 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosed-Form Diffusion Models
Oct 19, 2023



Score-based generative models (SGMs) sample from a target distribution by iteratively transforming noise using the score function of the perturbed target. For any finite training set, this score function can be evaluated in closed form, but the resulting SGM memorizes its training data and does not generate novel samples. In practice, one approximates the score by training a neural network via score-matching. The error in this approximation promotes generalization, but neural SGMs are costly to train and sample, and the effective regularization this error provides is not well-understood theoretically. In this work, we instead explicitly smooth the closed-form score to obtain an SGM that generates novel samples without training. We analyze our model and propose an efficient nearest-neighbor-based estimator of its score function. Using this estimator, our method achieves sampling times competitive with neural SGMs while running on consumer-grade CPUs.
GeRA: Label-Efficient Geometrically Regularized Alignment
Oct 07, 2023



Pretrained unimodal encoders incorporate rich semantic information into embedding space structures. To be similarly informative, multi-modal encoders typically require massive amounts of paired data for alignment and training. We introduce a semi-supervised Geometrically Regularized Alignment (GeRA) method to align the embedding spaces of pretrained unimodal encoders in a label-efficient way. Our method leverages the manifold geometry of unpaired (unlabeled) data to improve alignment performance. To prevent distortions to local geometry during the alignment process, potentially disrupting semantic neighborhood structures and causing misalignment of unobserved pairs, we introduce a geometric loss term. This term is built upon a diffusion operator that captures the local manifold geometry of the unimodal pretrained encoders. GeRA is modality-agnostic and thus can be used to align pretrained encoders from any data modalities. We provide empirical evidence to the effectiveness of our method in the domains of speech-text and image-text alignment. Our experiments demonstrate significant improvement in alignment quality compared to a variaty of leading baselines, especially with a small amount of paired data, using our proposed geometric regularization.
Variational Barycentric Coordinates
Oct 05, 2023



We propose a variational technique to optimize for generalized barycentric coordinates that offers additional control compared to existing models. Prior work represents barycentric coordinates using meshes or closed-form formulae, in practice limiting the choice of objective function. In contrast, we directly parameterize the continuous function that maps any coordinate in a polytope's interior to its barycentric coordinates using a neural field. This formulation is enabled by our theoretical characterization of barycentric coordinates, which allows us to construct neural fields that parameterize the entire function class of valid coordinates. We demonstrate the flexibility of our model using a variety of objective functions, including multiple smoothness and deformation-aware energies; as a side contribution, we also present mathematically-justified means of measuring and minimizing objectives like total variation on discontinuous neural fields. We offer a practical acceleration strategy, present a thorough validation of our algorithm, and demonstrate several applications.
Large Language Model Routing with Benchmark Datasets
Sep 27, 2023



There is a rapidly growing number of open-source Large Language Models (LLMs) and benchmark datasets to compare them. While some models dominate these benchmarks, no single model typically achieves the best accuracy in all tasks and use cases. In this work, we address the challenge of selecting the best LLM out of a collection of models for new tasks. We propose a new formulation for the problem, in which benchmark datasets are repurposed to learn a "router" model for this LLM selection, and we show that this problem can be reduced to a collection of binary classification tasks. We demonstrate the utility and limitations of learning model routers from various benchmark datasets, where we consistently improve performance upon using any single model for all tasks.
Data-Free Learning of Reduced-Order Kinematics
May 05, 2023Physical systems ranging from elastic bodies to kinematic linkages are defined on high-dimensional configuration spaces, yet their typical low-energy configurations are concentrated on much lower-dimensional subspaces. This work addresses the challenge of identifying such subspaces automatically: given as input an energy function for a high-dimensional system, we produce a low-dimensional map whose image parameterizes a diverse yet low-energy submanifold of configurations. The only additional input needed is a single seed configuration for the system to initialize our procedure; no dataset of trajectories is required. We represent subspaces as neural networks that map a low-dimensional latent vector to the full configuration space, and propose a training scheme to fit network parameters to any system of interest. This formulation is effective across a very general range of physical systems; our experiments demonstrate not only nonlinear and very low-dimensional elastic body and cloth subspaces, but also more general systems like colliding rigid bodies and linkages. We briefly explore applications built on this formulation, including manipulation, latent interpolation, and sampling.
Deep Augmentation: Enhancing Self-Supervised Learning through Transformations in Higher Activation Space
Mar 25, 2023



