 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic feature learning using cross-domain articulatory measurements
Mar 20, 2018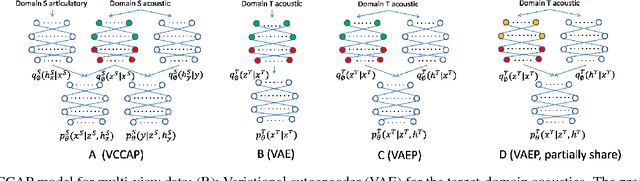

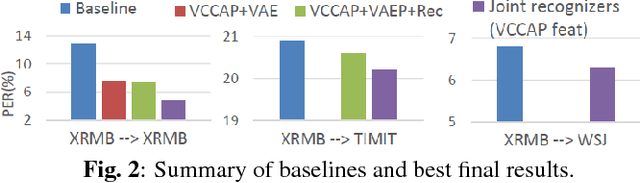
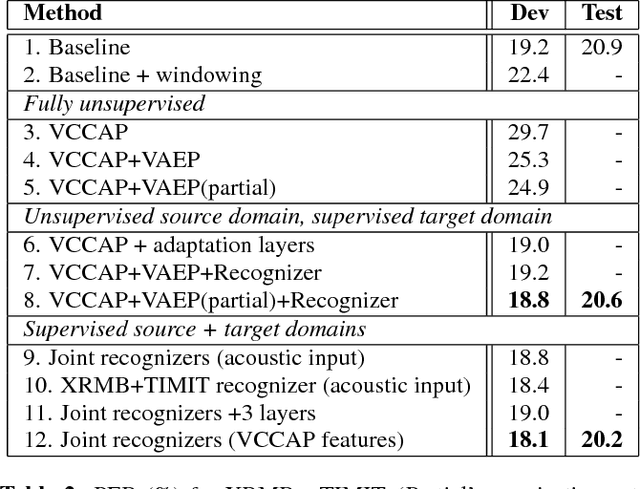
Previous work has shown that it is possible to improve speech recognition by learning acoustic features from paired acoustic-articulatory data, for example by using canonical correlation analysis (CCA) or its deep extensions. One limitation of this prior work is that the learned feature models are difficult to port to new datasets or domains, and articulatory data is not available for most speech corpora. In this work we study the problem of acoustic feature learning in the setting where we have access to an external, domain-mismatched dataset of paired speech and articulatory measurements, either with or without labels. We develop methods for acoustic feature learning in these settings, based on deep variational CCA and extensions that use both source and target domain data and labels. Using this approach, we improve phonetic recognition accuracies on both TIMIT and Wall Street Journal and analyze a number of design choices.
A Study of All-Convolutional Encoders for Connectionist Temporal Classification
Feb 15, 2018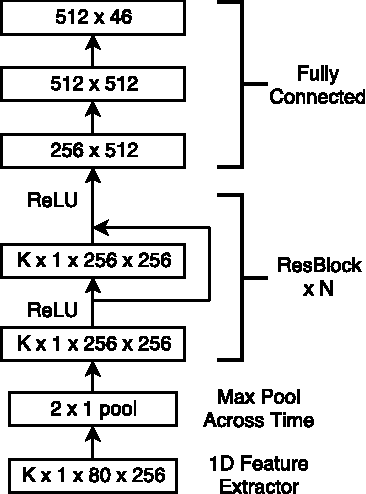
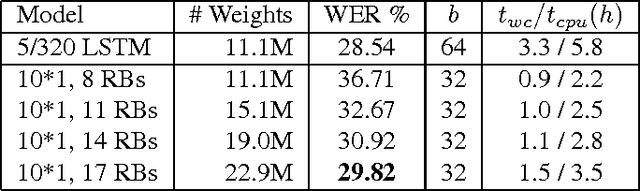
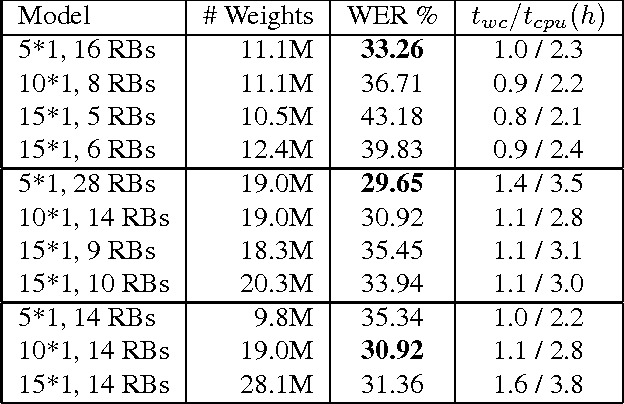
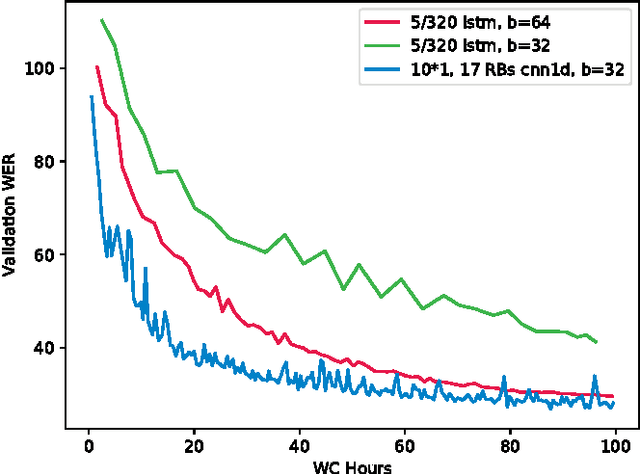
