 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Weakly Supervised Classifier and Dataset of White Supremacist Language
Jun 27, 2023



We present a dataset and classifier for detecting the language of white supremacist extremism, a growing issue in online hate speech. Our weakly supervised classifier is trained on large datasets of text from explicitly white supremacist domains paired with neutral and anti-racist data from similar domains. We demonstrate that this approach improves generalization performance to new domains. Incorporating anti-racist texts as counterexamples to white supremacist language mitigates bias.
How Hate Speech Varies by Target Identity: A Computational Analysis
Oct 19, 2022
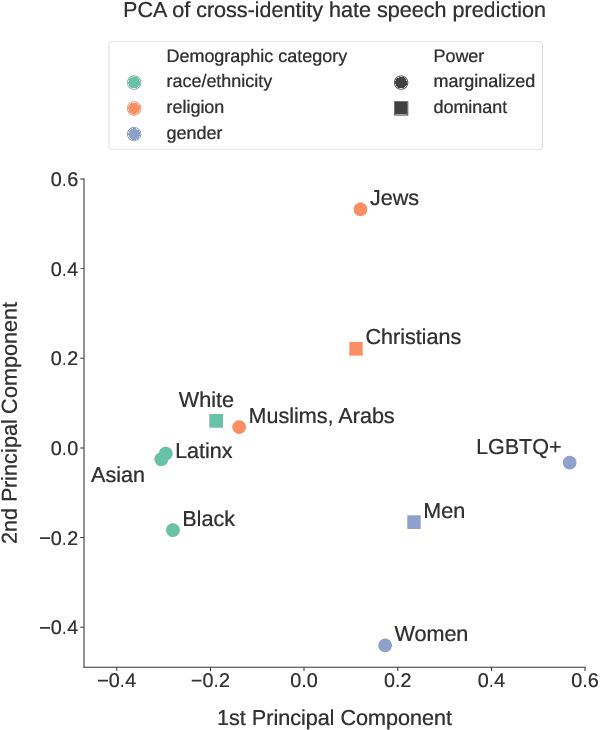
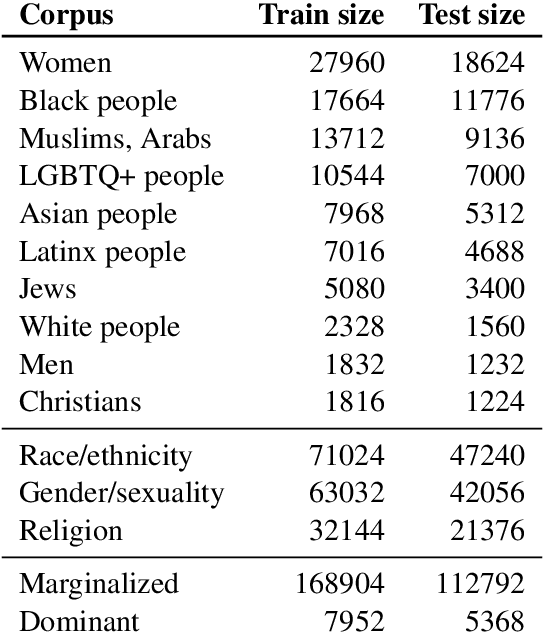
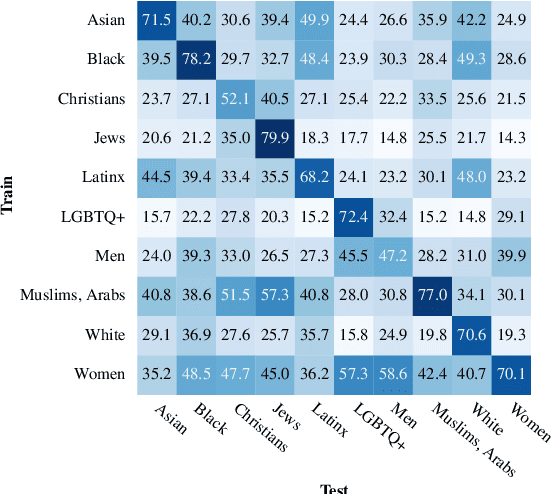
This paper investigates how hate speech varies in systematic ways according to the identities it targets. Across multiple hate speech datasets annotated for targeted identities, we find that classifiers trained on hate speech targeting specific identity groups struggle to generalize to other targeted identities. This provides empirical evidence for differences in hate speech by target identity; we then investigate which patterns structure this variation. We find that the targeted demographic category (e.g. gender/sexuality or race/ethnicity) appears to have a greater effect on the language of hate speech than does the relative social power of the targeted identity group. We also find that words associated with hate speech targeting specific identities often relate to stereotypes, histories of oppression, current social movements, and other social contexts specific to identities. These experiments suggest the importance of considering targeted identity, as well as the social contexts associated with these identities, in automated hate speech classification.
