 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexturify: Generating Textures on 3D Shape Surfaces
Apr 05, 2022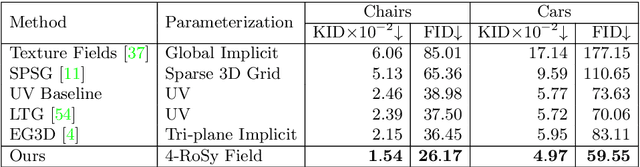
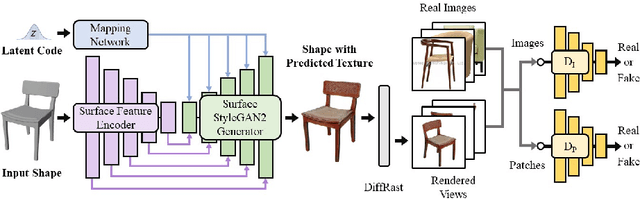

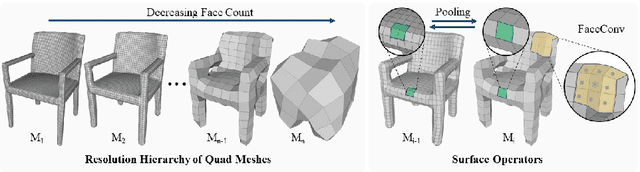
Texture cues on 3D objects are key to compelling visual representations, with the possibility to create high visual fidelity with inherent spatial consistency across different views. Since the availability of textured 3D shapes remains very limited, learning a 3D-supervised data-driven method that predicts a texture based on the 3D input is very challenging. We thus propose Texturify, a GAN-based method that leverages a 3D shape dataset of an object class and learns to reproduce the distribution of appearances observed in real images by generating high-quality textures. In particular, our method does not require any 3D color supervision or correspondence between shape geometry and images to learn the texturing of 3D objects. Texturify operates directly on the surface of the 3D objects by introducing face convolutional operators on a hierarchical 4-RoSy parametrization to generate plausible object-specific textures. Employing differentiable rendering and adversarial losses that critique individual views and consistency across views, we effectively learn the high-quality surface texturing distribution from real-world images. Experiments on car and chair shape collections show that our approach outperforms state of the art by an average of 22% in FID score.
Human-Aware Object Placement for Visual Environment Reconstruction
Mar 28, 2022

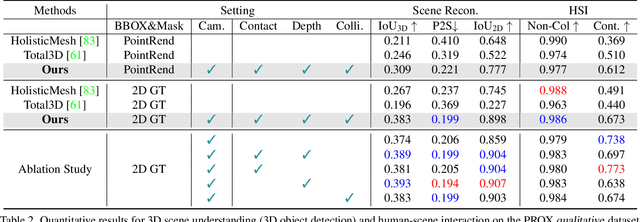
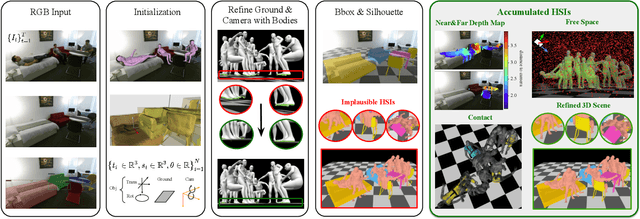
Humans are in constant contact with the world as they move through it and interact with it. This contact is a vital source of information for understanding 3D humans, 3D scenes, and the interactions between them. In fact, we demonstrate that these human-scene interactions (HSIs) can be leveraged to improve the 3D reconstruction of a scene from a monocular RGB video. Our key idea is that, as a person moves through a scene and interacts with it, we accumulate HSIs across multiple input images, and optimize the 3D scene to reconstruct a consistent, physically plausible and functional 3D scene layout. Our optimization-based approach exploits three types of HSI constraints: (1) humans that move in a scene are occluded or occlude objects, thus, defining the depth ordering of the objects, (2) humans move through free space and do not interpenetrate objects, (3) when humans and objects are in contact, the contact surfaces occupy the same place in space. Using these constraints in an optimization formulation across all observations, we significantly improve the 3D scene layout reconstruction. Furthermore, we show that our scene reconstruction can be used to refine the initial 3D human pose and shape (HPS) estimation. We evaluate the 3D scene layout reconstruction and HPS estimation qualitatively and quantitatively using the PROX and PiGraphs datasets. The code and data are available for research purposes at https://mover.is.tue.mpg.de/.