Connectionist temporal classification (CTC) is a popular sequence prediction approach for automatic speech recognition that is typically used with models based on recurrent neural networks (RNNs). We explore whether deep convolutional neural networks (CNNs) can be used effectively instead of RNNs as the "encoder" in CTC. CNNs lack an explicit representation of the entire sequence, but have the advantage that they are much faster to train. We present an exploration of CNNs as encoders for CTC models, in the context of character-based (lexicon-free) automatic speech recognition. In particular, we explore a range of one-dimensional convolutional layers, which are particularly efficient. We compare the performance of our CNN-based models against typical RNNbased models in terms of training time, decoding time, model size and word error rate (WER) on the Switchboard Eval2000 corpus. We find that our CNN-based models are close in performance to LSTMs, while not matching them, and are much faster to train and decode.
Multitask training with unlabeled data for end-to-end sign language fingerspelling recognition
Oct 09, 2017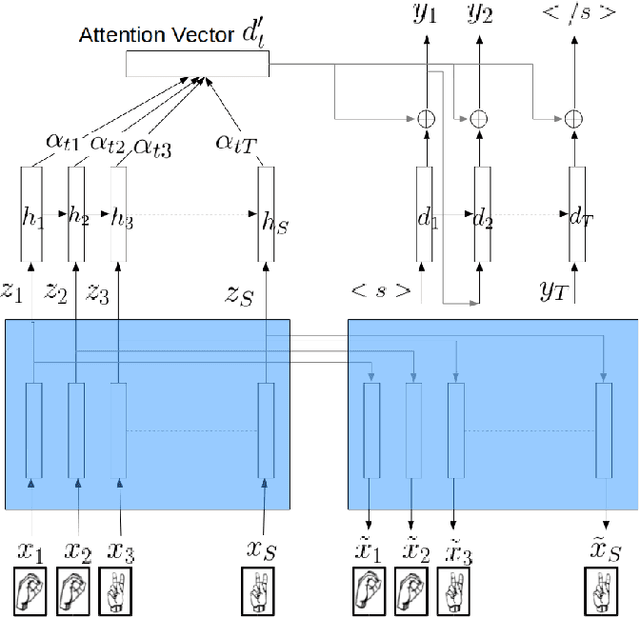
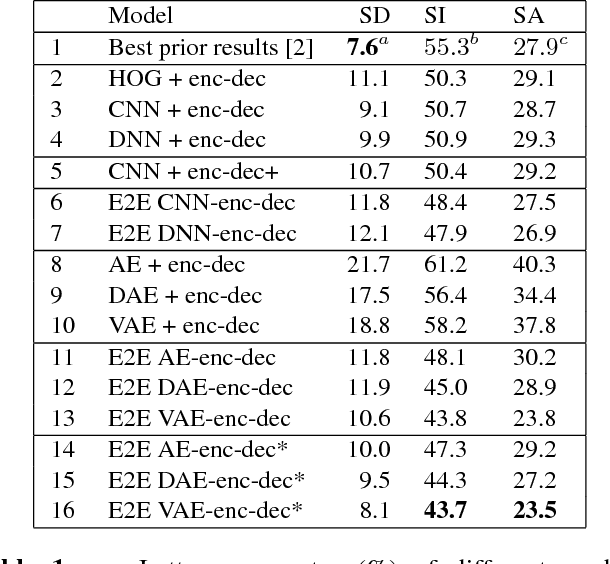


We address the problem of automatic American Sign Language fingerspelling recognition from video. Prior work has largely relied on frame-level labels, hand-crafted features, or other constraints, and has been hampered by the scarcity of data for this task. We introduce a model for fingerspelling recognition that addresses these issues. The model consists of an auto-encoder-based feature extractor and an attention-based neural encoder-decoder, which are trained