 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikiUMLS: Aligning UMLS to Wikipedia via Cross-lingual Neural Ranking
May 08, 2020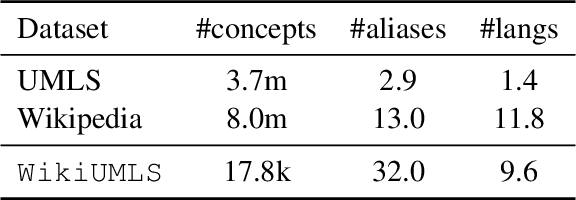
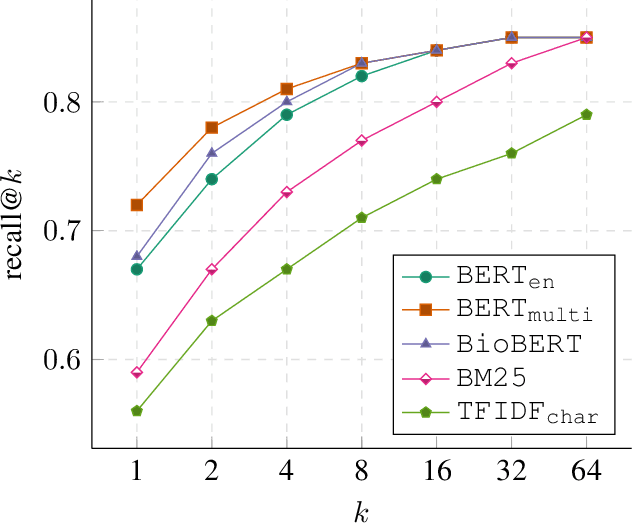
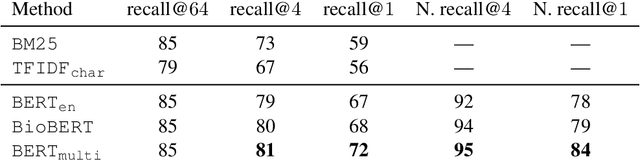
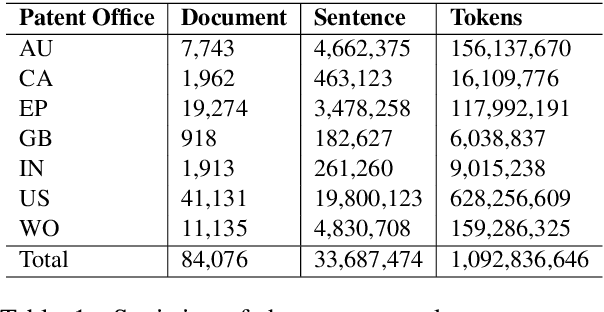
We present our work on aligning the Unified Medical Language System (UMLS) to Wikipedia, to facilitate manual alignment of the two resources. We propose a cross-lingual neural reranking model to match a UMLS concept with a Wikipedia page, which achieves a recall@1 of 71%, a substantial improvement of 20% over word- and char-level BM25, enabling manual alignment with minimal effort. We release our resources, including ranked Wikipedia pages for 700k UMLS concepts, and WikiUMLS, a dataset for training and evaluation of alignment models between UMLS and Wikipedia. This will provide easier access to Wikipedia for health professionals, patients, and NLP systems, including in multilingual settings.