We introduce Deep Augmentation, an approach to data augmentation using dropout to dynamically transform a targeted layer within a neural network, with the option to use the stop-gradient operation, offering significant improvements in model performance and generalization. We demonstrate the efficacy of Deep Augmentation through extensive experiments on contrastive learning tasks in computer vision and NLP domains, where we observe substantial performance gains with ResNets and Transformers as the underlying models. Our experimentation reveals that targeting deeper layers with Deep Augmentation outperforms augmenting the input data, and the simple network- and data-agnostic nature of this approach enables its seamless integration into computer vision and NLP pipelines.
Self-Consistent Velocity Matching of Probability Flows
Jan 31, 2023We present a discretization-free scalable framework for solving a large class of mass-conserving partial differential equations (PDEs), including the time-dependent Fokker-Planck equation and the Wasserstein gradient flow. The main observation is that the time-varying velocity field of the PDE solution needs to be self-consistent: it must satisfy a fixed-point equation involving the flow characterized by the same velocity field. By parameterizing the flow as a time-dependent neural network, we propose an end-to-end iterative optimization framework called self-consistent velocity matching to solve this class of PDEs. Compared to existing approaches, our method does not suffer from temporal or spatial discretization, covers a wide range of PDEs, and scales to high dimensions. Experimentally, our method recovers analytical solutions accurately when they are available and achieves comparable or better performance in high dimensions with less training time compared to recent large-scale JKO-based methods that are designed for solving a more restrictive family of PDEs.
Sampling with Mollified Interaction Energy Descent
Oct 24, 2022Sampling from a target measure whose density is only known up to a normalization constant is a fundamental problem in computational statistics and machine learning. In this paper, we present a new optimization-based method for sampling called mollified interaction energy descent (MIED). MIED minimizes a new class of energies on probability measures called mollified interaction energies (MIEs). These energies rely on mollifier functions -- smooth approximations of the Dirac delta originated from PDE theory. We show that as the mollifier approaches the Dirac delta, the MIE converges to the chi-square divergence with respect to the target measure and the gradient flow of the MIE agrees with that of the chi-square divergence. Optimizing this energy with proper discretization yields a practical first-order particle-based algorithm for sampling in both unconstrained and constrained domains. We show experimentally that for unconstrained sampling problems our algorithm performs on par with existing particle-based algorithms like SVGD, while for constrained sampling problems our method readily incorporates constrained optimization techniques to handle more flexible constraints with strong performance compared to alternatives.
Outlier-Robust Group Inference via Gradient Space Clustering
Oct 13, 2022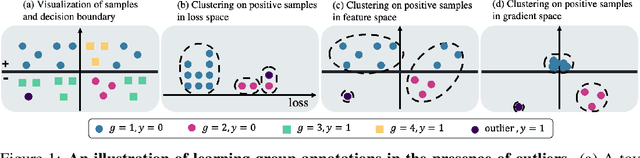
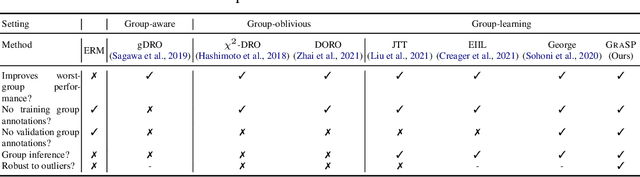