jointly. The model receives a sequence of image frames and outputs the fingerspelled word, without relying on any frame-level training labels or hand-crafted features. In addition, the auto-encoder subcomponent makes it possible to leverage unlabeled data to improve the feature learning. The model achieves 11.6% and 4.4% absolute letter accuracy improvement respectively in signer-independent and signer- adapted fingerspelling recognition over previous approaches that required frame-level training labels.
An embedded segmental K-means model for unsupervised segmentation and clustering of speech
Sep 05, 2017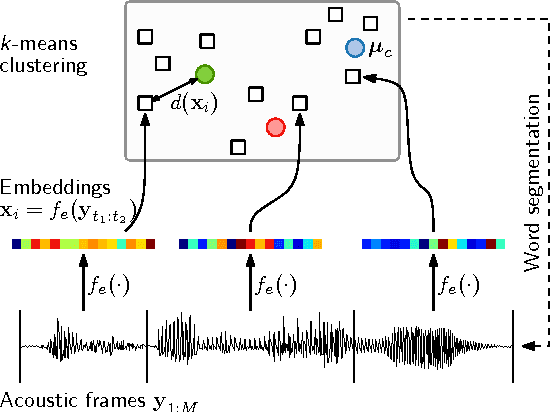
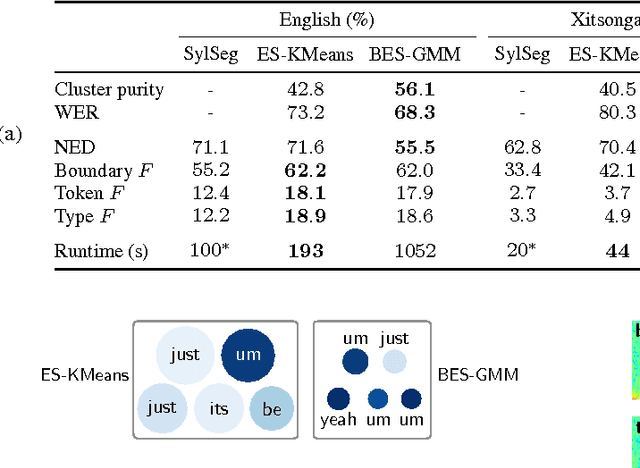
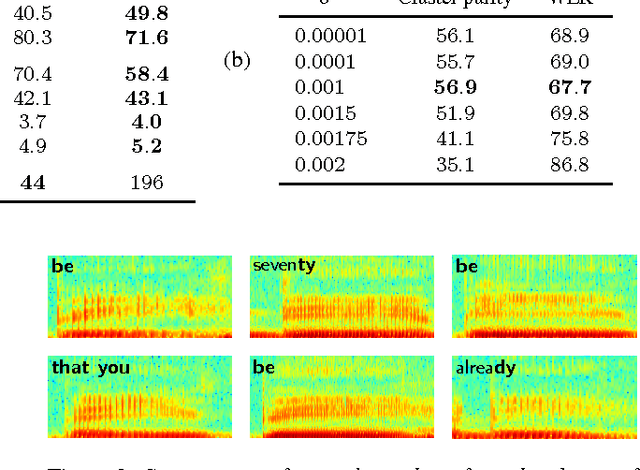
Unsupervised segmentation and clustering of unlabelled speech are core problems in zero-resource speech processing. Most approaches lie at methodological extremes: some use probabilistic Bayesian models with convergence guarantees, while others opt for more efficient heuristic techniques. Despite competitive performance in previous work, the full Bayesian approach is difficult to scale to large speech corpora. We introduce an approximation to a recent Bayesian model that still has a clear objective function but improves efficiency by using hard clustering and segmentation rather than full Bayesian inference. Like its Bayesian counterpart, this embedded segmental K-means model (ES-KMeans) represents arbitrary-length word segments as fixed-dimensional acoustic word embeddings. We first compare ES-KMeans to previous