SemEval-2017 Task 3: Community Question Answering
Dec 02, 2019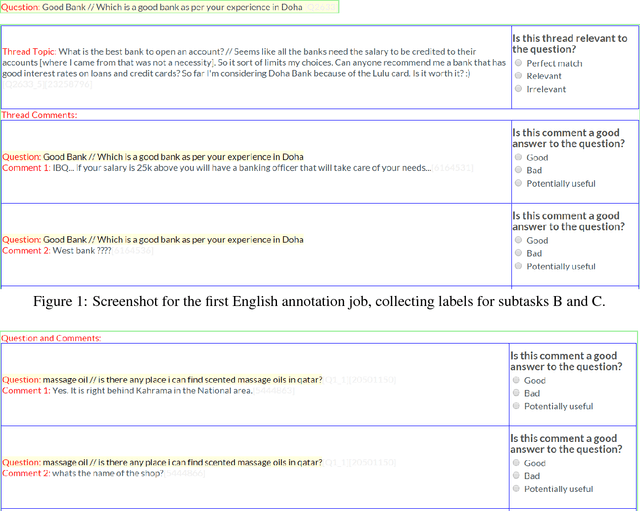
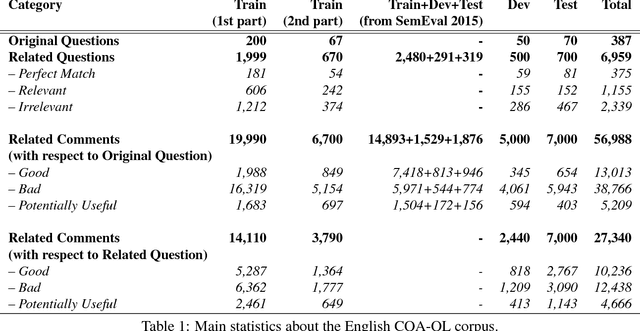
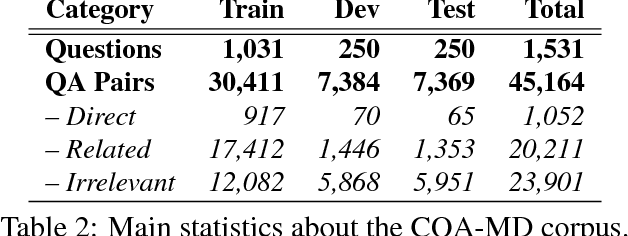
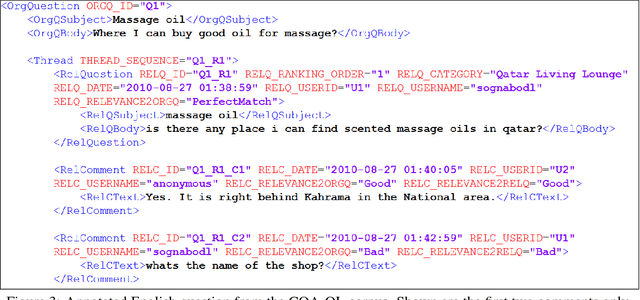
We describe SemEval-2017 Task 3 on Community Question Answering. This year, we reran the four subtasks from SemEval-2016:(A) Question-Comment Similarity,(B) Question-Question Similarity,(C) Question-External Comment Similarity, and (D) Rerank the correct answers for a new question in Arabic, providing all the data from 2015 and 2016 for training, and fresh data for testing. Additionally, we added a new subtask E in order to enable experimentation with Multi-domain Question Duplicate Detection in a larger-scale scenario, using StackExchange subforums. A total of 23 teams participated in the task, and submitted a total of 85 runs (36 primary and 49 contrastive) for subtasks A-D. Unfortunately, no teams participated in subtask E. A variety of approaches and features were used by the participating systems to address the different subtasks. The best systems achieved an official score (MAP) of 88.43, 47.22, 15.46, and 61.16 in subtasks A, B, C, and D, respectively. These scores are better than the baselines, especially for subtasks A-C.