Multi-modal Networks Reveal Patterns of Operational Similarity of Terrorist Organizations
Dec 15, 2021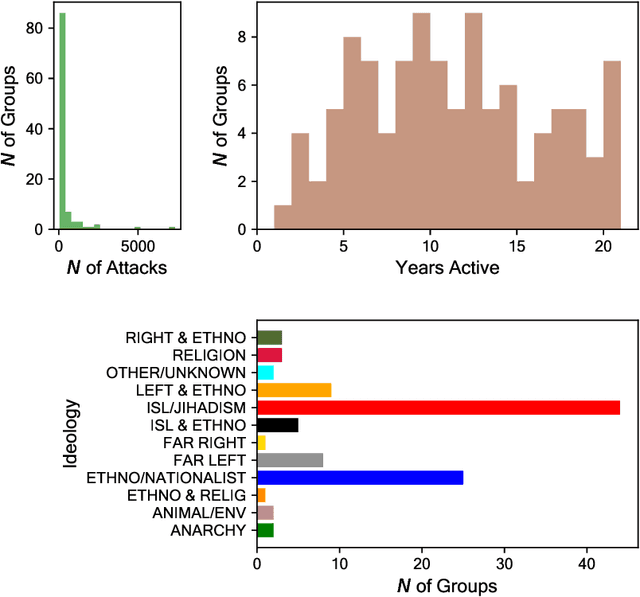
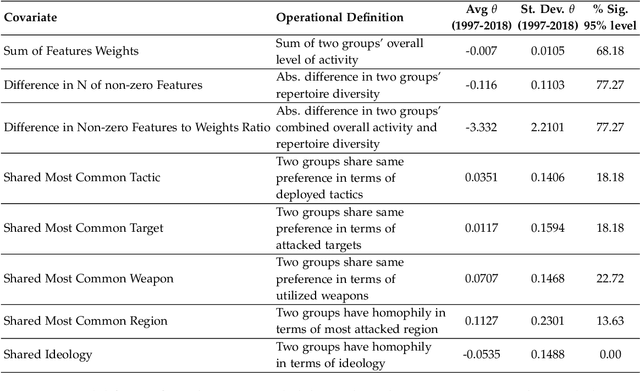
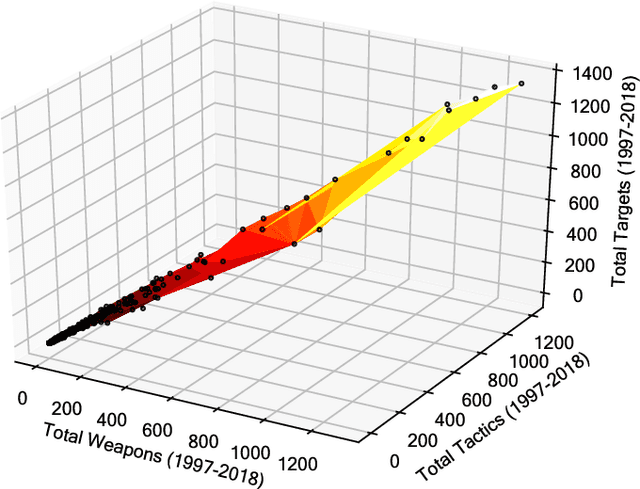
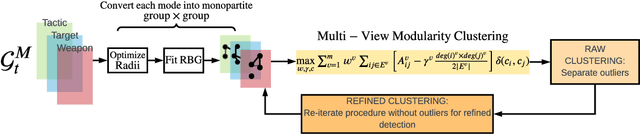
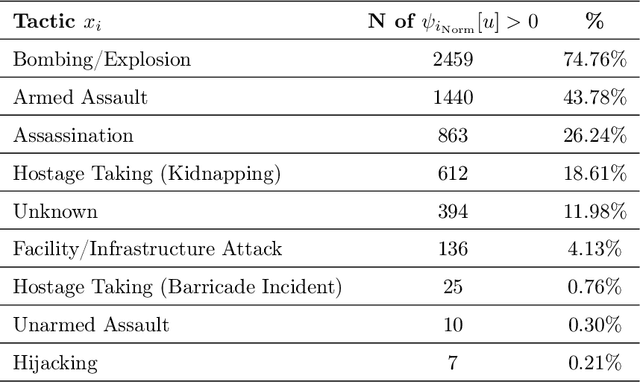
Capturing dynamics of operational similarity among terrorist groups is critical to provide actionable insights for counter-terrorism and intelligence monitoring. Yet, in spite of its theoretical and practical relevance, research addressing this problem is currently lacking. We tackle this problem proposing a novel computational framework for detecting clusters of terrorist groups sharing similar behaviors, focusing on groups' yearly repertoire of deployed tactics, attacked targets, and utilized weapons. Specifically considering those organizations that have plotted at least 50 attacks from 1997 to 2018, accounting for a total of 105 groups responsible for more than 42,000 events worldwide, we offer three sets of results. First, we show that over the years global terrorism has been characterized by increasing operational cohesiveness. Second, we highlight that year-to-year stability in co-clustering among groups has been particularly high from 2009 to 2018, indicating temporal consistency of similarity patterns in the last decade. Third, we demonstrate that operational similarity between two organizations is driven by three factors: (a) their overall activity; (b) the difference in the diversity of their operational repertoires; (c) the difference in a combined measure of diversity and activity. Groups' operational preferences, geographical homophily and ideological affinity have no consistent role in determining operational similarity.
* 42 pages, 19 figures
RATE: Overcoming Noise and Sparsity of Textual Features in Real-Time Location Estimation
Nov 12, 2021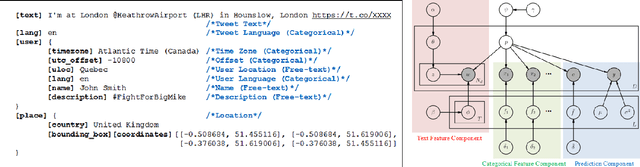
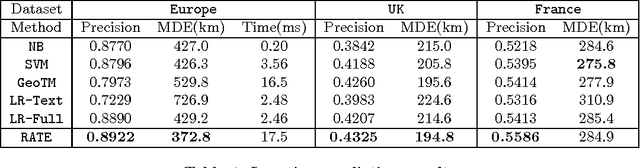
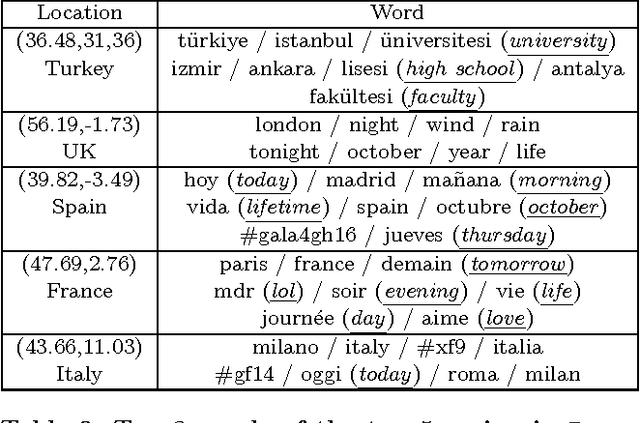
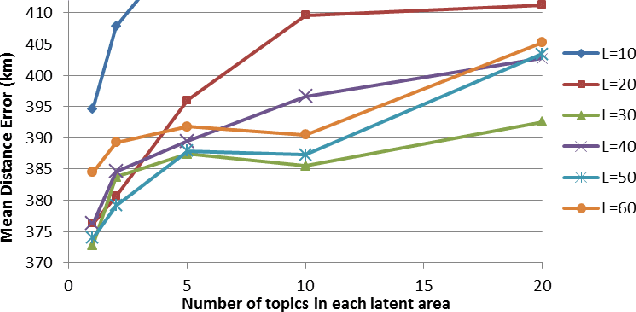
Real-time location inference of social media users is the fundamental of some spatial applications such as localized search and event detection. While tweet text is the most commonly used feature in location estimation, most of the prior works suffer from either the noise or the sparsity of textual features. In this paper, we aim to tackle these two problems. We use topic modeling as a building block to characterize the geographic topic variation and lexical variation so that "one-hot" encoding vectors will no longer be directly used. We also incorporate other features which can be extracted through the Twitter streaming API to overcome the noise problem. Experimental results show that our RATE algorithm outperforms several benchmark methods, both in the precision of region classification and the mean distance error of latitude and longitude regression.