approaches on common English and Xitsonga data sets (5 and 2.5 hours of speech): ES-KMeans outperforms a leading heuristic method in word segmentation, giving similar scores to the Bayesian model while being 5 times faster with fewer hyperparameters. However, its clusters are less pure than those of the other models. We then show that ES-KMeans scales to larger corpora by applying it to the 5 languages of the Zero Resource Speech Challenge 2017 (up to 45 hours), where it performs competitively compared to the challenge baseline.
Acoustic Feature Learning via Deep Variational Canonical Correlation Analysis
Aug 31, 2017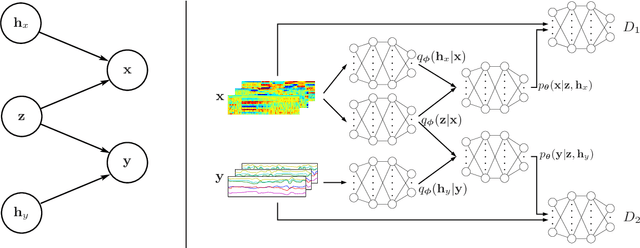

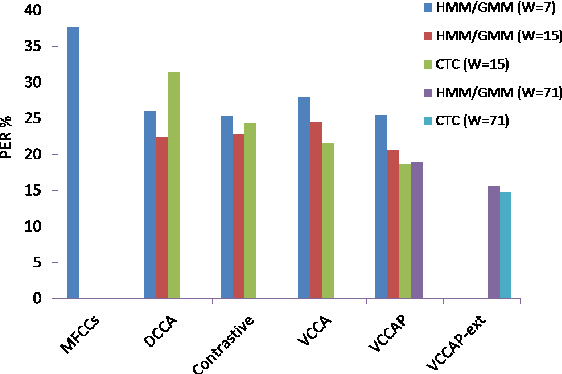
We study the problem of acoustic feature learning in the setting where we have access to another (non-acoustic) modality for feature learning but not at test time. We use deep variational canonical correlation analysis (VCCA), a recently proposed deep generative method for multi-view representation learning. We also extend VCCA with improved latent variable priors and with adversarial learning. Compared to other techniques for multi-view feature learning, VCCA's advantages include an intuitive latent variable interpretation and a variational lower bound objective that can be trained end-to-end efficiently. We compare VCCA and its extensions with previous feature learning methods on the University of Wisconsin X-ray Microbeam Database, and show that VCCA-based feature learning improves over previous methods for speaker-independent phonetic recognition.