* community question answering, question-question similarity, question-comment similarity, answer reranking, Multi-domain Question Duplicate Detection, StackExchange, English, Arabic
Improving Chemical Named Entity Recognition in Patents with Contextualized Word Embeddings
Jul 05, 2019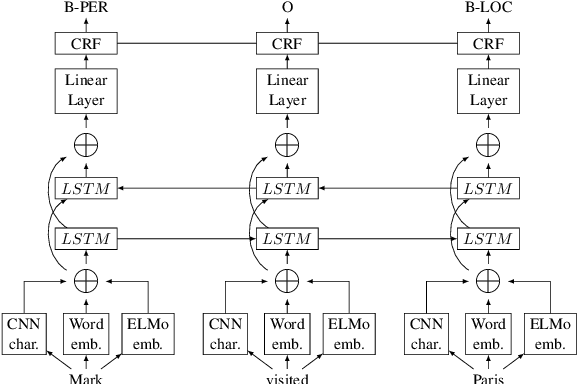

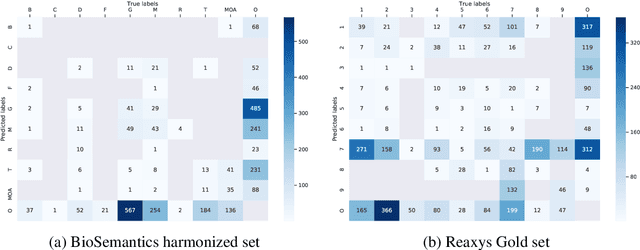
Chemical patents are an important resource for chemical information. However, few chemical Named Entity Recognition (NER) systems have been evaluated on patent documents, due in part to their structural and linguistic complexity. In this paper, we explore the NER performance of a BiLSTM-CRF model utilising pre-trained word embeddings, character-level word representations and contextualized ELMo word representations for chemical patents. We compare word embeddings pre-trained on biomedical and chemical patent corpora. The effect of tokenizers optimized for the chemical domain on NER performance in chemical patents is also explored. The results on two patent corpora show that contextualized word representations generated from ELMo substantially improve chemical NER performance w.r.t. the current state-of-the-art. We also show that domain-specific resources such as word embeddings trained on chemical patents and chemical-specific tokenizers have a positive impact on NER performance.
A bag-of-concepts model improves relation extraction in a narrow knowledge domain with limited data
Apr 24, 2019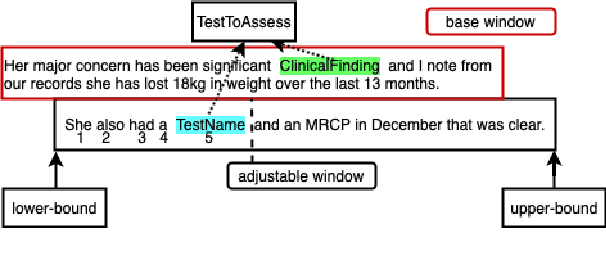
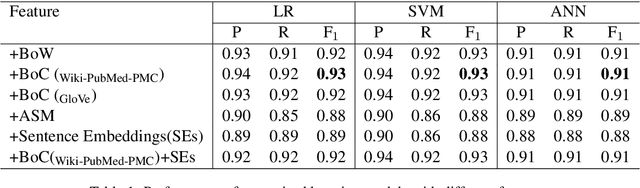
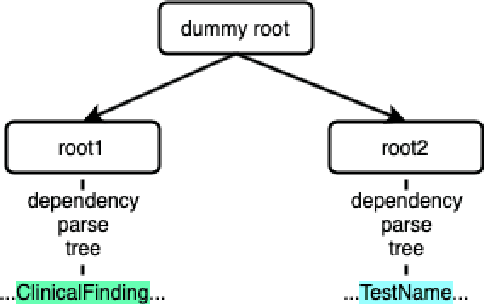
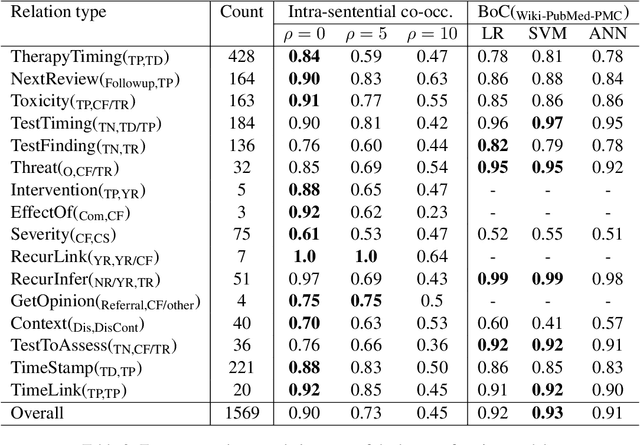
This paper focuses on a traditional relation extraction task in the context of limited annotated data and a narrow knowledge domain. We explore this task with a clinical corpus consisting of 200 breast cancer follow-up treatment letters in which 16 distinct types of relations are annotated. We experiment with an approach to extracting typed relations called window-bounded co-occurrence (WBC), which uses an adjustable context window around entity mentions of a relevant type, and compare its performance with a more typical intra-sentential co-occurrence baseline. We further introduce a new bag-of-concepts (BoC) approach to feature engineering based on the state-of-the-art word embeddings and word synonyms. We demonstrate the competitiveness of BoC by comparing with methods of higher complexity, and explore its effectiveness on this small dataset.