Neural Head Avatars from Monocular RGB Videos
Dec 02, 2021
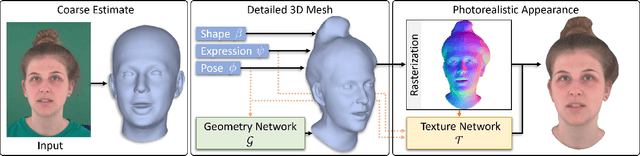
We present Neural Head Avatars, a novel neural representation that explicitly models the surface geometry and appearance of an animatable human avatar that can be used for teleconferencing in AR/VR or other applications in the movie or games industry that rely on a digital human. Our representation can be learned from a monocular RGB portrait video that features a range of different expressions and views. Specifically, we propose a hybrid representation consisting of a morphable model for the coarse shape and expressions of the face, and two feed-forward networks, predicting vertex offsets of the underlying mesh as well as a view- and expression-dependent texture. We demonstrate that this representation is able to accurately extrapolate to unseen poses and view points, and generates natural expressions while providing sharp texture details. Compared to previous works on head avatars, our method provides a disentangled shape and appearance model of the complete human head (including hair) that is compatible with the standard graphics pipeline. Moreover, it quantitatively and qualitatively outperforms current state of the art in terms of reconstruction quality and novel-view synthesis.
Advances in Neural Rendering
Nov 10, 2021Synthesizing photo-realistic images and videos is at the heart of computer graphics and has been the focus of decades of research. Traditionally, synthetic images of a scene are generated using rendering algorithms such as rasterization or ray tracing, which take specifically defined representations of geometry and material properties as input. Collectively, these inputs define the actual scene and what is rendered, and are referred to as the scene representation (where a scene consists of one or more objects). Example scene representations are triangle meshes with accompanied textures (e.g., created by an artist), point clouds (e.g., from a depth sensor), volumetric grids (e.g., from a CT scan), or implicit surface functions (e.g., truncated signed distance fields). The reconstruction of such a scene representation from observations using differentiable rendering losses is known as inverse graphics or inverse rendering. Neural rendering is closely related, and combines ideas from classical computer graphics and machine learning to create algorithms for synthesizing images from real-world observations. Neural rendering is a leap forward towards the goal of synthesizing photo-realistic image and video content. In recent years, we have seen immense progress in this field through hundreds of publications that show different ways to inject learnable components into the rendering pipeline. This state-of-the-art report on advances in neural rendering focuses on methods that combine classical rendering principles with learned 3D scene representations, often now referred to as neural scene representations. A key advantage of these methods is that they are 3D-consistent by design, enabling applications such as novel viewpoint synthesis of a captured scene. In addition to methods that handle static scenes, we cover neural scene representations for modeling non-rigidly deforming objects...
