 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlternating Approach-Putt Models for Multi-Stage Speech Enhancement
Aug 14, 2025



Speech enhancement using artificial neural networks aims to remove noise from noisy speech signals while preserving the speech content. However, speech enhancement networks often introduce distortions to the speech signal, referred to as artifacts, which can degrade audio quality. In this work, we propose a post-processing neural network designed to mitigate artifacts introduced by speech enhancement models. Inspired by the analogy of making a `Putt' after an `Approach' in golf, we name our model PuttNet. We demonstrate that alternating between a speech enhancement model and the proposed Putt model leads to improved speech quality, as measured by perceptual quality scores (PESQ), objective intelligibility (STOI), and background noise intrusiveness (CBAK) scores. Furthermore, we illustrate with graphical analysis why this alternating Approach outperforms repeated application of either model alone.
Fast frequency discrimination and phoneme recognition using a biomimetic membrane coupled to a neural network
Apr 09, 2020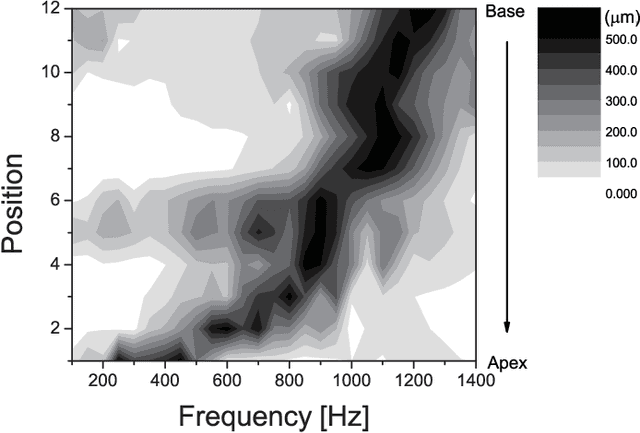
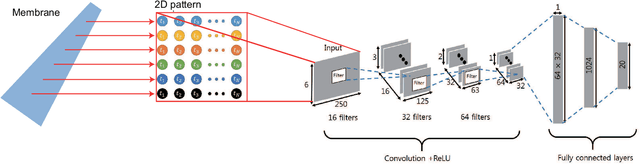
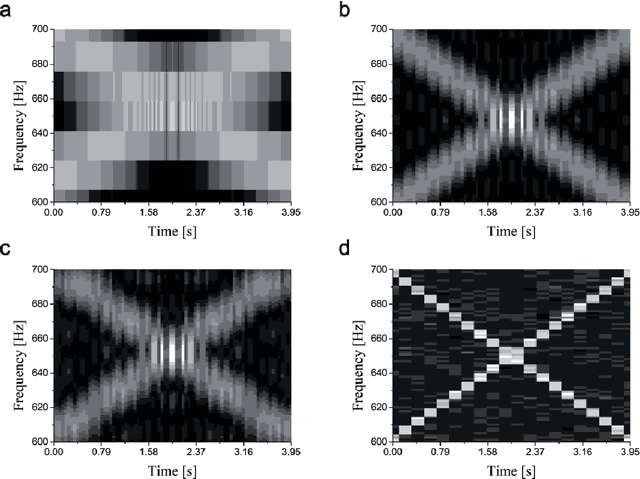
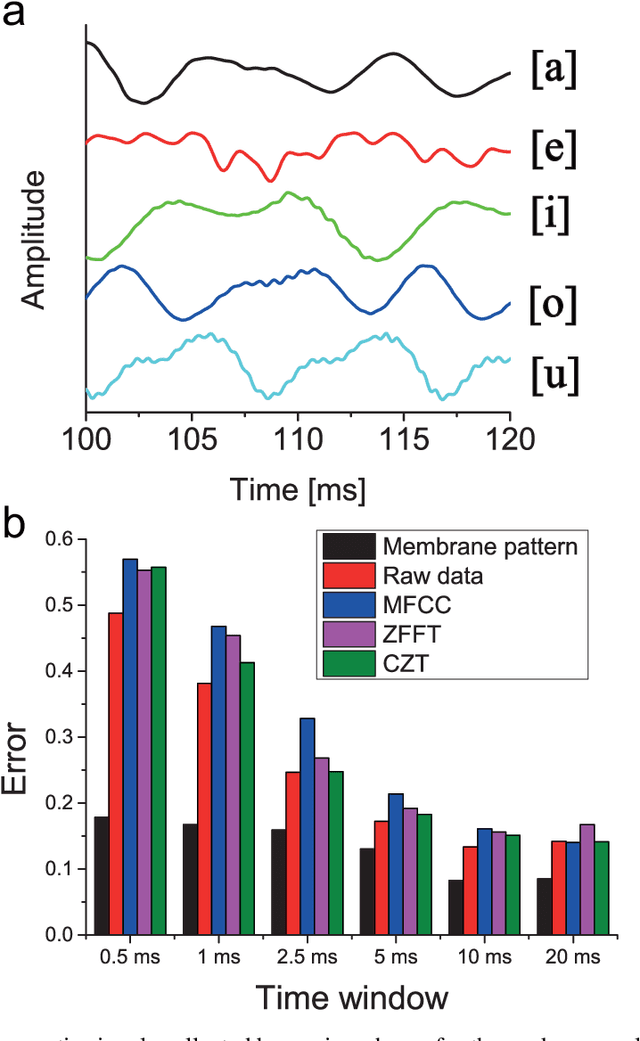
In the human ear, the basilar membrane plays a central role in sound recognition. When excited by sound, this membrane responds with a frequency-dependent displacement pattern that is detected and identified by the auditory hair cells combined with the human neural system. Inspired by this structure, we designed and fabricated an artificial membrane that produces a spatial displacement pattern in response to an audible signal, which we used to train a convolutional neural network (CNN). When trained with single frequency tones, this system can unambiguously distinguish tones closely spaced in frequency. When instead trained to recognize spoken vowels, this system outperforms existing methods for phoneme recognition, including the discrete Fourier transform (DFT), zoom FFT and chirp z-transform, especially when tested in short time windows. This sound recognition scheme therefore promises significant benefits in fast and accurate sound identification compared to existing methods.