Coordinating Narratives and the Capitol Riots on Parler
Sep 02, 2021
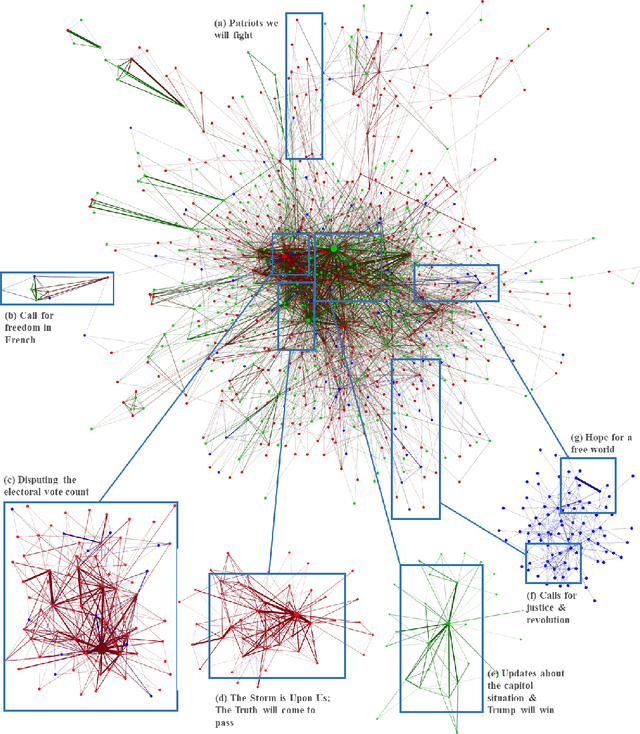

Coordinated disinformation campaigns are used to influence social media users, potentially leading to offline violence. In this study, we introduce a general methodology to uncover coordinated messaging through analysis of user parleys on Parler. The proposed method constructs a user-to-user coordination network graph induced by a user-to-text graph and a text-to-text similarity graph. The text-to-text graph is constructed based on the textual similarity of Parler posts. We study three influential groups of users in the 6 January 2020 Capitol riots and detect networks of coordinated user clusters that are all posting similar textual content in support of different disinformation narratives related to the U.S. 2020 elections.
Learning future terrorist targets through temporal meta-graphs
Apr 21, 2021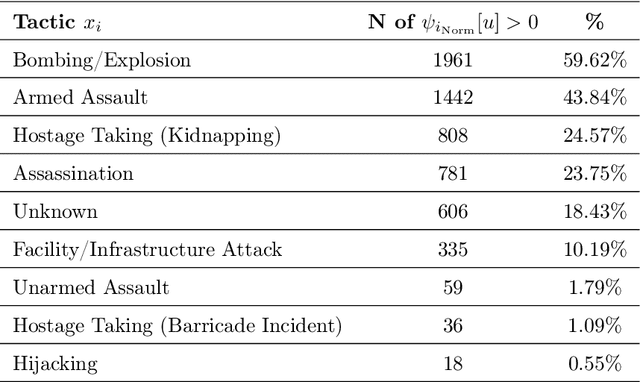
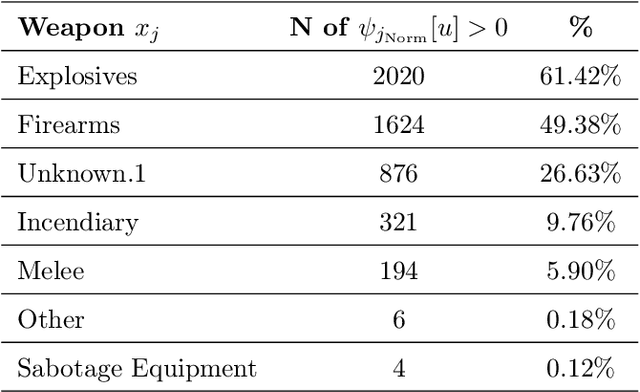
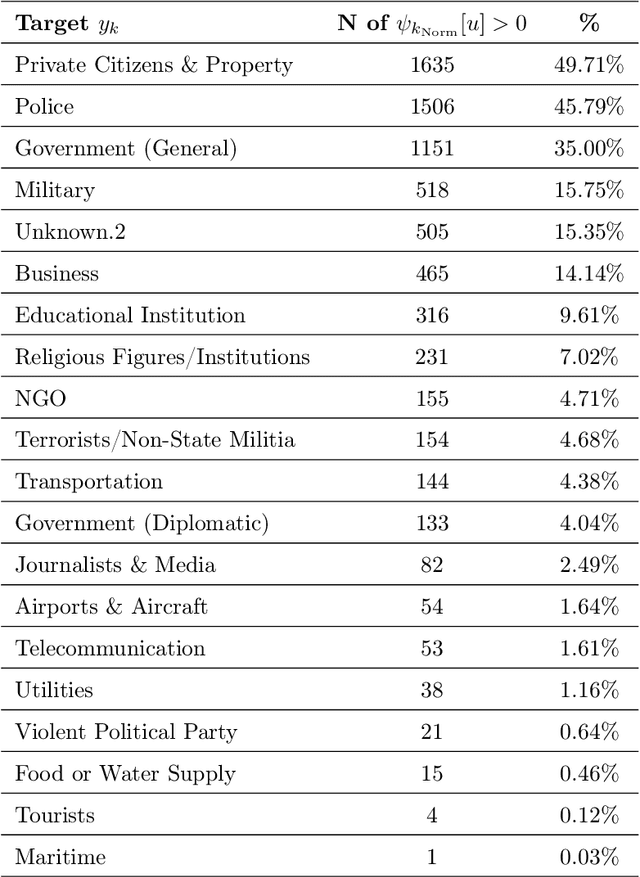
In the last 20 years, terrorism has led to hundreds of thousands of deaths and massive economic, political, and humanitarian crises in several regions of the world. Using real-world data on attacks occurred in Afghanistan and Iraq from 2001 to 2018, we propose the use of temporal meta-graphs and deep learning to forecast future terrorist targets. Focusing on three event dimensions, i.e., employed weapons, deployed tactics and chosen targets, meta-graphs map the connections among temporally close attacks, capturing their operational similarities and dependencies. From these temporal meta-graphs, we derive 2-day-based time series that measure the centrality of each feature within each dimension over time. Formulating the problem in the context of the strategic behavior of terrorist actors, these multivariate temporal sequences are then utilized to learn what target types are at the highest risk of being chosen. The paper makes two contributions. First, it demonstrates that engineering the feature space via temporal meta-graphs produces richer knowledge than shallow time-series that only rely on frequency of feature occurrences. Second, the performed experiments reveal that bi-directional LSTM networks achieve superior forecasting performance compared to other algorithms, calling for future research aiming at fully discovering the potential of artificial intelligence to counter terrorist violence.