* To appear in Proceedings of the Student Research Workshop at the North American Association for Computational Linguistics (NAACL) meeting 2019
End-to-end neural relation extraction using deep biaffine attention
Dec 29, 2018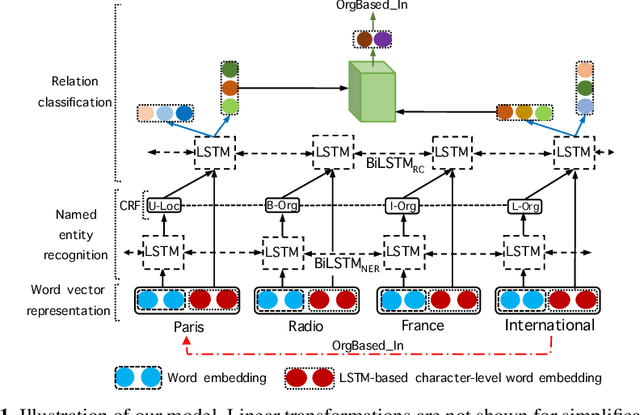
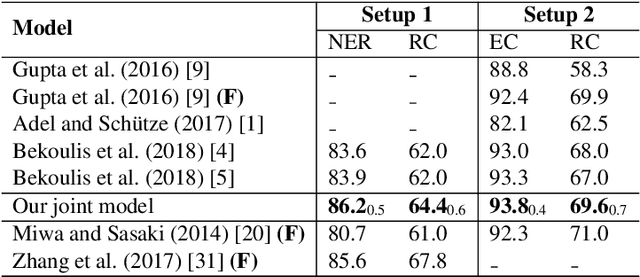
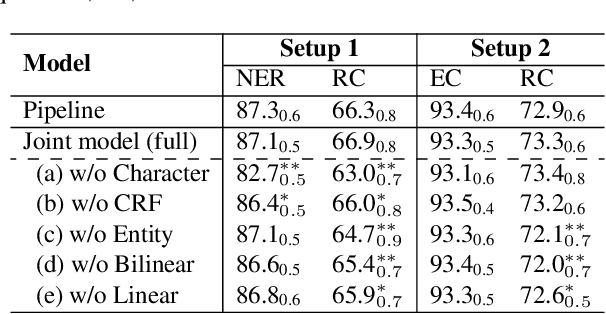
We propose a neural network model for joint extraction of named entities and relations between them, without any hand-crafted features. The key contribution of our model is to extend a BiLSTM-CRF-based entity recognition model with a deep biaffine attention layer to model second-order interactions between latent features for relation classification, specifically attending to the role of an entity in a directional relationship. On the benchmark "relation and entity recognition" dataset CoNLL04, experimental results show that our model outperforms previous models, producing new state-of-the-art performances.
