 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Affinity Fields for Semantic Segmentation
Aug 21, 2018

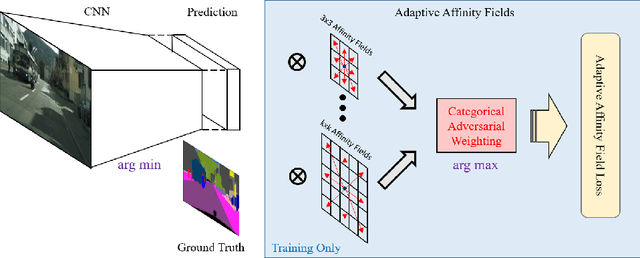
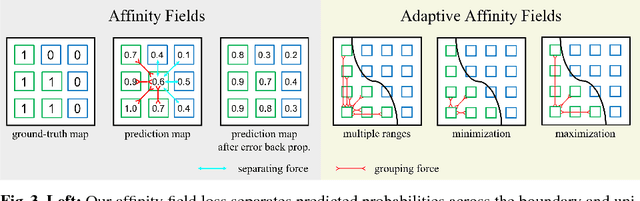
Semantic segmentation has made much progress with increasingly powerful pixel-wise classifiers and incorporating structural priors via Conditional Random Fields (CRF) or Generative Adversarial Networks (GAN). We propose a simpler alternative that learns to verify the spatial structure of segmentation during training only. Unlike existing approaches that enforce semantic labels on individual pixels and match labels between neighbouring pixels, we propose the concept of Adaptive Affinity Fields (AAF) to capture and match the semantic relations between neighbouring pixels in the label space. We use adversarial learning to select the optimal affinity field size for each semantic category. It is formulated as a minimax problem, optimizing our segmentation neural network in a best worst-case learning scenario. AAF is versatile for representing structures as a collection of pixel-centric relations, easier to train than GAN and more efficient than CRF without run-time inference. Our extensive evaluations on PASCAL VOC 2012, Cityscapes, and GTA5 datasets demonstrate its above-par segmentation performance and robust generalization across domains.
Adversarial Structure Matching Loss for Image Segmentation
May 18, 2018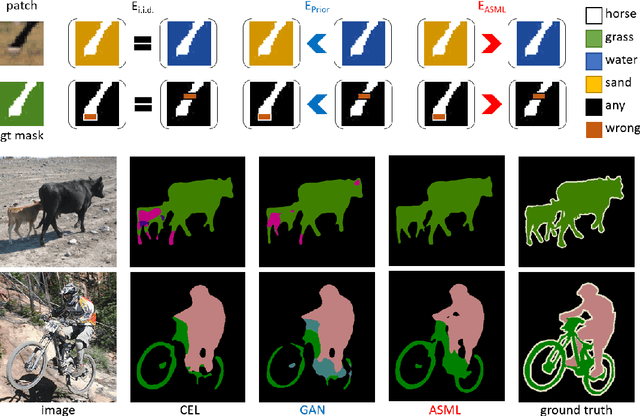
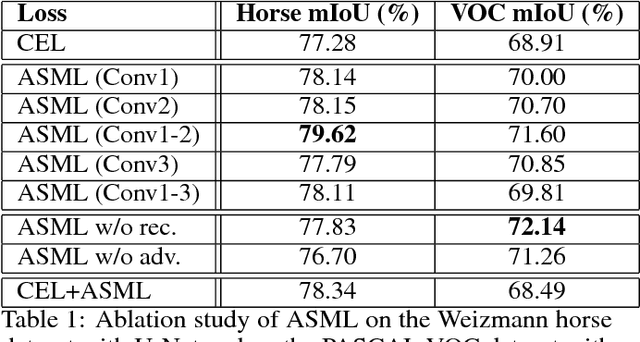
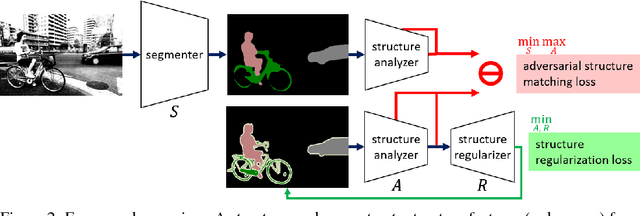
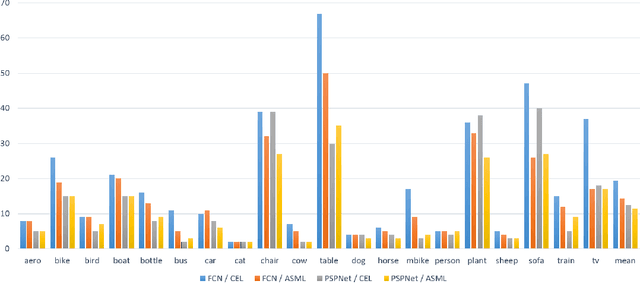
The per-pixel cross-entropy loss (CEL) has been widely used in structured output prediction tasks as a spatial extension of generic image classification. However, its i.i.d. assumption neglects the structural regularity present in natural images. Various attempts have been made to incorporate structural reasoning mostly through structure priors in a cooperative way where co-occuring patterns are encouraged. We, on the other hand, approach this problem from an opposing angle and propose a new framework for training such structured prediction networks via an adversarial process, in which we train a structure analyzer that provides