End-to-End Neural Segmental Models for Speech Recognition
Aug 15, 2017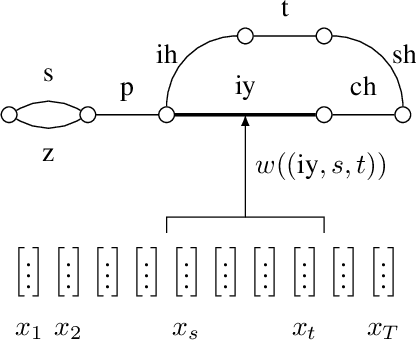
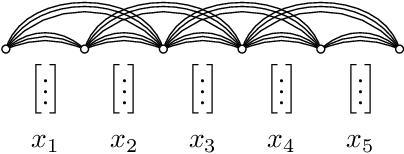
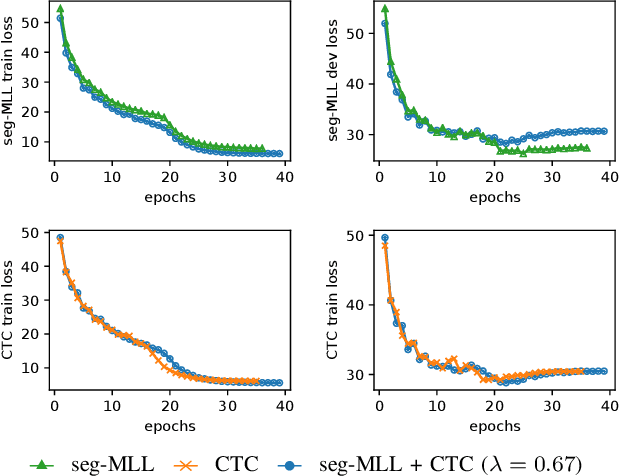
Segmental models are an alternative to frame-based models for sequence prediction, where hypothesized path weights are based on entire segment scores rather than a single frame at a time. Neural segmental models are segmental models that use neural network-based weight functions. Neural segmental models have achieved competitive results for speech recognition, and their end-to-end training has been explored in several studies. In this work, we review neural segmental models, which can be viewed as consisting of a neural network-based acoustic encoder and a finite-state transducer decoder. We study end-to-end segmental models with different weight functions, including ones based on frame-level neural classifiers and on segmental recurrent neural networks. We study how reducing the search space size impacts performance under different weight functions. We also compare several loss functions for end-to-end training. Finally, we explore training approaches, including multi-stage vs. end-to-end training and multitask training that combines segmental and frame-level losses.