Egocentric Videoconferencing
Jul 07, 2021

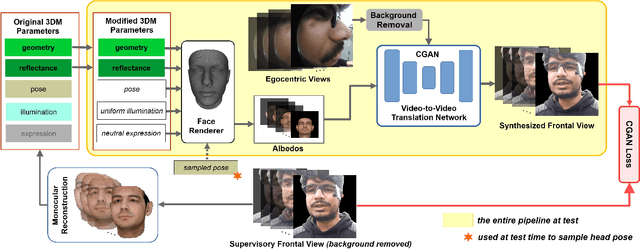

We introduce a method for egocentric videoconferencing that enables hands-free video calls, for instance by people wearing smart glasses or other mixed-reality devices. Videoconferencing portrays valuable non-verbal communication and face expression cues, but usually requires a front-facing camera. Using a frontal camera in a hands-free setting when a person is on the move is impractical. Even holding a mobile phone camera in the front of the face while sitting for a long duration is not convenient. To overcome these issues, we propose a low-cost wearable egocentric camera setup that can be integrated into smart glasses. Our goal is to mimic a classical video call, and therefore, we transform the egocentric perspective of this camera into a front facing video. To this end, we employ a conditional generative adversarial neural network that learns a transition from the highly distorted egocentric views to frontal views common in videoconferencing. Our approach learns to transfer expression details directly from the egocentric view without using a complex intermediate parametric expressions model, as it is used by related face reenactment methods. We successfully handle subtle expressions, not easily captured by parametric blendshape-based solutions, e.g., tongue movement, eye movements, eye blinking, strong expressions and depth varying movements. To get control over the rigid head movements in the target view, we condition the generator on synthetic renderings of a moving neutral face. This allows us to synthesis results at different head poses. Our technique produces temporally smooth video-realistic renderings in real-time using a video-to-video translation network in conjunction with a temporal discriminator. We demonstrate the improved capabilities of our technique by comparing against related state-of-the art approaches.
* Mohamed Elgharib and Mohit Mendiratta contributed equally to this work. http://gvv.mpi-inf.mpg.de/projects/EgoChat/
TransformerFusion: Monocular RGB Scene Reconstruction using Transformers
Jul 05, 2021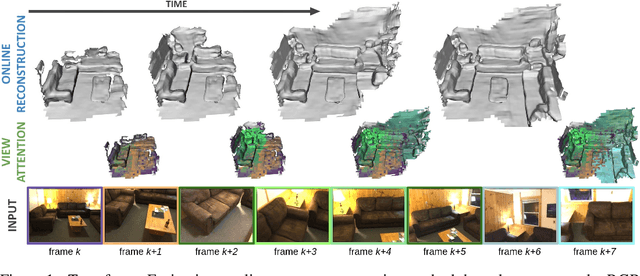
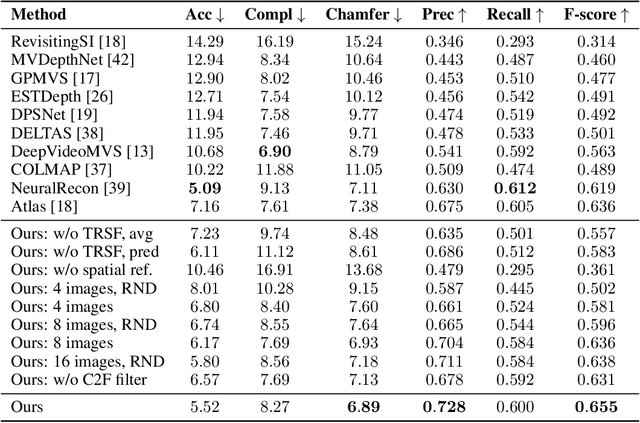
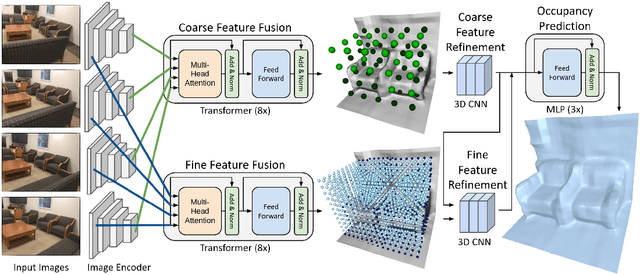

We introduce TransformerFusion, a transformer-based 3D scene reconstruction approach. From an input monocular RGB video, the video frames are processed by a transformer network that fuses the observations into a volumetric feature grid representing the scene; this feature grid is then decoded into an implicit 3D scene representation. Key to our approach is the transformer architecture that enables the network to learn to attend to the most relevant image frames for each 3D location in the scene, supervised only by the scene reconstruction task. Features are fused in a coarse-to-fine fashion, storing fine-level features only where needed, requiring lower memory storage and enabling fusion at interactive rates. The feature grid is then decoded to a higher-resolution scene reconstruction, using an MLP-based surface occupancy prediction from interpolated coarse-to-fine 3D features. Our approach results in an accurate surface reconstruction, outperforming state-of-the-art multi-view stereo depth estimation methods, fully-convolutional 3D reconstruction approaches, and approaches using LSTM- or GRU-based recurrent networks for video sequence fusion.