Comparing CNN and LSTM character-level embeddings in BiLSTM-CRF models for chemical and disease named entity recognition
Aug 25, 2018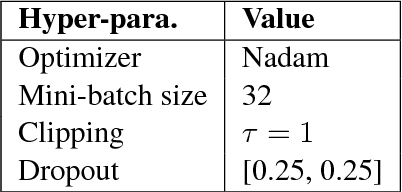
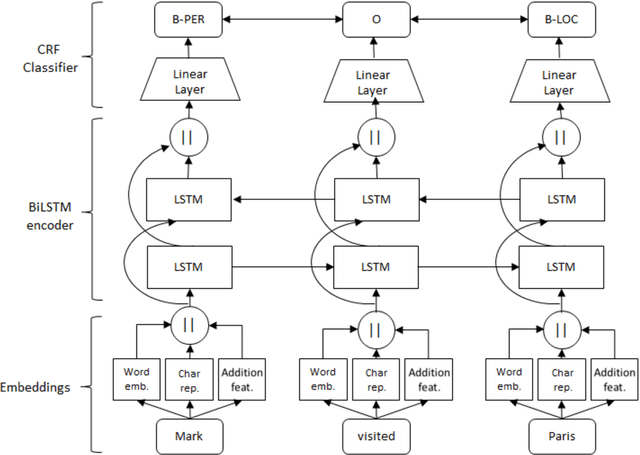

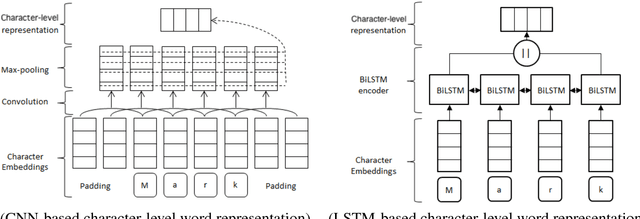
We compare the use of LSTM-based and CNN-based character-level word embeddings in BiLSTM-CRF models to approach chemical and disease named entity recognition (NER) tasks. Empirical results over the BioCreative V CDR corpus show that the use of either type of character-level word embeddings in conjunction with the BiLSTM-CRF models leads to comparable state-of-the-art performance. However, the models using CNN-based character-level word embeddings have a computational performance advantage, increasing training time over word-based models by 25% while the LSTM-based character-level word embeddings more than double the required training time.
An improved neural network model for joint POS tagging and dependency parsing
Aug 20, 2018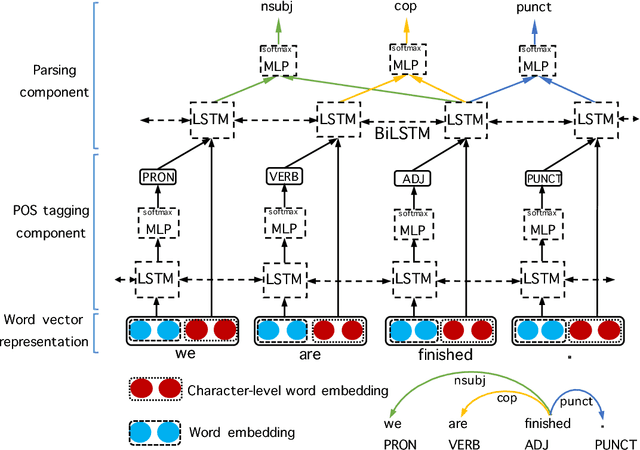
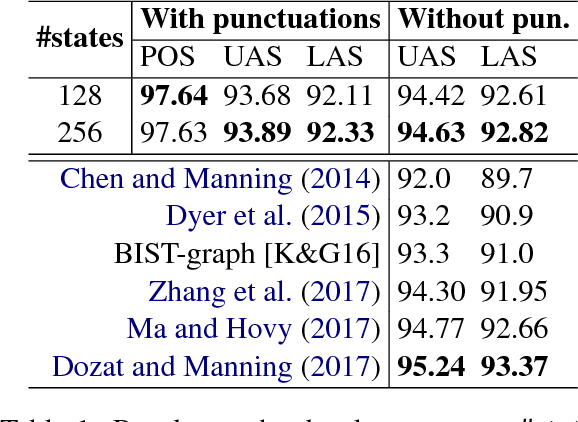
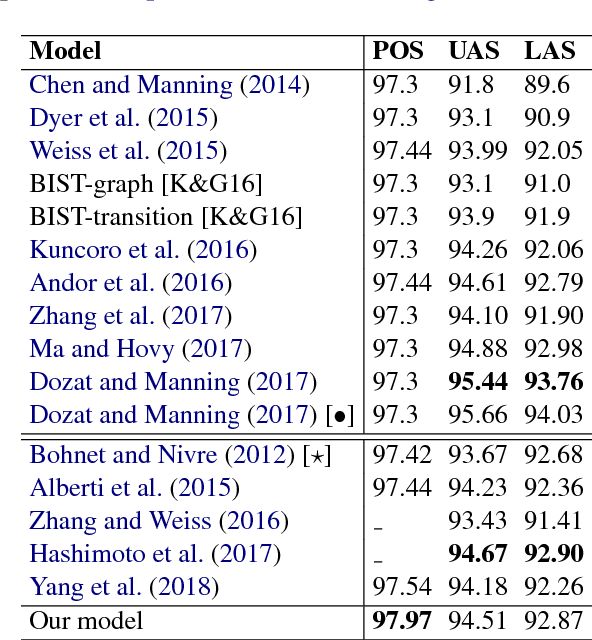