Query-by-Example Search with Discriminative Neural Acoustic Word Embeddings
Jun 12, 2017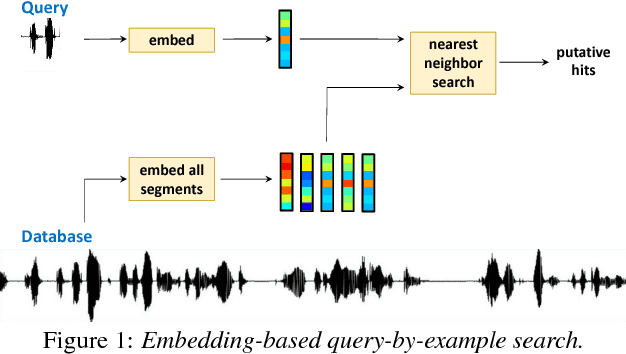
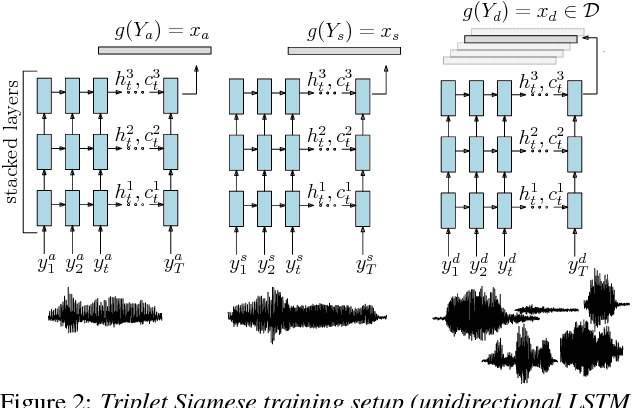

Query-by-example search often uses dynamic time warping (DTW) for comparing queries and proposed matching segments. Recent work has shown that comparing speech segments by representing them as fixed-dimensional vectors --- acoustic word embeddings --- and measuring their vector distance (e.g., cosine distance) can discriminate between words more accurately than DTW-based approaches. We consider an approach to query-by-example search that embeds both the query and database segments according to a neural model, followed by nearest-neighbor search to find the matching segments. Earlier work on embedding-based query-by-example, using template-based acoustic word embeddings, achieved competitive performance. We find that our embeddings, based on recurrent neural networks trained to optimize word discrimination, achieve substantial improvements in performance and run-time efficiency over the previous approaches.
Learning to Embed Words in Context for Syntactic Tasks
Jun 12, 2017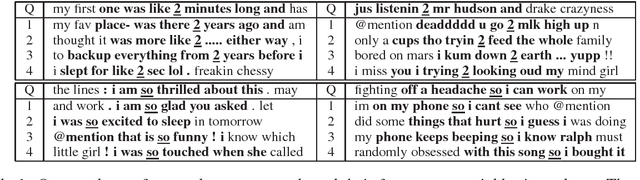


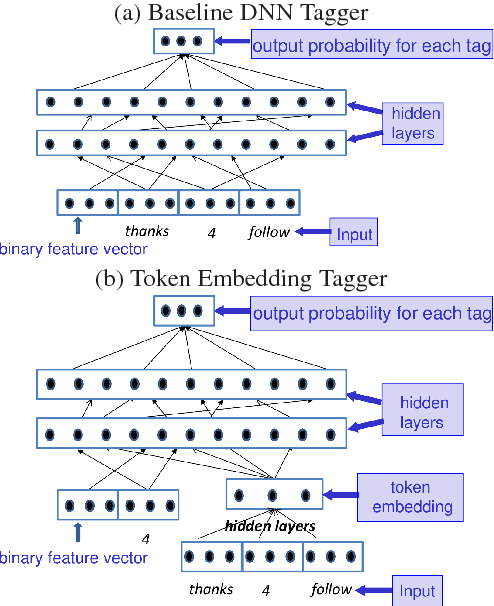
We present models for embedding words in the context of surrounding words. Such models, which we refer to as token embeddings, represent the characteristics of a word that are specific to a given context, such as word sense, syntactic category, and semantic role. We explore simple, efficient token embedding models based on standard neural network architectures. We learn token embeddings on a large amount of unannotated text and evaluate them as features for part-of-speech taggers and dependency parsers trained on much smaller amounts of annotated data. We find that predictors endowed with token embeddings consistently outperform baseline predictors across a range of context window and training set sizes.
Visually grounded learning of keyword prediction from untranscribed speech
May 25, 2017



During language acquisition, infants have the benefit of visual cues to ground spoken language. Robots similarly have access to audio and visual sensors. Recent work has shown that images and spoken captions can be mapped into a meaningful common space, allowing images to be retrieved using speech and vice versa. In this setting of images paired with untranscribed spoken captions, we consider whether computer vision systems can be used to obtain textual labels for the speech. Concretely, we use an image-to-words multi-label visual classifier to tag images with soft textual labels, and then train a neural network to map from the speech to these soft targets. We show that the resulting speech system is able to predict which words occur in an utterance---acting as a spoken bag-of-words classifier---without seeing any parallel speech and text. We find that the model often confuses semantically related words, e.g. "man" and "person", making it even more effective as a semantic keyword spotter.
