 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-conditioned Image Generation via Generating Representations
Dec 08, 2023



This paper presents $\textbf{R}$epresentation-$\textbf{C}$onditioned image $\textbf{G}$eneration (RCG), a simple yet effective image generation framework which sets a new benchmark in class-unconditional image generation. RCG does not condition on any human annotations. Instead, it conditions on a self-supervised representation distribution which is mapped from the image distribution using a pre-trained encoder. During generation, RCG samples from such representation distribution using a representation diffusion model (RDM), and employs a pixel generator to craft image pixels conditioned on the sampled representation. Such a design provides substantial guidance during the generative process, resulting in high-quality image generation. Tested on ImageNet 256$\times$256, RCG achieves a Frechet Inception Distance (FID) of 3.31 and an Inception Score (IS) of 253.4. These results not only significantly improve the state-of-the-art of class-unconditional image generation but also rival the current leading methods in class-conditional image generation, bridging the long-standing performance gap between these two tasks. Code is available at https://github.com/LTH14/rcg.
Scaling Language-Image Pre-training via Masking
Dec 01, 2022



We present Fast Language-Image Pre-training (FLIP), a simple and more efficient method for training CLIP. Our method randomly masks out and removes a large portion of image patches during training. Masking allows us to learn from more image-text pairs given the same wall-clock time and contrast more samples per iteration with similar memory footprint. It leads to a favorable trade-off between accuracy and training time. In our experiments on 400 million image-text pairs, FLIP improves both accuracy and speed over the no-masking baseline. On a large diversity of downstream tasks, FLIP dominantly outperforms the CLIP counterparts trained on the same data. Facilitated by the speedup, we explore the scaling behavior of increasing the model size, data size, or training length, and report encouraging results and comparisons. We hope that our work will foster future research on scaling vision-language learning.
Masked Autoencoders As Spatiotemporal Learners
May 18, 2022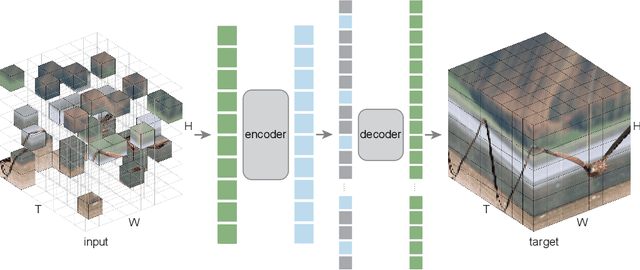



This paper studies a conceptually simple extension of Masked Autoencoders (MAE) to spatiotemporal representation learning from videos. We randomly mask out spacetime patches in videos and learn an autoencoder to reconstruct them in pixels. Interestingly, we show that our MAE method can learn strong representations with almost no inductive bias on spacetime (only except for patch and positional embeddings), and spacetime-agnostic random masking performs the best. We observe that the optimal masking ratio is as high as 90% (vs. 75% on images), supporting the hypothesis that this ratio is related to information redundancy of the data. A high masking ratio leads to a large speedup, e.g., > 4x in wall-clock time or even more. We report competitive results on several challenging video datasets using vanilla Vision Transformers. We observe that MAE can outperform supervised pre-training by large margins. We further report encouraging results of training on real-world, uncurated Instagram data. Our study suggests that the general framework of masked autoencoding (BERT, MAE, etc.) can be a unified methodology for representation learning with minimal domain knowledge.
Exploring Plain Vision Transformer Backbones for Object Detection
Mar 30, 2022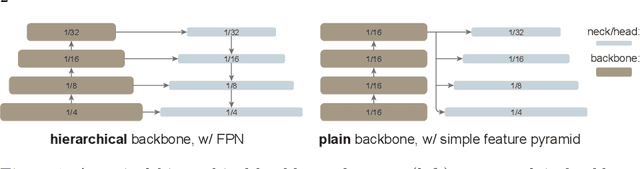