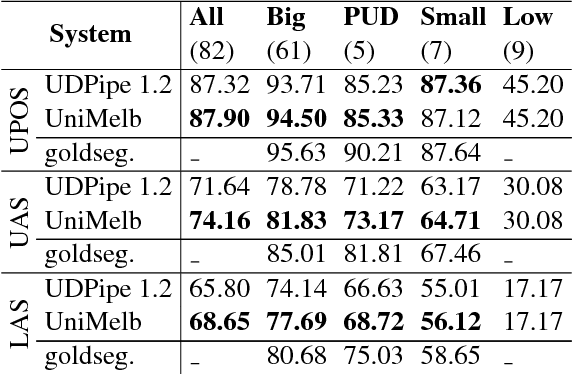
We propose a novel neural network model for joint part-of-speech (POS) tagging and dependency parsing. Our model extends the well-known BIST graph-based dependency parser (Kiperwasser and Goldberg, 2016) by incorporating a BiLSTM-based tagging component to produce automatically predicted POS tags for the parser. On the benchmark English Penn treebank, our model obtains strong UAS and LAS scores at 94.51% and 92.87%, respectively, producing 1.5+% absolute improvements to the BIST graph-based parser, and also obtaining a state-of-the-art POS tagging accuracy at 97.97%. Furthermore, experimental results on parsing 61 "big" Universal Dependencies treebanks from raw texts show that our model outperforms the baseline UDPipe (Straka and Strakov\'a, 2017) with 0.8% higher average POS tagging score and 3.6% higher average LAS score. In addition, with our model, we also obtain state-of-the-art downstream task scores for biomedical event extraction and opinion analysis applications. Our code is available together with all pre-trained models at: https://github.com/datquocnguyen/jPTDP