Neural RGB-D Surface Reconstruction
Apr 09, 2021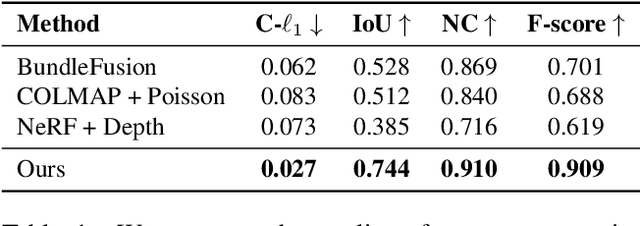
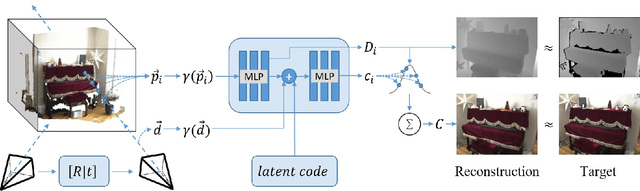
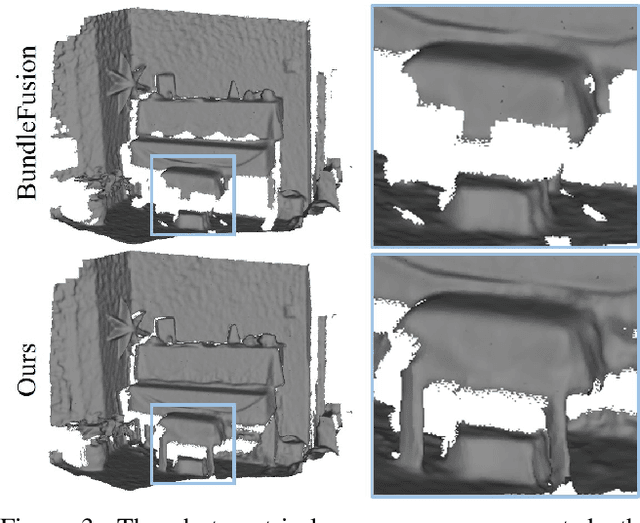
In this work, we explore how to leverage the success of implicit novel view synthesis methods for surface reconstruction. Methods which learn a neural radiance field have shown amazing image synthesis results, but the underlying geometry representation is only a coarse approximation of the real geometry. We demonstrate how depth measurements can be incorporated into the radiance field formulation to produce more detailed and complete reconstruction results than using methods based on either color or depth data alone. In contrast to a density field as the underlying geometry representation, we propose to learn a deep neural network which stores a truncated signed distance field. Using this representation, we show that one can still leverage differentiable volume rendering to estimate color values of the observed images during training to compute a reconstruction loss. This is beneficial for learning the signed distance field in regions with missing depth measurements. Furthermore, we correct misalignment errors of the camera, improving the overall reconstruction quality. In several experiments, we showcase our method and compare to existing works on classical RGB-D fusion and learned representations.
