 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Task Completion: An Assessment Framework for Evaluating Agentic AI Systems
Dec 16, 2025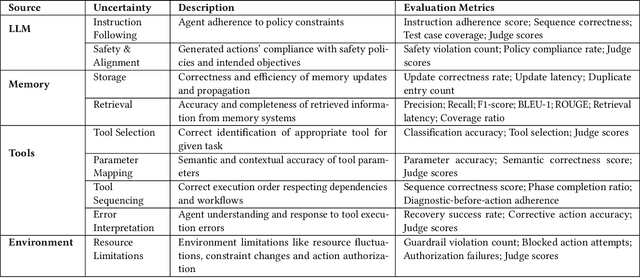
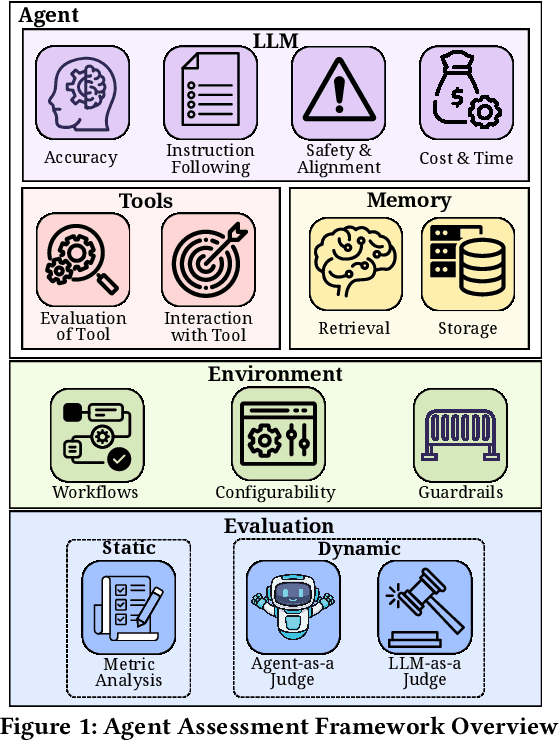
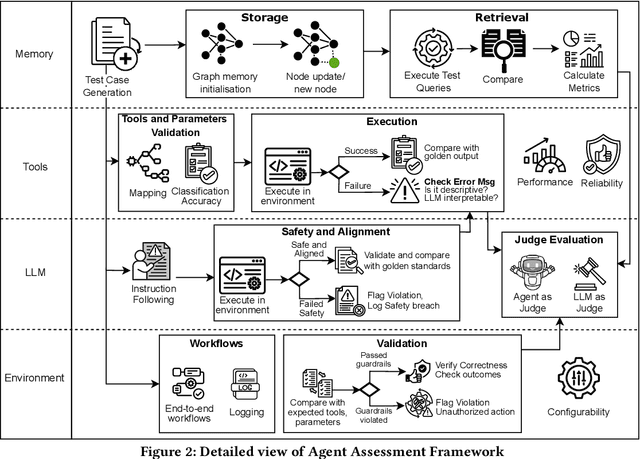
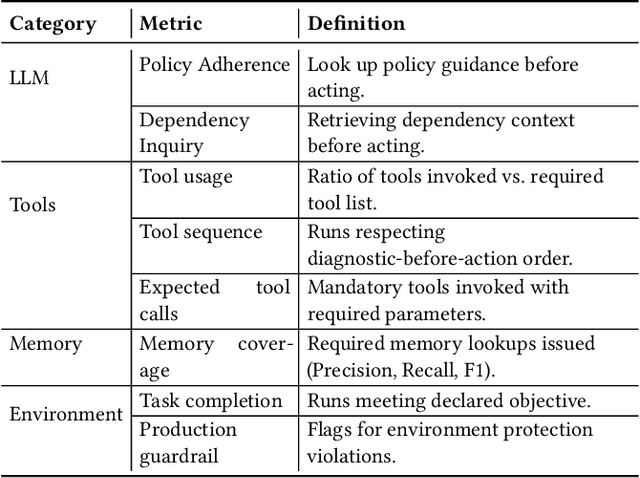
Recent advances in agentic AI have shifted the focus from standalone Large Language Models (LLMs) to integrated systems that combine LLMs with tools, memory, and other agents to perform complex tasks. These multi-agent architectures enable coordinated reasoning, planning, and execution across diverse domains, allowing agents to collaboratively automate complex workflows. Despite these advances, evaluation and assessment of LLM agents and the multi-agent systems they constitute remain a fundamental challenge. Although various approaches have been proposed in the software engineering literature for evaluating conventional software components, existing methods for AI-based systems often overlook the non-deterministic nature of models. This non-determinism introduces behavioral uncertainty during execution, yet existing evaluations rely on binary task completion metrics that fail to capture it. Evaluating agentic systems therefore requires examining additional dimensions, including the agent ability to invoke tools, ingest and retrieve memory, collaborate with other agents, and interact effectively with its environment. These challenges emerged during our ongoing industry collaboration with MontyCloud Inc., when we deployed an agentic system in production. These limitations surfaced during deployment, highlighting practical gaps in the current evaluation methods and the need for a systematic assessment of agent behavior beyond task outcomes. Informed by these observations and established definitions of agentic systems, we propose an end-to-end Agent Assessment Framework with four evaluation pillars encompassing LLMs, Memory, Tools, and Environment. We validate the framework on a representative Autonomous CloudOps use case, where experiments reveal behavioral deviations overlooked by conventional metrics, demonstrating its effectiveness in capturing runtime uncertainties.
Engineering LLM Powered Multi-agent Framework for Autonomous CloudOps
Jan 14, 2025



Cloud Operations (CloudOps) is a rapidly growing field focused on the automated management and optimization of cloud infrastructure which is essential for organizations navigating increasingly complex cloud environments. MontyCloud Inc. is one of the major companies in the CloudOps domain that leverages autonomous bots to manage cloud compliance, security, and continuous operations. To make the platform more accessible and effective to the customers, we leveraged the use of GenAI. Developing a GenAI-based solution for autonomous CloudOps for the existing MontyCloud system presented us with various challenges such as i) diverse data sources; ii) orchestration of multiple processes; and iii) handling complex workflows to automate routine tasks. To this end, we developed MOYA, a multi-agent framework that leverages GenAI and balances autonomy with the necessary human control. This framework integrates various internal and external systems and is optimized for factors like task orchestration, security, and error mitigation while producing accurate, reliable, and relevant insights by utilizing Retrieval Augmented Generation (RAG). Evaluations of our multi-agent system with the help of practitioners as well as using automated checks demonstrate enhanced accuracy, responsiveness, and effectiveness over non-agentic approaches across complex workflows.