We explore the plain, non-hierarchical Vision Transformer (ViT) as a backbone network for object detection. This design enables the original ViT architecture to be fine-tuned for object detection without needing to redesign a hierarchical backbone for pre-training. With minimal adaptations for fine-tuning, our plain-backbone detector can achieve competitive results. Surprisingly, we observe: (i) it is sufficient to build a simple feature pyramid from a single-scale feature map (without the common FPN design) and (ii) it is sufficient to use window attention (without shifting) aided with very few cross-window propagation blocks. With plain ViT backbones pre-trained as Masked Autoencoders (MAE), our detector, named ViTDet, can compete with the previous leading methods that were all based on hierarchical backbones, reaching up to 61.3 box AP on the COCO dataset using only ImageNet-1K pre-training. We hope our study will draw attention to research on plain-backbone detectors. Code will be made available.
Masked Autoencoders Are Scalable Vision Learners
Dec 02, 2021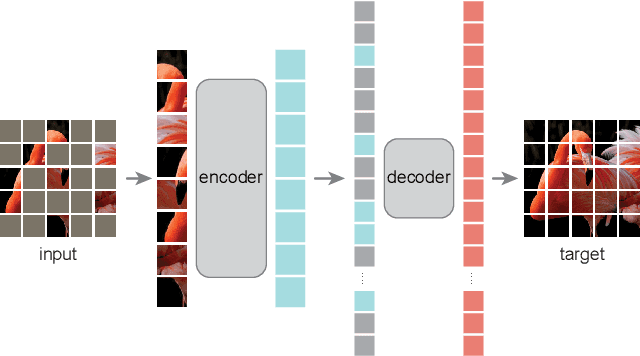
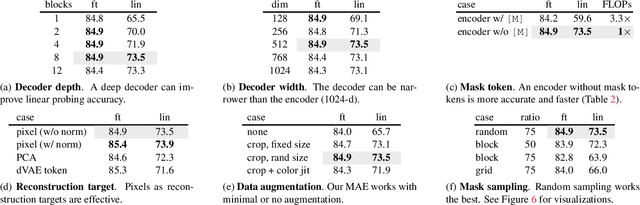

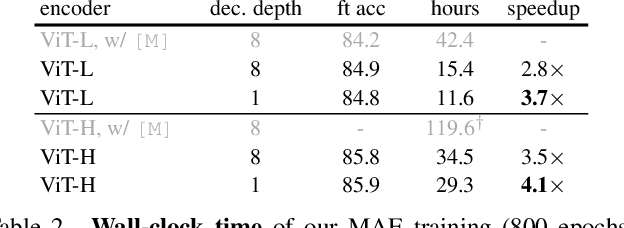
This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels. It is based on two core designs. First, we develop an asymmetric encoder-decoder architecture, with an encoder that operates only on the visible subset of patches (without mask tokens), along with a lightweight decoder that reconstructs the original image from the latent representation and mask tokens. Second, we find that masking a high proportion of the input image, e.g., 75%, yields a nontrivial and meaningful self-supervisory task. Coupling these two designs enables us to train large models efficiently and effectively: we accelerate training (by 3x or more) and improve accuracy. Our scalable approach allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream tasks outperforms supervised pre-training and shows promising scaling behavior.
Benchmarking Detection Transfer Learning with Vision Transformers
Nov 22, 2021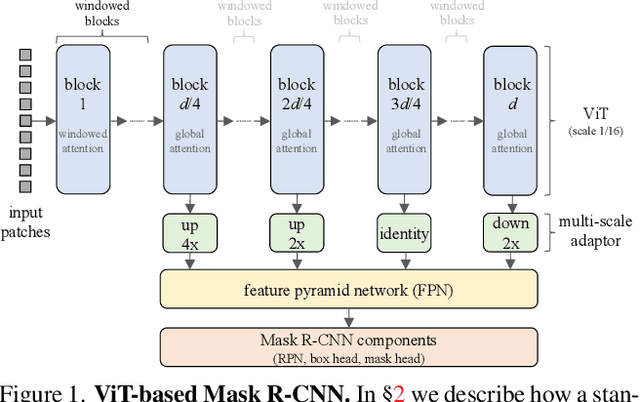
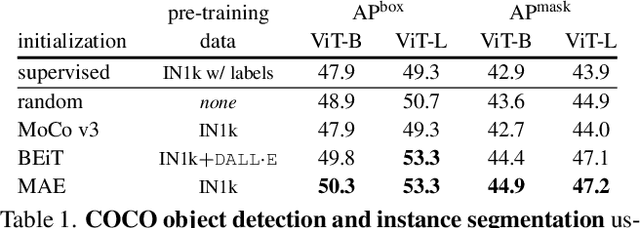
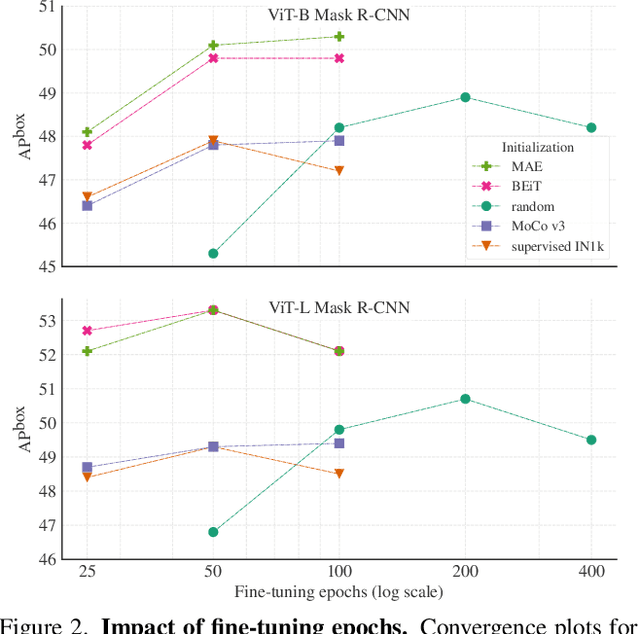