* 19 pages, 18 figures
The Coronavirus is a Bioweapon: Analysing Coronavirus Fact-Checked Stories
Apr 02, 2021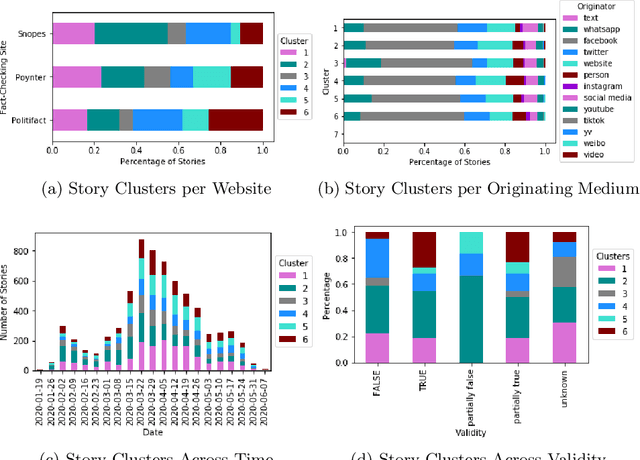
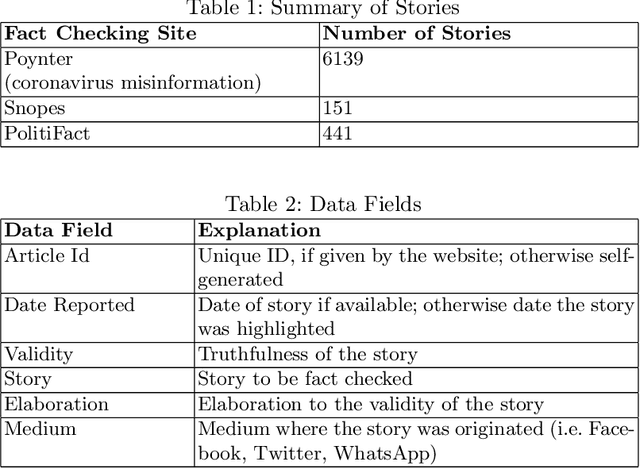
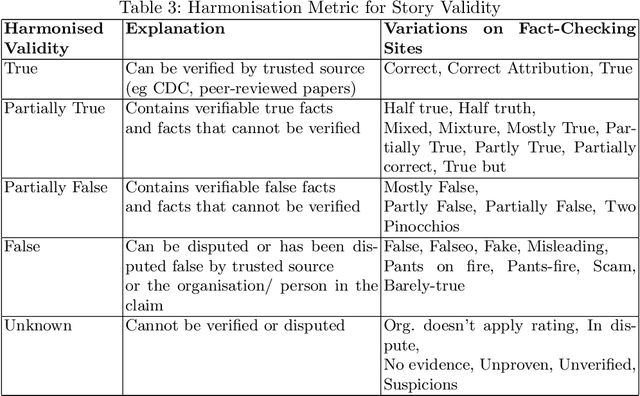
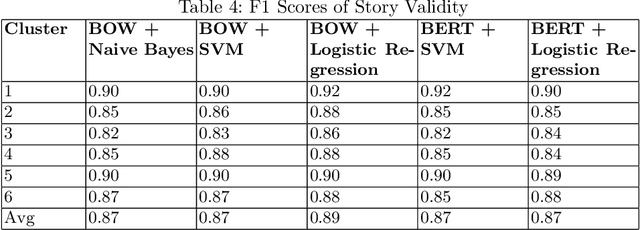
The 2020 coronavirus pandemic has heightened the need to flag coronavirus-related misinformation, and fact-checking groups have taken to verifying misinformation on the Internet. We explore stories reported by fact-checking groups PolitiFact, Poynter and Snopes from January to June 2020, characterising them into six story clusters before then analyse time-series and story validity trends and the level of agreement across sites. We further break down the story clusters into more granular story types by proposing a unique automated method with a BERT classifier, which can be used to classify diverse story sources, in both fact-checked stories and tweets.