Dynamic Surface Function Networks for Clothed Human Bodies
Apr 08, 2021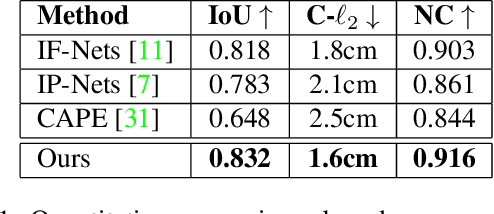
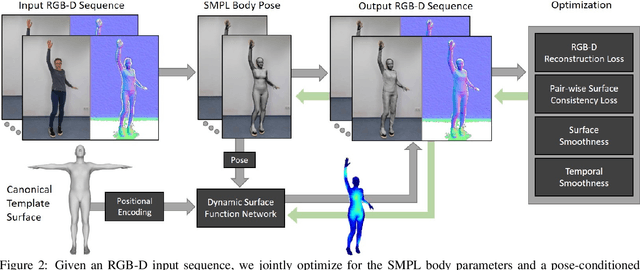
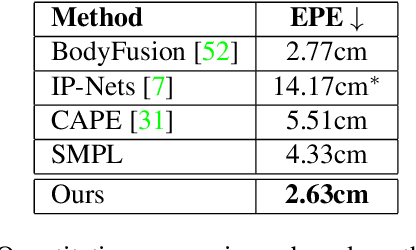
We present a novel method for temporal coherent reconstruction and tracking of clothed humans. Given a monocular RGB-D sequence, we learn a person-specific body model which is based on a dynamic surface function network. To this end, we explicitly model the surface of the person using a multi-layer perceptron (MLP) which is embedded into the canonical space of the SMPL body model. With classical forward rendering, the represented surface can be rasterized using the topology of a template mesh. For each surface point of the template mesh, the MLP is evaluated to predict the actual surface location. To handle pose-dependent deformations, the MLP is conditioned on the SMPL pose parameters. We show that this surface representation as well as the pose parameters can be learned in a self-supervised fashion using the principle of analysis-by-synthesis and differentiable rasterization. As a result, we are able to reconstruct a temporally coherent mesh sequence from the input data. The underlying surface representation can be used to synthesize new animations of the reconstructed person including pose-dependent deformations.
NPMs: Neural Parametric Models for 3D Deformable Shapes
Apr 01, 2021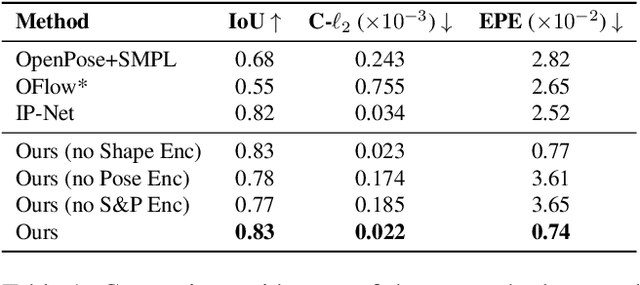
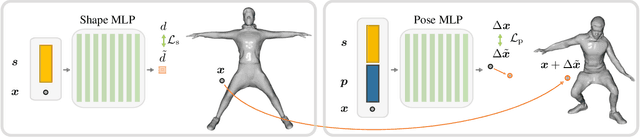

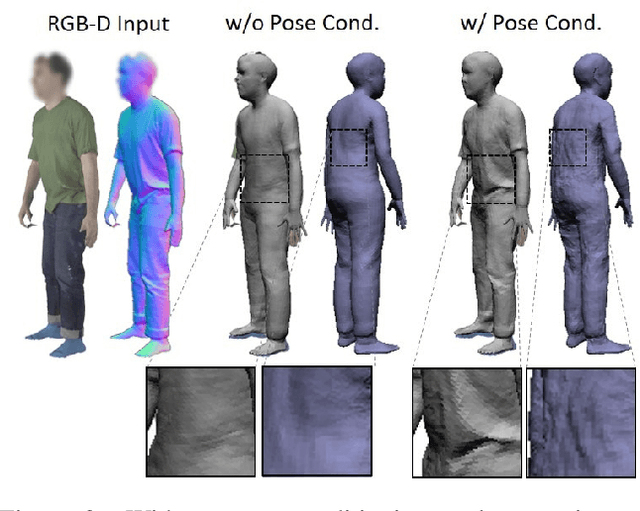
Parametric 3D models have enabled a wide variety of tasks in computer graphics and vision, such as modeling human bodies, faces, and hands. However, the construction of these parametric models is often tedious, as it requires heavy manual tweaking, and they struggle to represent additional complexity and details such as wrinkles or clothing. To this end, we propose Neural Parametric Models (NPMs), a novel, learned alternative to traditional, parametric 3D models, which does not require hand-crafted, object-specific constraints. In particular, we learn to disentangle 4D dynamics into latent-space representations of shape and pose, leveraging the flexibility of recent developments in learned implicit functions. Crucially, once learned, our neural parametric models of shape and pose enable optimization over the learned spaces to fit to new observations, similar to the fitting of a traditional parametric model, e.g., SMPL. This enables NPMs to achieve a significantly more accurate and detailed representation of observed deformable sequences. We show that NPMs improve notably over both parametric and non-parametric state of the art in reconstruction and tracking of monocular depth sequences of clothed humans and hands. Latent-space interpolation as well as shape / pose transfer experiments further demonstrate the usefulness of NPMs.
