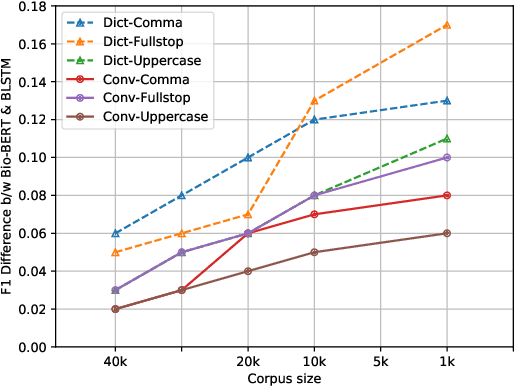
Automatic speech recognition (ASR) systems in the medical domain that focus on transcribing clinical dictations and doctor-patient conversations often pose many challenges due to the complexity of the domain. ASR output typically undergoes automatic punctuation to enable users to speak naturally, without having to vocalise awkward and explicit punctuation commands, such as "period", "add comma" or "exclamation point", while truecasing enhances user readability and improves the performance of downstream NLP tasks. This paper proposes a conditional joint modeling framework for prediction of punctuation and truecasing using pretrained masked language models such as BERT, BioBERT and RoBERTa. We also present techniques for domain and task specific adaptation by fine-tuning masked language models with medical domain data. Finally, we improve the robustness of the model against common errors made in ASR by performing data augmentation. Experiments performed on dictation and conversational style corpora show that our proposed model achieves ~5% absolute improvement on ground truth text and ~10% improvement on ASR outputs over baseline models under F1 metric.
Deep Contextualized Acoustic Representations For Semi-Supervised Speech Recognition
Dec 03, 2019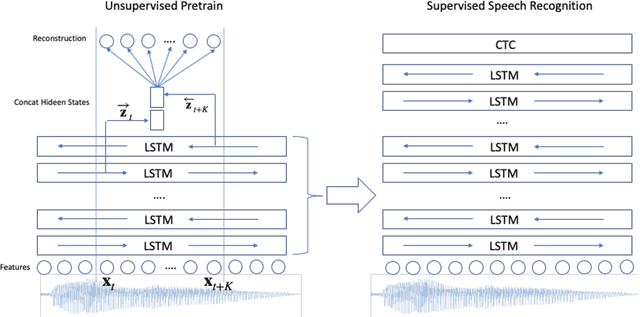