the supervisory signals, the adversarial structure matching loss (ASML). The structure analyzer is trained to maximize ASML, or to exaggerate recurring structural mistakes usually among co-occurring patterns. On the contrary, the structured output prediction network is trained to reduce those mistakes and is thus enabled to distinguish fine-grained structures. As a result, training structured output prediction networks using ASML reduces contextual confusion among objects and improves boundary localization. We demonstrate that ASML outperforms its counterpart CEL especially in context and boundary aspects on figure-ground segmentation and semantic segmentation tasks with various base architectures, such as FCN, U-Net, DeepLab, and PSPNet.
Learning Beyond Human Expertise with Generative Models for Dental Restorations
Mar 30, 2018
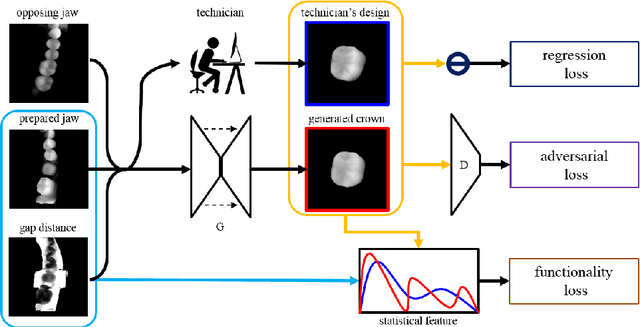
Computer vision has advanced significantly that many discriminative approaches such as object recognition are now widely used in real applications. We present another exciting development that utilizes generative models for the mass customization of medical products such as dental crowns. In the dental industry, it takes a technician years of training to design synthetic crowns that restore the function and integrity of missing teeth. Each crown must be customized to individual patients, and it requires human expertise in a time-consuming and labor-intensive process, even with computer-assisted design software. We develop a fully automatic approach that learns not only from human designs of dental crowns, but also from natural spatial profiles between opposing teeth. The latter is hard to account for by technicians but important for proper biting and chewing functions. Built upon a Generative Adversar-ial Network architecture (GAN), our deep learning model predicts the customized crown-filled depth scan from the crown-missing depth scan and opposing depth scan. We propose to incorporate additional space constraints and statistical compatibility into learning. Our automatic designs exceed human technicians' standards for good morphology and functionality, and our algorithm is being tested for production use.