RetrievalFuse: Neural 3D Scene Reconstruction with a Database
Mar 31, 2021
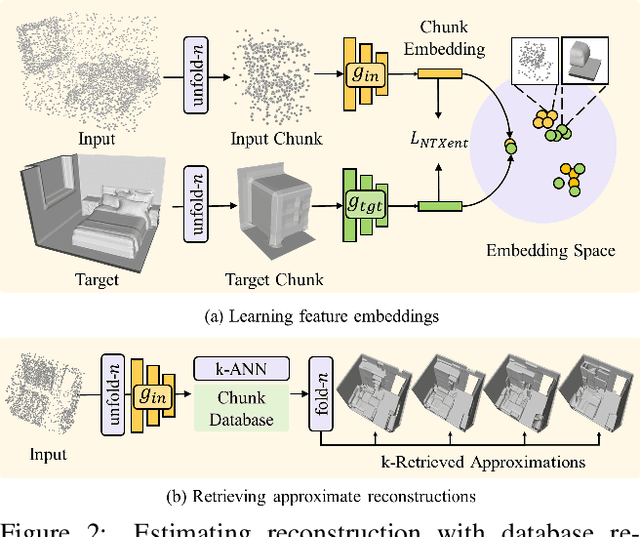
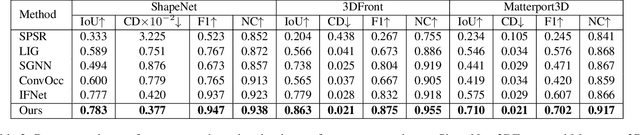
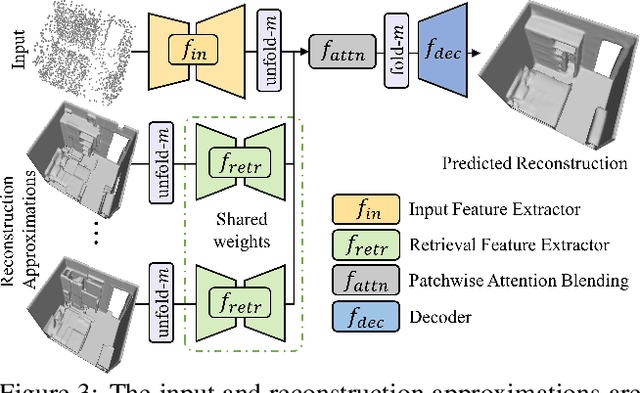
3D reconstruction of large scenes is a challenging problem due to the high-complexity nature of the solution space, in particular for generative neural networks. In contrast to traditional generative learned models which encode the full generative process into a neural network and can struggle with maintaining local details at the scene level, we introduce a new method that directly leverages scene geometry from the training database. First, we learn to synthesize an initial estimate for a 3D scene, constructed by retrieving a top-k set of volumetric chunks from the scene database. These candidates are then refined to a final scene generation with an attention-based refinement that can effectively select the most consistent set of geometry from the candidates and combine them together to create an output scene, facilitating transfer of coherent structures and local detail from train scene geometry. We demonstrate our neural scene reconstruction with a database for the tasks of 3D super resolution and surface reconstruction from sparse point clouds, showing that our approach enables generation of more coherent, accurate 3D scenes, improving on average by over 8% in IoU over state-of-the-art scene reconstruction.