Object detection is a central downstream task used to test if pre-trained network parameters confer benefits, such as improved accuracy or training speed. The complexity of object detection methods can make this benchmarking non-trivial when new architectures, such as Vision Transformer (ViT) models, arrive. These difficulties (e.g., architectural incompatibility, slow training, high memory consumption, unknown training formulae, etc.) have prevented recent studies from benchmarking detection transfer learning with standard ViT models. In this paper, we present training techniques that overcome these challenges, enabling the use of standard ViT models as the backbone of Mask R-CNN. These tools facilitate the primary goal of our study: we compare five ViT initializations, including recent state-of-the-art self-supervised learning methods, supervised initialization, and a strong random initialization baseline. Our results show that recent masking-based unsupervised learning methods may, for the first time, provide convincing transfer learning improvements on COCO, increasing box AP up to 4% (absolute) over supervised and prior self-supervised pre-training methods. Moreover, these masking-based initializations scale better, with the improvement growing as model size increases.
An Empirical Study of Training Self-Supervised Vision Transformers
May 05, 2021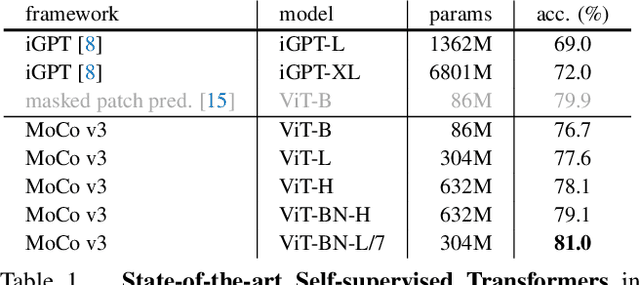
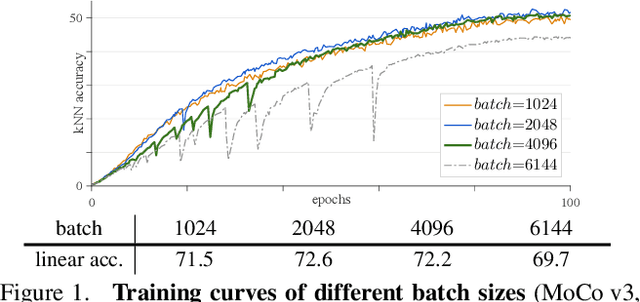
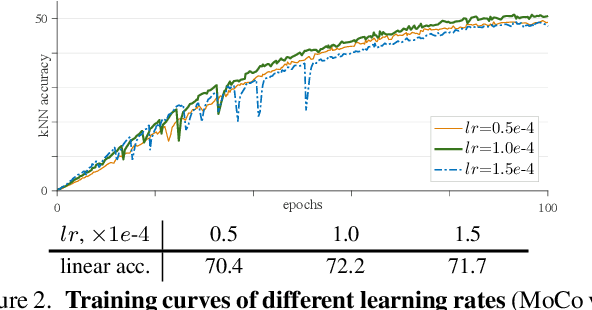
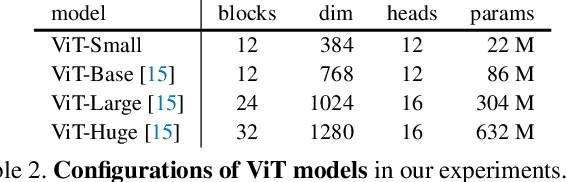
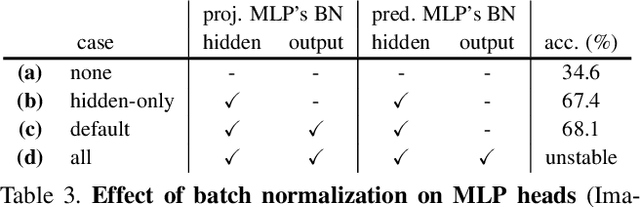
This paper does not describe a novel method. Instead, it studies a straightforward, incremental, yet must-know baseline given the recent progress in computer vision: self-supervised learning for Vision Transformers (ViT). While the training recipes for standard convolutional networks have been highly mature and robust, the recipes for ViT are yet to be built, especially in the self-supervised scenarios where training becomes more challenging. In this work, we go back to basics and investigate the effects of several fundamental components for training self-supervised ViT. We observe that instability is a major issue that degrades accuracy, and it can be hidden by apparently good results. We reveal that these results are indeed partial failure, and they can be improved when training is made more stable. We benchmark ViT results in MoCo v3 and several other self-supervised frameworks, with ablations in various aspects. We discuss the currently positive evidence as well as challenges and open questions. We hope that this work will provide useful data points and experience for future research.
A Large-Scale Study on Unsupervised Spatiotemporal Representation Learning
Apr 29, 2021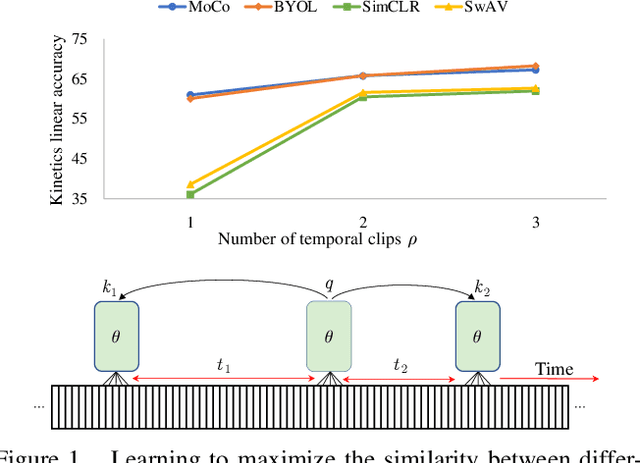