Contour Detection Using Cost-Sensitive Convolutional Neural Networks
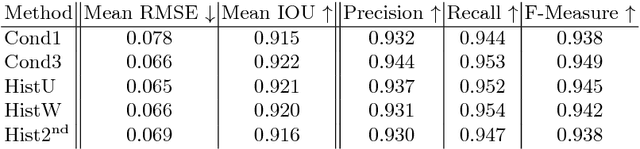
May 12, 2015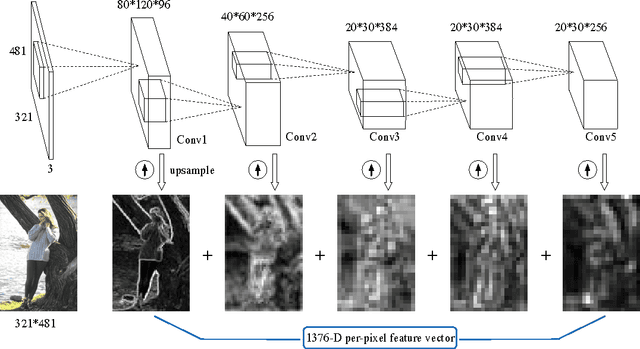
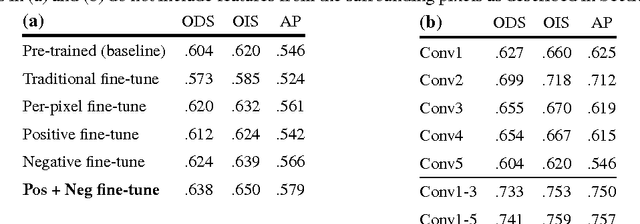
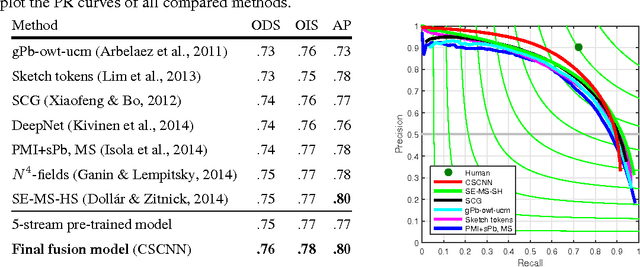
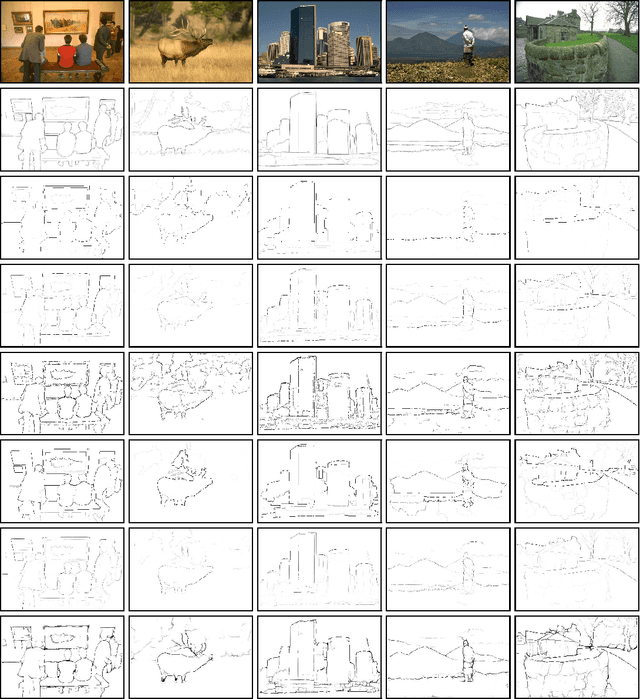
We address the problem of contour detection via per-pixel classifications of edge point. To facilitate the process, the proposed approach leverages with DenseNet, an efficient implementation of multiscale convolutional neural networks (CNNs), to extract an informative feature vector for each pixel and uses an SVM classifier to accomplish contour detection. The main challenge lies in adapting a pre-trained per-image CNN model for yielding per-pixel image features. We propose to base on the DenseNet architecture to achieve pixelwise fine-tuning and then consider a cost-sensitive strategy to further improve the learning with a small dataset of edge and non-edge image patches. In the experiment of contour detection, we look into the effectiveness of combining per-pixel features from different CNN layers and obtain comparable performances to the state-of-the-art on BSDS500.
Pixel-wise Deep Learning for Contour Detection
Apr 08, 2015
We address the problem of contour detection via per-pixel classifications of edge point. To facilitate the process, the proposed approach leverages with DenseNet, an efficient implementation of multiscale convolutional neural networks (CNNs), to extract an informative feature vector for each pixel and uses an SVM classifier to accomplish contour detection. In the experiment of contour detection, we look into the effectiveness of combining per-pixel features from different CNN layers and verify their performance on BSDS500.