 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuratorKIT : Data Curation and Synthetic Data Generation for LLM Post-Training
Jun 19, 2026Data curation is a critical part of post-training pipelines for large language models, yet existing tools often treat ingestion, deduplication, synthetic generation, and quality filtering as separate stages. This fragmentation makes it difficult to audit pipeline decisions or understand why individual samples are rejected. CuratorKIT is an open-source Python library that covers this full lifecycle in a single configurable pipeline. The framework is composed of six source format readers and automatic schema detection, a pre-generation data hygiene layer for credentials, PII, and toxic content, eight LLM-powered generation tasks, three complementary quality gates with provenance-exact hallucination verification, structured adaptive recovery, and five training-ready export formats compatible with TRL, Unsloth, and AlignTune. Every pipeline decision is recorded in an append-only per-sample provenance chain, and rejected samples carry structured failure reasons rather than being silently discarded. CuratorKIT supports 100+ LLM providers through LiteLLM, exposes both a Python API and a YAML-driven CLI, and is designed for practitioners who need reproducible, auditable data pipelines at scale .
Provenance-Grounded Gating and Adaptive Recovery in Synthetic Post-Training Data Curation
Jun 09, 2026Synthetic post-training pipelines commonly filter generated samples with reward models or holistic LLM judges, yet two practices remain rarely examined together: whether the filtering signal is grounded in the source evidence that induced each generation, and whether rejected samples can be systematically recovered rather than permanently discarded. We present a controlled study of both questions across gate configurations, recovery strategies, and generator scales, using adversarially injected corpora to provide ground-truth failure labels. We find that exact source provenance improves faithfulness gating for stronger judges, that hallucination and reward gates reject largely disjoint sample populations making both necessary, and that an adaptive recovery pipeline combining failure diagnosis with targeted regeneration achieves higher yield, recovery rate, and injection recall than naive resampling. Downstream fine-tuning quality is driven primarily by generator scale, with filtration and recovery conditions contributing meaningfully but secondarily.
PushupBench: Your VLM is not good at counting pushups
Apr 25, 2026Large vision-language models (VLMs) can recognize \textit{what} happens in video but fail to count \textit{how many} times. We introduce \textbf{PushupBench}, 446 long-form clips (avg. 36.7s) for evaluating repetition counting. The best frontier model achieves 42.1\% exact accuracy; open-source 4B models score $\sim$6\%, matching supervised baselines. We show that accuracy alone misleads -- weaker models exploit the modal count rather than reason temporally. Fine-tuning on counting with 1k samples transfers to general video understanding: MVBench (+2.15), PerceptionTest (+1.88), TVBench (+4.54), suggesting counting is a proxy for broader temporal reasoning.PushupBench incorporated in \texttt{lmms-eval} (https://github.com/EvolvingLMMs-Lab/lmms-eval/pull/1262) and hosted on (pushupbench.com/)
A Surgical Platform for Intracerebral Hemorrhage Robotic Evacuation (ASPIHRE): A Non-metallic MR-guided Concentric Tube Robot
Jun 20, 2022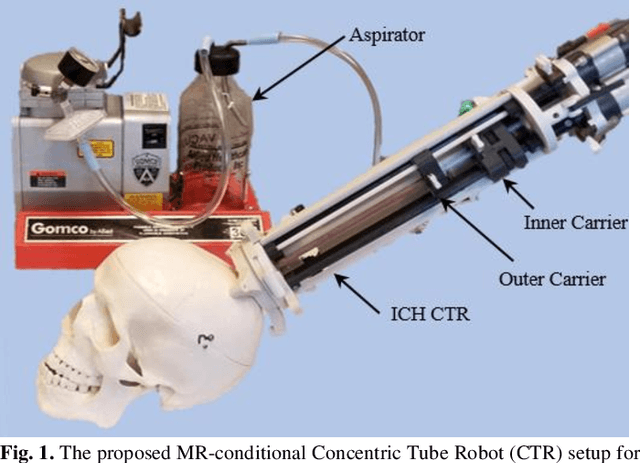

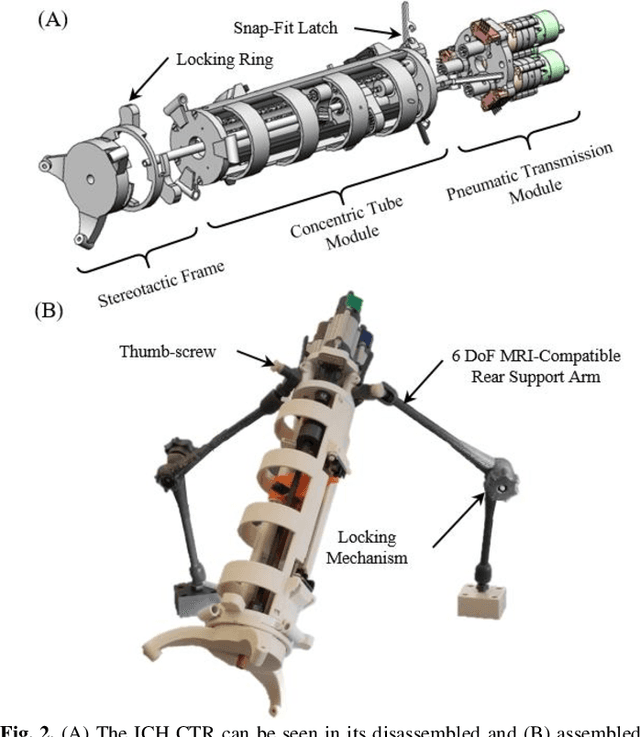
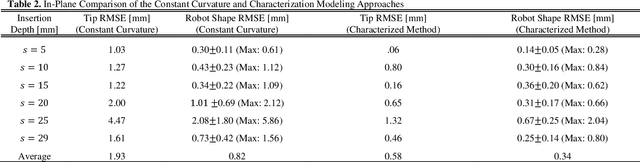
Intracerebral hemorrhage (ICH) is the deadliest stroke sub-type, with a one-month mortality rate as high as 52%. Due to the potential cortical disruption caused by craniotomy, conservative management (watchful waiting) has historically been a common method of treatment. Minimally invasive evacuation has recently become an accepted method of treatment for patients with deep-seated hematoma 30-50 mL in volume, but proper visualization and tool dexterity remain constrained in conventional endoscopic approaches, particularly with larger hematoma volumes (> 50 mL). In this article we describe the development of ASPIHRE (A Surgical Platform for Intracerebral Hemorrhage Robotic Evacuation), the first-ever concentric tube robot that uses off-the-shelf plastic tubes for MR-guided ICH evacuation, improving tool dexterity and procedural visualization. The robot kinematics model is developed based on a calibration-based method and tube mechanics modeling, allowing the models to consider both variable curvature and torsional deflection. The MR-safe pneumatic motors are controlled using a variable gain PID algorithm producing a rotational accuracy of 0.317 +/- 0.3 degrees. The hardware and theoretical models are validated in a series of systematic bench-top and MRI experiments resulting in positional accuracy of the tube tip of 1.39 +\- 0.54 mm. Following validation of targeting accuracy, the evacuation efficacy of the robot was tested in an MR-guided phantom clot evacuation experiment. The robot was able to evacuate an initially 38.36 mL clot in 5 minutes, leaving a residual hematoma of 8.14 mL, well below the 15 mL guideline suggesting good post-ICH evacuation clinical outcomes.