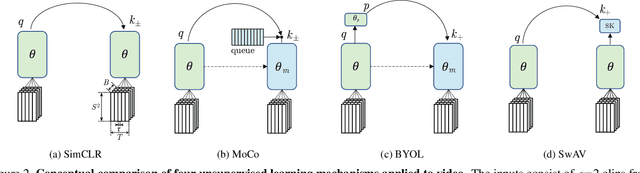
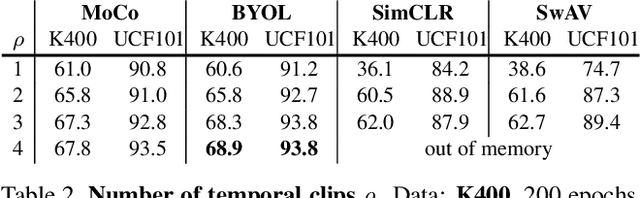
We present a large-scale study on unsupervised spatiotemporal representation learning from videos. With a unified perspective on four recent image-based frameworks, we study a simple objective that can easily generalize all these methods to space-time. Our objective encourages temporally-persistent features in the same video, and in spite of its simplicity, it works surprisingly well across: (i) different unsupervised frameworks, (ii) pre-training datasets, (iii) downstream datasets, and (iv) backbone architectures. We draw a series of intriguing observations from this study, e.g., we discover that encouraging long-spanned persistency can be effective even if the timespan is 60 seconds. In addition to state-of-the-art results in multiple benchmarks, we report a few promising cases in which unsupervised pre-training can outperform its supervised counterpart. Code is made available at https://github.com/facebookresearch/SlowFast
Exploring Simple Siamese Representation Learning
Nov 20, 2020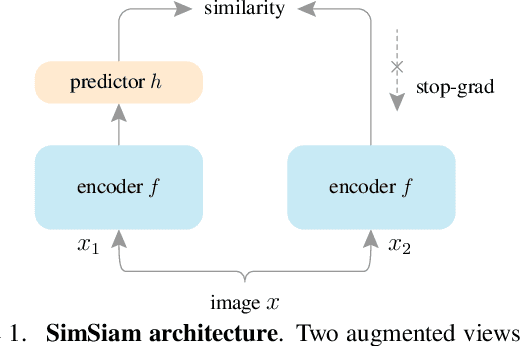