A Weakly Supervised Approach for Classifying Stance in Twitter Replies
Mar 12, 2021
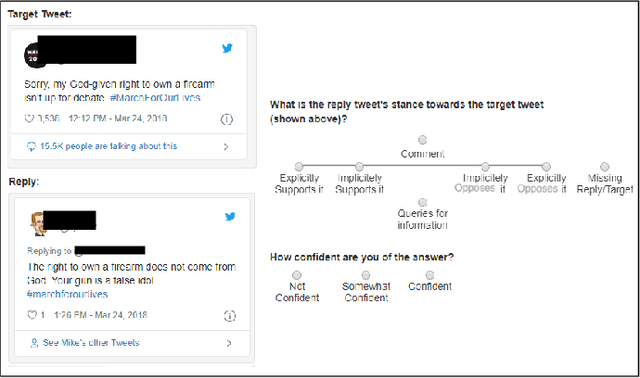
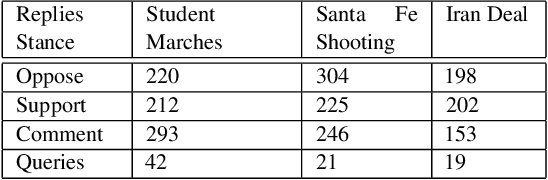
Conversations on social media (SM) are increasingly being used to investigate social issues on the web, such as online harassment and rumor spread. For such issues, a common thread of research uses adversarial reactions, e.g., replies pointing out factual inaccuracies in rumors. Though adversarial reactions are prevalent in online conversations, inferring those adverse views (or stance) from the text in replies is difficult and requires complex natural language processing (NLP) models. Moreover, conventional NLP models for stance mining need labeled data for supervised learning. Getting labeled conversations can itself be challenging as conversations can be on any topic, and topics change over time. These challenges make learning the stance a difficult NLP problem. In this research, we first create a new stance dataset comprised of three different topics by labeling both users' opinions on the topics (as in pro/con) and users' stance while replying to others' posts (as in favor/oppose). As we find limitations with supervised approaches, we propose a weakly-supervised approach to predict the stance in Twitter replies. Our novel method allows using a smaller number of hashtags to generate weak labels for Twitter replies. Compared to supervised learning, our method improves the mean F1-macro by 8\% on the hand-labeled dataset without using any hand-labeled examples in the training set. We further show the applicability of our proposed method on COVID 19 related conversations on Twitter.
Characterizing COVID-19 Misinformation Communities Using a Novel Twitter Dataset
Aug 31, 2020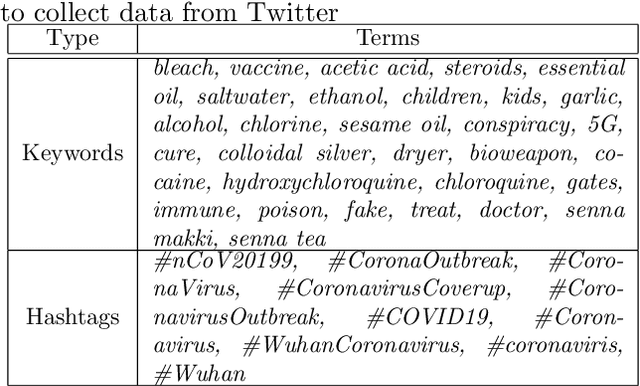
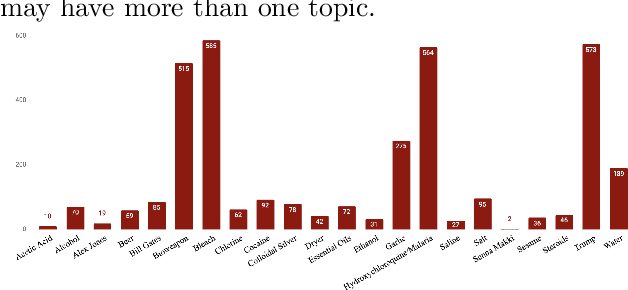
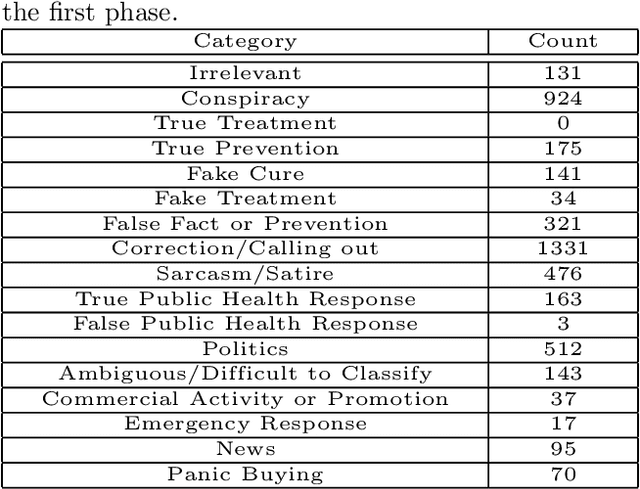
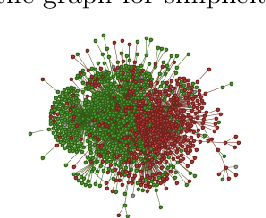
From conspiracy theories to fake cures and fake treatments, COVID-19 has become a hot-bed for the spread of misinformation online. It is more important than ever to identify methods to debunk and correct false information online. In this paper, we present a methodology and analyses to characterize the two competing COVID-19 misinformation communities online: (i) misinformed users or users who are actively posting misinformation, and (ii) informed users or users who are actively spreading true information, or calling out misinformation. The goals of this study are two-fold: (i) collecting a diverse set of annotated COVID-19 Twitter dataset that can be used by the research community to conduct meaningful analysis; and (ii) characterizing the two target communities in terms of their network structure, linguistic patterns, and their membership in other communities. Our analyses show that COVID-19 misinformed communities are denser, and more organized than informed communities, with a possibility of a high volume of the misinformation being part of disinformation campaigns. Our analyses also suggest that a large majority of misinformed users may be anti-vaxxers. Finally, our sociolinguistic analyses suggest that COVID-19 informed users tend to use more narratives than misinformed users.