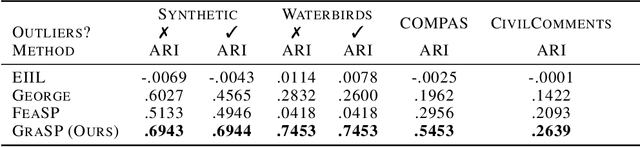
Traditional machine learning models focus on achieving good performance on the overall training distribution, but they often underperform on minority groups. Existing methods can improve the worst-group performance, but they can have several limitations: (i) they require group annotations, which are often expensive and sometimes infeasible to obtain, and/or (ii) they are sensitive to outliers. Most related works fail to solve these two issues simultaneously as they focus on conflicting perspectives of minority groups and outliers. We address the problem of learning group annotations in the presence of outliers by clustering the data in the space of gradients of the model parameters. We show that data in the gradient space has a simpler structure while preserving information about minority groups and outliers, making it suitable for standard clustering methods like DBSCAN. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art both in terms of group identification and downstream worst-group performance.
Riemannian Metric Learning via Optimal Transport
May 18, 2022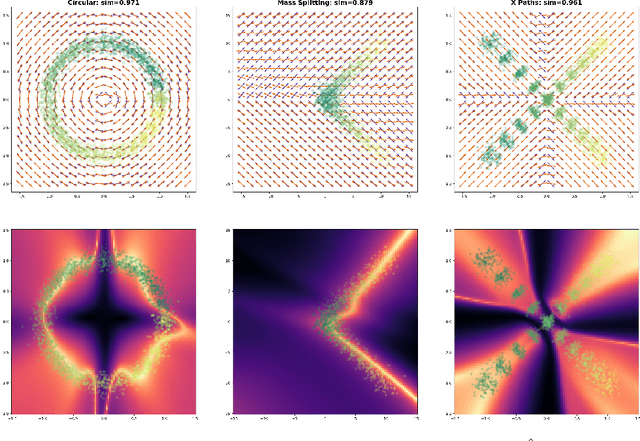
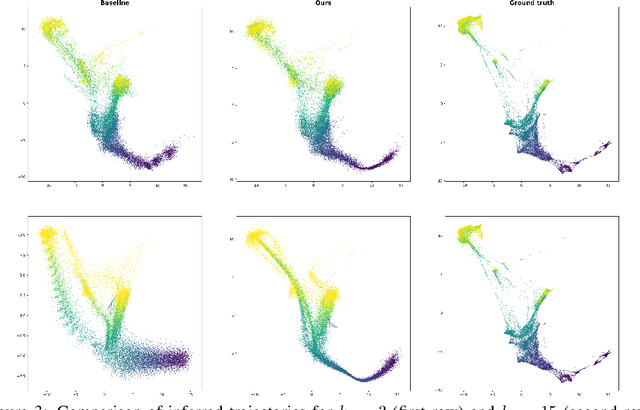
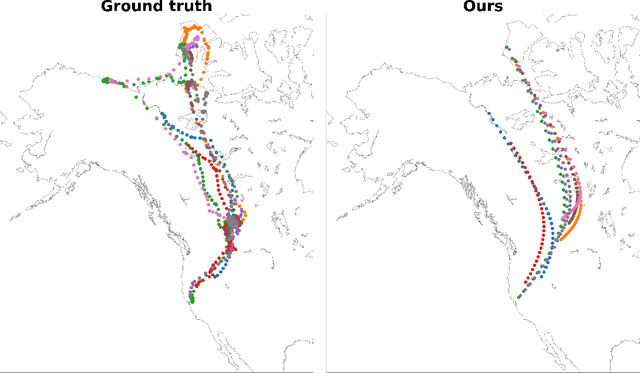
We introduce an optimal transport-based model for learning a metric tensor from cross-sectional samples of evolving probability measures on a common Riemannian manifold. We neurally parametrize the metric as a spatially-varying matrix field and efficiently optimize our model's objective using backpropagation. Using this learned metric, we can nonlinearly interpolate between probability measures and compute geodesics on the manifold. We show that metrics learned using our method improve the quality of trajectory inference on scRNA and bird migration data at the cost of little additional cross-sectional data.