Siamese networks have become a common structure in various recent models for unsupervised visual representation learning. These models maximize the similarity between two augmentations of one image, subject to certain conditions for avoiding collapsing solutions. In this paper, we report surprising empirical results that simple Siamese networks can learn meaningful representations even using none of the following: (i) negative sample pairs, (ii) large batches, (iii) momentum encoders. Our experiments show that collapsing solutions do exist for the loss and structure, but a stop-gradient operation plays an essential role in preventing collapsing. We provide a hypothesis on the implication of stop-gradient, and further show proof-of-concept experiments verifying it. Our "SimSiam" method achieves competitive results on ImageNet and downstream tasks. We hope this simple baseline will motivate people to rethink the roles of Siamese architectures for unsupervised representation learning. Code will be made available.
Graph Structure of Neural Networks
Jul 13, 2020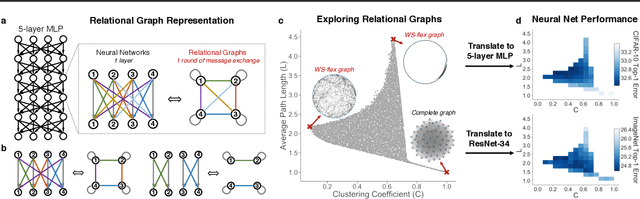

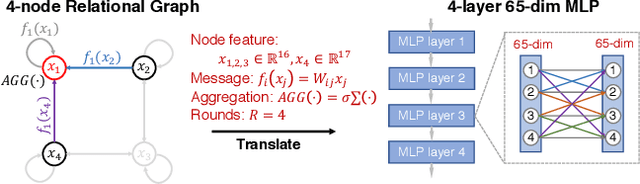
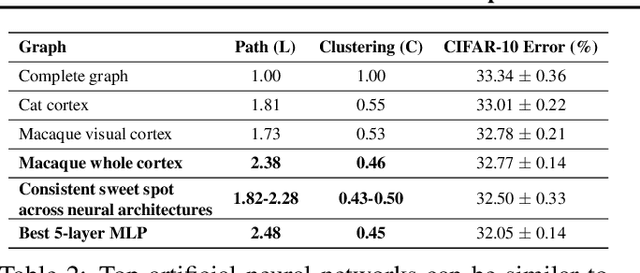
Neural networks are often represented as graphs of connections between neurons. However, despite their wide use, there is currently little understanding of the relationship between the graph structure of the neural network and its predictive performance. Here we systematically investigate how does the graph structure of neural networks affect their predictive performance. To this end, we develop a novel graph-based representation of neural networks called relational graph, where layers of neural network computation correspond to rounds of message exchange along the graph structure. Using this representation we show that: (1) a "sweet spot" of relational graphs leads to neural networks with significantly improved predictive performance; (2) neural network's performance is approximately a smooth function of the clustering coefficient and average path length of its relational graph; (3) our findings are consistent across many different tasks and datasets; (4) the sweet spot can be identified efficiently; (5) top-performing neural networks have graph structure surprisingly similar to those of real biological neural networks. Our work opens new directions for the design of neural architectures and the understanding on neural networks in general.