Language and Noise Transfer in Speech Enhancement Generative Adversarial Network
Dec 18, 2017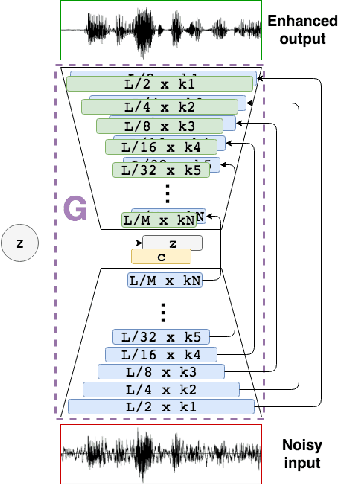
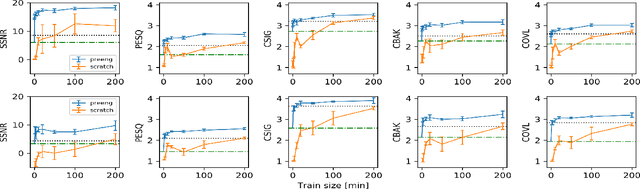
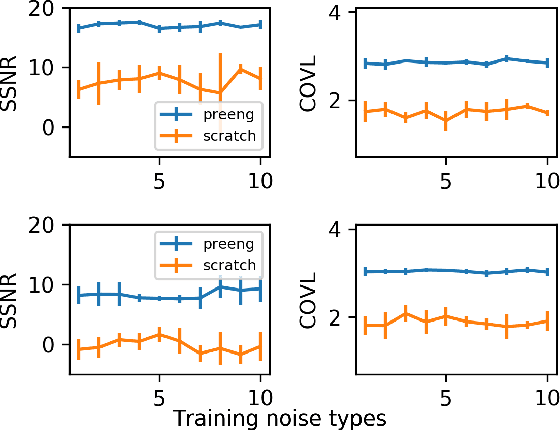
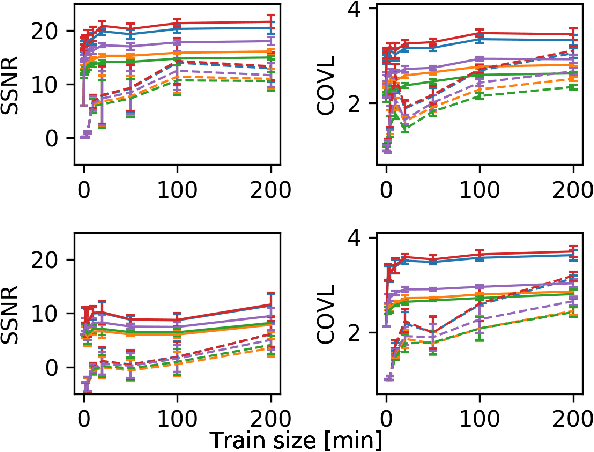
Speech enhancement deep learning systems usually require large amounts of training data to operate in broad conditions or real applications. This makes the adaptability of those systems into new, low resource environments an important topic. In this work, we present the results of adapting a speech enhancement generative adversarial network by finetuning the generator with small amounts of data. We investigate the minimum requirements to obtain a stable behavior in terms of several objective metrics in two very different languages: Catalan and Korean. We also study the variability of test performance to unseen noise as a function of the amount of different types of noise available for training. Results show that adapting a pre-trained English model with 10 min of data already achieves a comparable performance to having two orders of magnitude more data. They also demonstrate the relative stability in test performance with respect to the number of training noise types.