Bot-Match: Social Bot Detection with Recursive Nearest Neighbors Search
Jul 15, 2020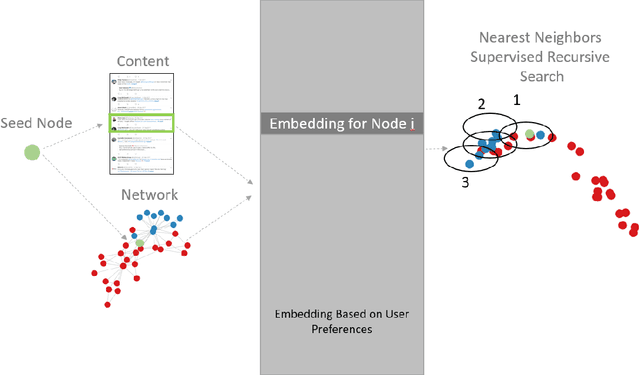
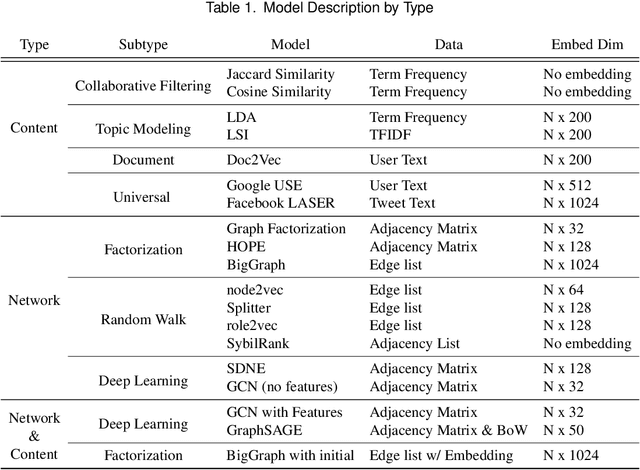
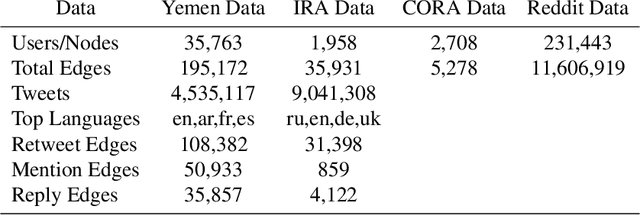
Social bots have emerged over the last decade, initially creating a nuisance while more recently used to intimidate journalists, sway electoral events, and aggravate existing social fissures. This social threat has spawned a bot detection algorithms race in which detection algorithms evolve in an attempt to keep up with increasingly sophisticated bot accounts. This cat and mouse cycle has illuminated the limitations of supervised machine learning algorithms, where researchers attempt to use yesterday's data to predict tomorrow's bots. This gap means that researchers, journalists, and analysts daily identify malicious bot accounts that are undetected by state of the art supervised bot detection algorithms. These analysts often desire to find similar bot accounts without labeling/training a new model, where similarity can be defined by content, network position, or both. A similarity based algorithm could complement existing supervised and unsupervised methods and fill this gap. To this end, we present the Bot-Match methodology in which we evaluate social media embeddings that enable a semi-supervised recursive nearest neighbors search to map an emerging social cybersecurity threat given one or more seed accounts.