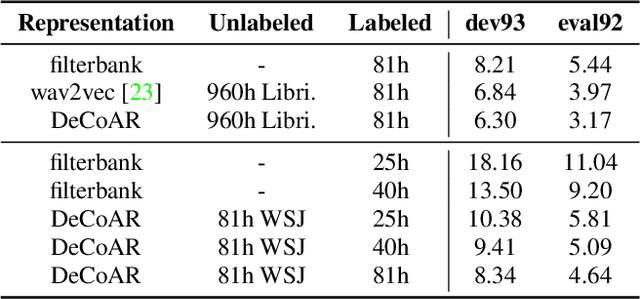

We propose a novel approach to semi-supervised automatic speech recognition (ASR). We first exploit a large amount of unlabeled audio data via representation learning, where we reconstruct a temporal slice of filterbank features from past and future context frames. The resulting deep contextualized acoustic representations (DeCoAR) are then used to train a CTC-based end-to-end ASR system using a smaller amount of labeled audio data. In our experiments, we show that systems trained on DeCoAR consistently outperform ones trained on conventional filterbank features, giving 42% and 19% relative improvement over the baseline on WSJ eval92 and LibriSpeech test-clean, respectively. Our approach can drastically reduce the amount of labeled data required; unsupervised training on LibriSpeech then supervision with 100 hours of labeled data achieves performance on par with training on all 960 hours directly.
Pseudolikelihood Reranking with Masked Language Models
Oct 31, 2019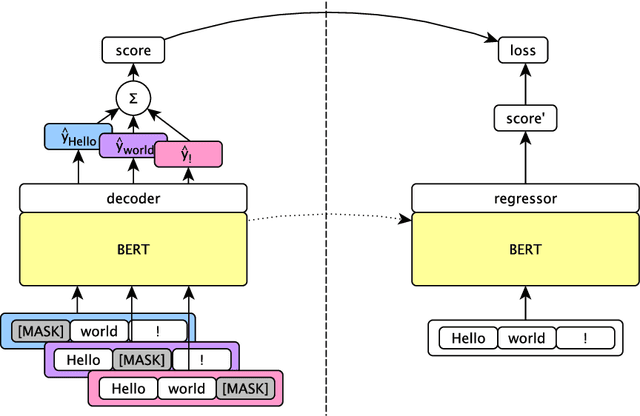
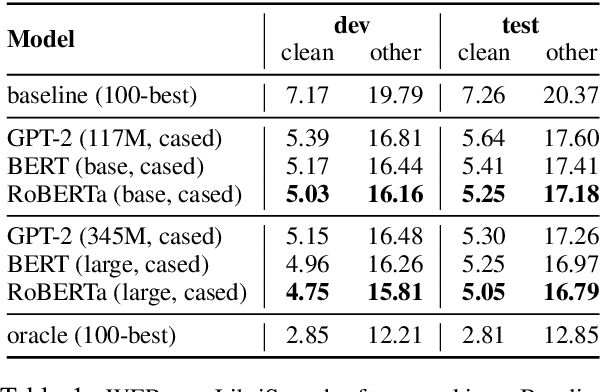
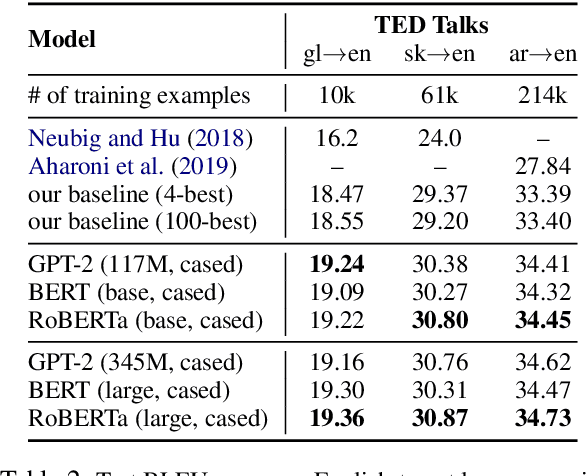
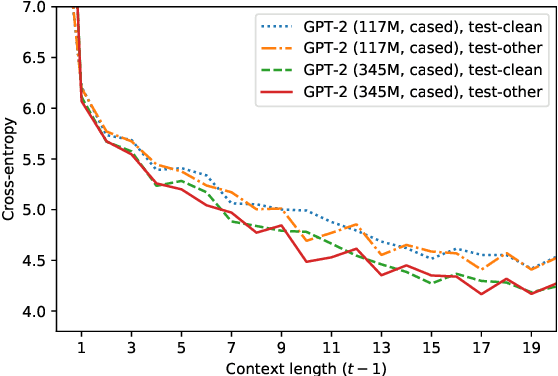
We rerank with scores from pretrained masked language models like BERT to improve ASR and NMT performance. These log-pseudolikelihood scores (LPLs) can outperform large, autoregressive language models (GPT-2) in out-of-the-box scoring. RoBERTa reduces WER by up to 30% relative on an end-to-end LibriSpeech system and adds up to +1.7 BLEU on state-of-the-art baselines for TED Talks low-resource pairs, with further gains from domain adaptation. In the multilingual setting, a single XLM can be used to rerank translation outputs in multiple languages. The numerical and qualitative properties of LPL scores suggest that LPLs capture sentence fluency better than autoregressive scores. Finally, we finetune BERT to estimate sentence LPLs without masking, enabling scoring in a single, non-recurrent inference pass.
Contextual Phonetic Pretraining for End-to-end Utterance-level Language and Speaker Recognition
Jun 30, 2019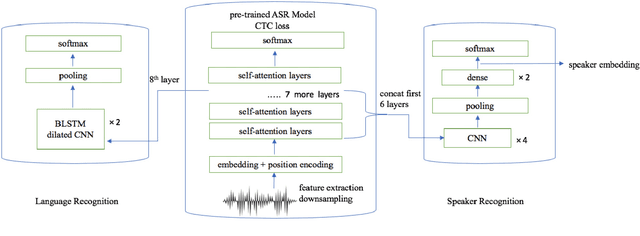
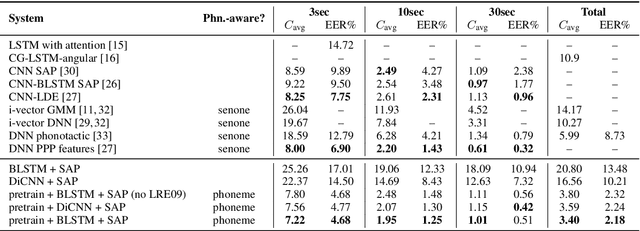
Pretrained contextual word representations in NLP have greatly improved performance on various downstream tasks. For speech, we propose contextual frame representations that capture phonetic information at the acoustic frame level and can be used for utterance-level language, speaker, and speech recognition. These representations come from the frame-wise intermediate representations of an end-to-end, self-attentive ASR model (SAN-CTC) on spoken utterances. We first train the model on the Fisher English corpus with context-independent phoneme labels, then use its representations at inference time as features for task-specific models on the NIST LRE07 closed-set language recognition task and a Fisher speaker recognition task, giving significant improvements over the state-of-the-art on both (e.g., language EER of 4.68% on 3sec utterances, 23% relative reduction in speaker EER). Results remain competitive when using a novel dilated convolutional model for language recognition, or when ASR pretraining is done with character labels only.
Simple, Fast, Accurate Intent Classification and Slot Labeling
Mar 19, 2019
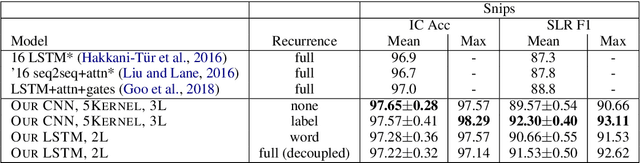

In real-time dialogue systems running at scale, there is a tradeoff between system performance, time taken for training to converge, and time taken to perform inference. In this work, we study modeling tradeoffs intent classification (IC) and slot labeling (SL), focusing on non-recurrent models. We propose a simple, modular family of neural architectures for joint IC+SL. Using this framework, we explore a number of self-attention, convolutional, and recurrent models, contributing a large-scale analysis of modeling paradigms for IC+SL across two datasets. At the same time, we discuss a class of 'label-recurrent' models, proposing that otherwise non-recurrent models with a 10-dimensional representation of the label history provide multi-point SL improvements. As a result of our analysis, we propose a class of label-recurrent, dilated, convolutional IC+SL systems that are accurate, achieving a 30% error reduction in SL over the state-of-the-art performance on the Snips dataset, as well as fast, at 2x the inference and 2/3 to 1/2 the training time of comparable recurrent models.