From POS tagging to dependency parsing for biomedical event extraction
Aug 11, 2018
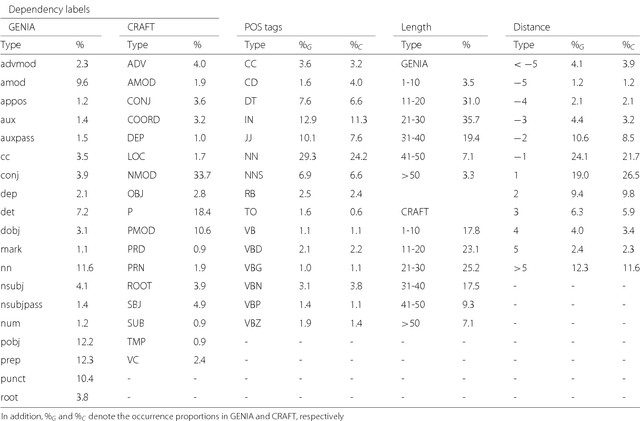
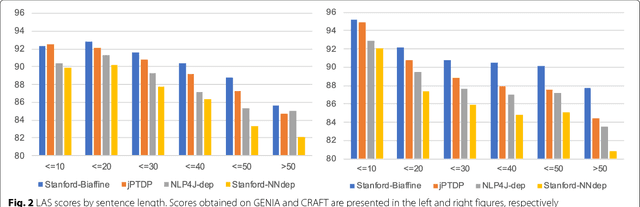
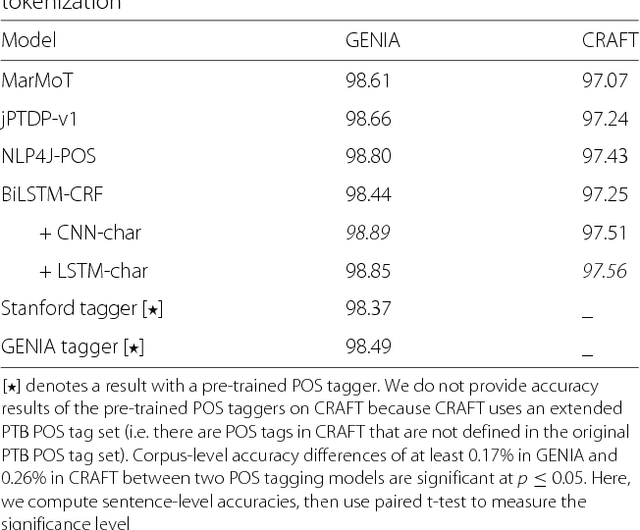
Given the importance of relation or event extraction from biomedical research publications to support knowledge capture and synthesis, and the strong dependency of approaches to this information extraction task on syntactic information, it is valuable to understand which approaches to syntactic processing of biomedical text have the highest performance. In this paper, we perform an empirical study comparing state-of-the-art traditional feature-based and neural network-based models for two core NLP tasks of POS tagging and dependency parsing on two benchmark biomedical corpora, GENIA and CRAFT. To the best of our knowledge, there is no recent work making such comparisons in the biomedical context; specifically no detailed analysis of neural models on this data is available. We also perform a task-oriented evaluation to investigate the influences of these models in a downstream application on biomedical event extraction.
