 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model-Assisted Superconducting Qubit Experiments
Mar 09, 2026Superconducting circuits have demonstrated significant potential in quantum information processing and quantum sensing. Implementing novel control and measurement sequences for superconducting qubits is often a complex and time-consuming process, requiring extensive expertise in both the underlying physics and the specific hardware and software. In this work, we introduce a framework that leverages a large language model (LLM) to automate qubit control and measurement. Specifically, our framework conducts experiments by generating and invoking schema-less tools on demand via a knowledge base on instrumental usage and experimental procedures. We showcase this framework with two experiments: an autonomous resonator characterization and a direct reproduction of a quantum non-demolition (QND) characterization of a superconducting qubit from literature. This framework enables rapid deployment of standard control-and-measurement protocols and facilitates implementation of novel experimental procedures, offering a more flexible and user-friendly paradigm for controlling complex quantum hardware.
Fast frequency discrimination and phoneme recognition using a biomimetic membrane coupled to a neural network
Apr 09, 2020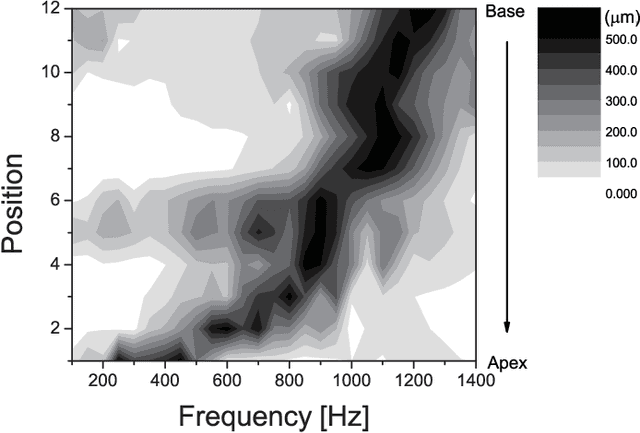
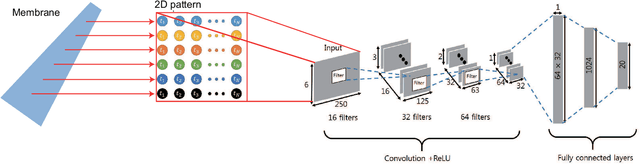
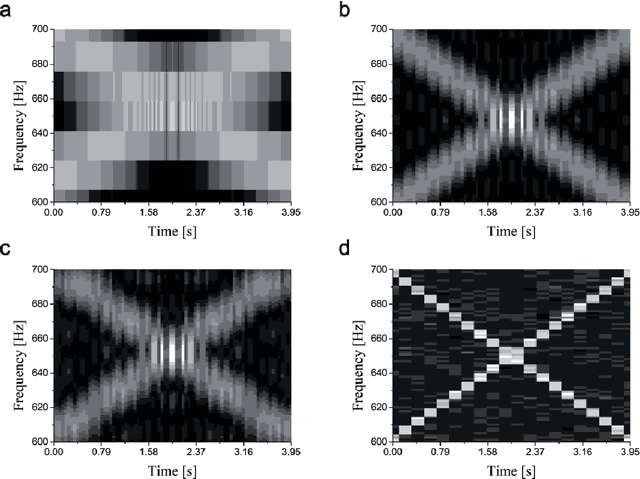
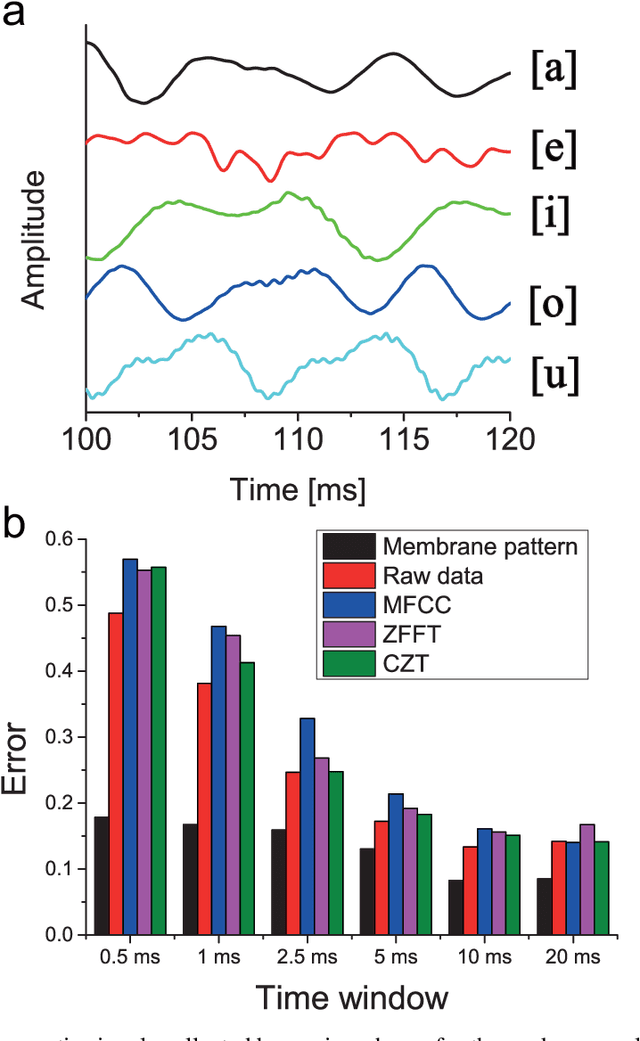
In the human ear, the basilar membrane plays a central role in sound recognition. When excited by sound, this membrane responds with a frequency-dependent displacement pattern that is detected and identified by the auditory hair cells combined with the human neural system. Inspired by this structure, we designed and fabricated an artificial membrane that produces a spatial displacement pattern in response to an audible signal, which we used to train a convolutional neural network (CNN). When trained with single frequency tones, this system can unambiguously distinguish tones closely spaced in frequency. When instead trained to recognize spoken vowels, this system outperforms existing methods for phoneme recognition, including the discrete Fourier transform (DFT), zoom FFT and chirp z-transform, especially when tested in short time windows. This sound recognition scheme therefore promises significant benefits in fast and accurate sound identification compared to existing methods.