 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewardMap: Tackling Sparse Rewards in Fine-grained Visual Reasoning via Multi-Stage Reinforcement Learning
Oct 02, 2025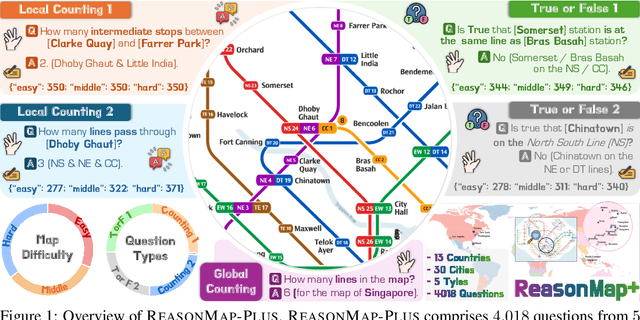
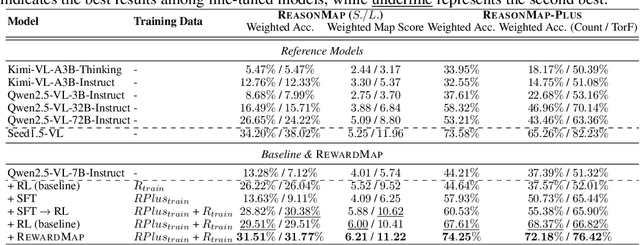
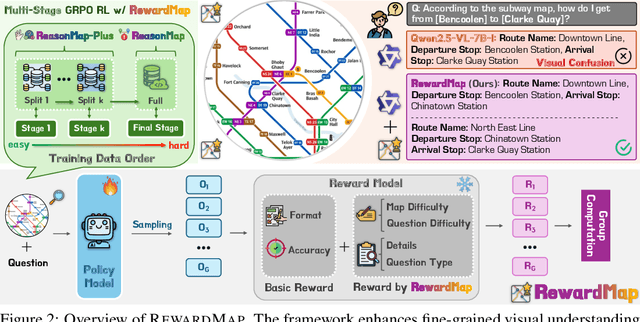
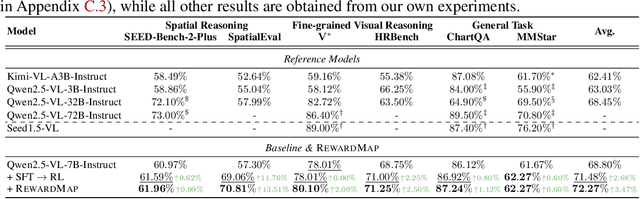
Fine-grained visual reasoning remains a core challenge for multimodal large language models (MLLMs). The recently introduced ReasonMap highlights this gap by showing that even advanced MLLMs struggle with spatial reasoning in structured and information-rich settings such as transit maps, a task of clear practical and scientific importance. However, standard reinforcement learning (RL) on such tasks is impeded by sparse rewards and unstable optimization. To address this, we first construct ReasonMap-Plus, an extended dataset that introduces dense reward signals through Visual Question Answering (VQA) tasks, enabling effective cold-start training of fine-grained visual understanding skills. Next, we propose RewardMap, a multi-stage RL framework designed to improve both visual understanding and reasoning capabilities of MLLMs. RewardMap incorporates two key designs. First, we introduce a difficulty-aware reward design that incorporates detail rewards, directly tackling the sparse rewards while providing richer supervision. Second, we propose a multi-stage RL scheme that bootstraps training from simple perception to complex reasoning tasks, offering a more effective cold-start strategy than conventional Supervised Fine-Tuning (SFT). Experiments on ReasonMap and ReasonMap-Plus demonstrate that each component of RewardMap contributes to consistent performance gains, while their combination yields the best results. Moreover, models trained with RewardMap achieve an average improvement of 3.47% across 6 benchmarks spanning spatial reasoning, fine-grained visual reasoning, and general tasks beyond transit maps, underscoring enhanced visual understanding and reasoning capabilities.
SparseSSM: Efficient Selective Structured State Space Models Can Be Pruned in One-Shot
Jun 11, 2025State-space language models such as Mamba match Transformer quality while permitting linear complexity inference, yet still comprise billions of parameters that hinder deployment. Existing one-shot pruning methods are tailored to attention blocks and fail to account for the time-shared and discretized state-transition matrix at the heart of the selective state-space module (SSM). In this paper, we introduce SparseSSM, the first training-free pruning framework that extends the classic optimal brain surgeon (OBS) framework to state space architectures. Our layer-wise algorithm (i) derives an approximate second-order saliency score that aggregates Hessian-trace information across time steps, (ii) incorporates a component sensitivity analysis to guide feed-forward network (FFN) pruning, which also sheds light on where redundancy resides in mamba architecture, (iii) can be easily extended to semi-structured and structured sparsity. Empirically, we prune 50% of SSM weights without fine-tuning and observe no zero-shot accuracy loss, achieving the current state-of-the-art pruning algorithm for Mamba-based LLMs.