Convolutional neural networks for chemical-disease relation extraction are improved with character-based word embeddings
May 27, 2018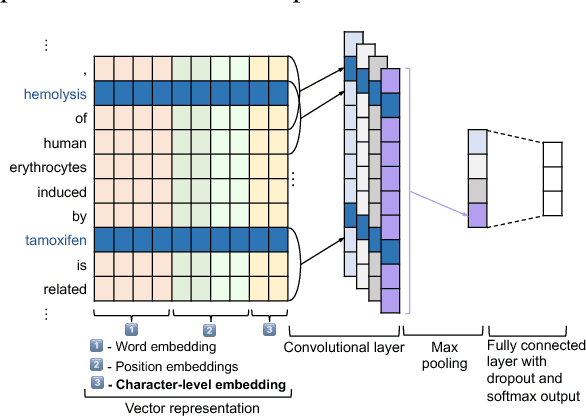
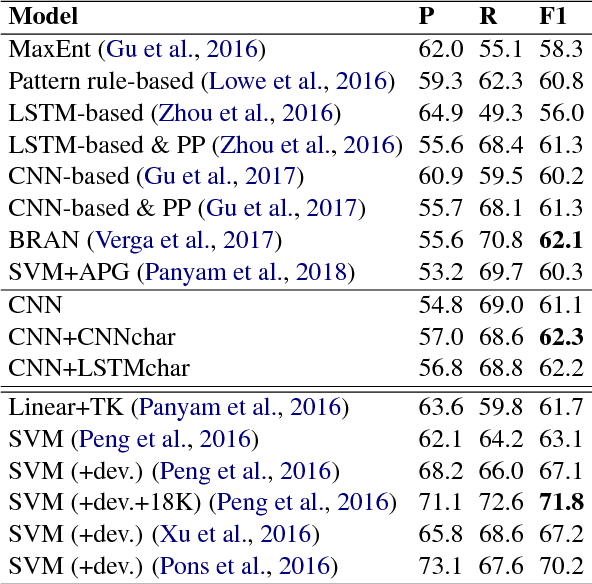
We investigate the incorporation of character-based word representations into a standard CNN-based relation extraction model. We experiment with two common neural architectures, CNN and LSTM, to learn word vector representations from character embeddings. Through a task on the BioCreative-V CDR corpus, extracting relationships between chemicals and diseases, we show that models exploiting the character-based word representations improve on models that do not use this information, obtaining state-of-the-art result relative to previous neural approaches.
A Framework to Adjust Dependency Measure Estimates for Chance
Jan 20, 2016
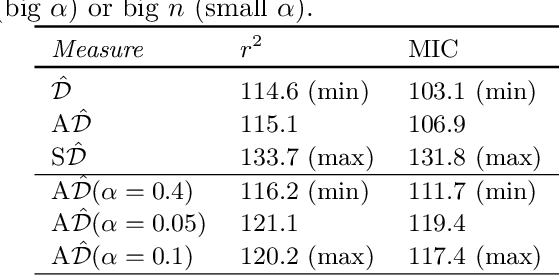
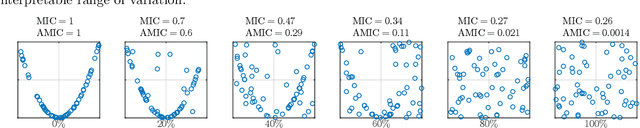
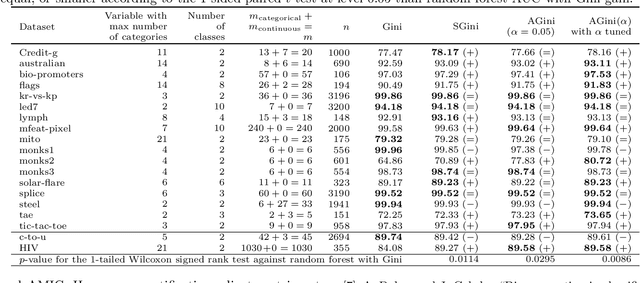
Estimating the strength of dependency between two variables is fundamental for exploratory analysis and many other applications in data mining. For example: non-linear dependencies between two continuous variables can be explored with the Maximal Information Coefficient (MIC); and categorical variables that are dependent to the target class are selected using Gini gain in random forests. Nonetheless, because dependency measures are estimated on finite samples, the interpretability of their quantification and the accuracy when ranking dependencies become challenging. Dependency estimates are not equal to 0 when variables are independent, cannot be compared if computed on different sample size, and they are inflated by chance on variables with more categories. In this paper, we propose a framework to adjust dependency measure estimates on finite samples. Our adjustments, which are simple and applicable to any dependency measure, are helpful in improving interpretability when quantifying dependency and in improving accuracy on the task of ranking dependencies. In particular, we demonstrate that our approach enhances the interpretability of MIC when used as a proxy for the amount of noise between variables, and to gain accuracy when ranking variables during the splitting procedure in random forests.