Multitask Learning with Low-Level Auxiliary Tasks for Encoder-Decoder Based Speech Recognition
Apr 19, 2017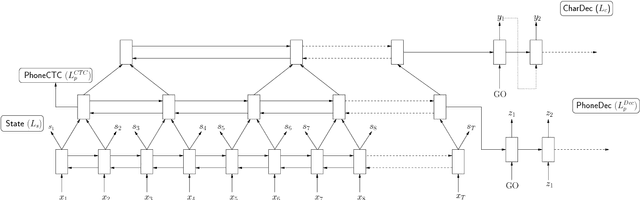
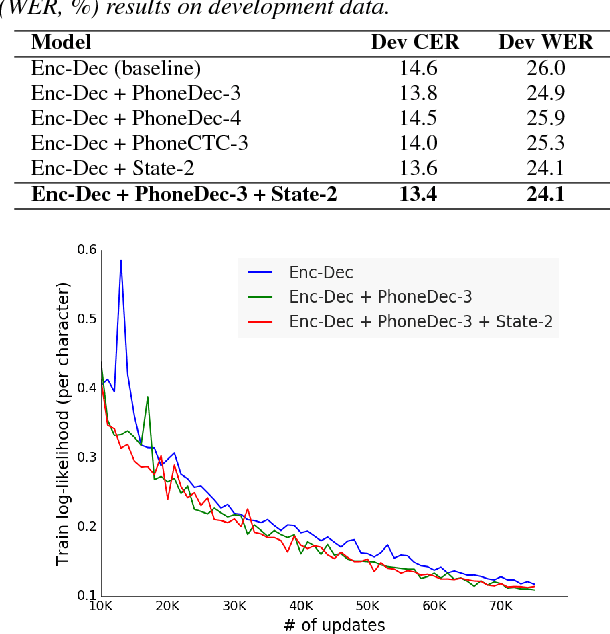
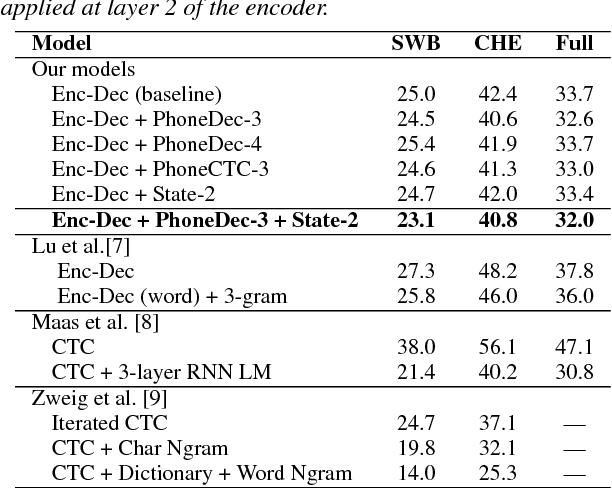
End-to-end training of deep learning-based models allows for implicit learning of intermediate representations based on the final task loss. However, the end-to-end approach ignores the useful domain knowledge encoded in explicit intermediate-level supervision. We hypothesize that using intermediate representations as auxiliary supervision at lower levels of deep networks may be a good way of combining the advantages of end-to-end training and more traditional pipeline approaches. We present experiments on conversational speech recognition where we use lower-level tasks, such as phoneme recognition, in a multitask training approach with an encoder-decoder model for direct character transcription. We compare multiple types of lower-level tasks and analyze the effects of the auxiliary tasks. Our results on the Switchboard corpus show that this approach improves recognition accuracy over a standard encoder-decoder model on the Eval2000 test set.