 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognizing Scenes from Novel Viewpoints
Dec 02, 2021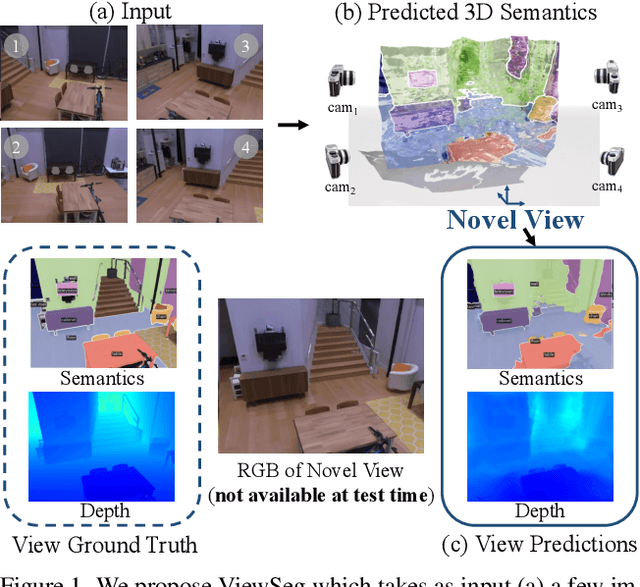

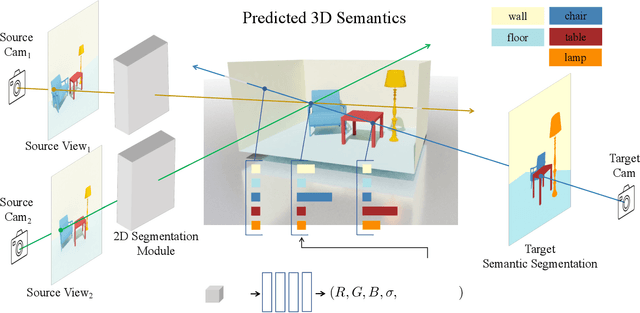

Humans can perceive scenes in 3D from a handful of 2D views. For AI agents, the ability to recognize a scene from any viewpoint given only a few images enables them to efficiently interact with the scene and its objects. In this work, we attempt to endow machines with this ability. We propose a model which takes as input a few RGB images of a new scene and recognizes the scene from novel viewpoints by segmenting it into semantic categories. All this without access to the RGB images from those views. We pair 2D scene recognition with an implicit 3D representation and learn from multi-view 2D annotations of hundreds of scenes without any 3D supervision beyond camera poses. We experiment on challenging datasets and demonstrate our model's ability to jointly capture semantics and geometry of novel scenes with diverse layouts, object types and shapes.
RedCaps: web-curated image-text data created by the people, for the people
Nov 22, 2021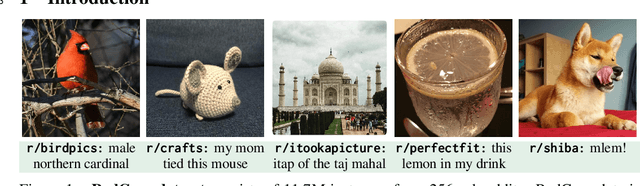


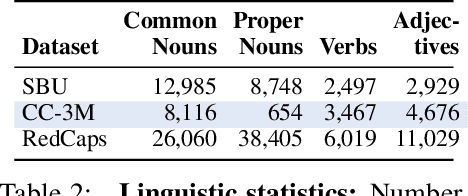
Large datasets of paired images and text have become increasingly popular for learning generic representations for vision and vision-and-language tasks. Such datasets have been built by querying search engines or collecting HTML alt-text -- since web data is noisy, they require complex filtering pipelines to maintain quality. We explore alternate data sources to collect high quality data with minimal filtering. We introduce RedCaps -- a large-scale dataset of 12M image-text pairs collected from Reddit. Images and captions from Reddit depict and describe a wide variety of objects and scenes. We collect data from a manually curated set of subreddits, which give coarse image labels and allow us to steer the dataset composition without labeling individual instances. We show that captioning models trained on RedCaps produce rich and varied captions preferred by humans, and learn visual representations that transfer to many downstream tasks.
PixelSynth: Generating a 3D-Consistent Experience from a Single Image
Aug 12, 2021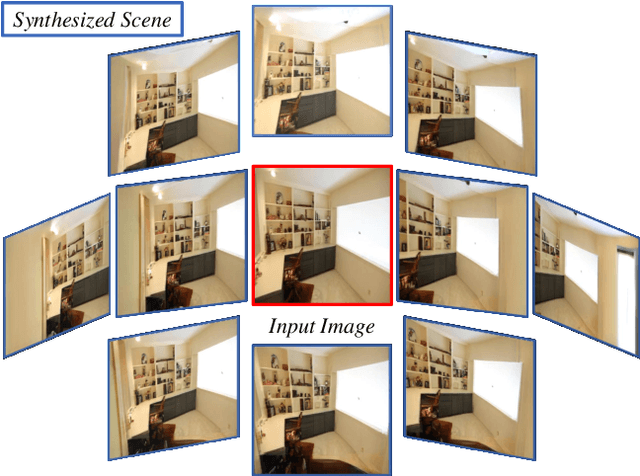
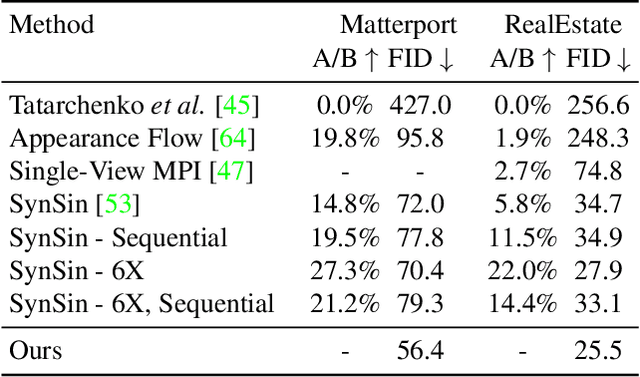


Recent advancements in differentiable rendering and 3D reasoning have driven exciting results in novel view synthesis from a single image. Despite realistic results, methods are limited to relatively small view change. In order to synthesize immersive scenes, models must also be able to extrapolate. We present an approach that fuses 3D reasoning with autoregressive modeling to outpaint large view changes in a 3D-consistent manner, enabling scene synthesis. We demonstrate considerable improvement in single image large-angle view synthesis results compared to a variety of methods and possible variants across simulated and real datasets. In addition, we show increased 3D consistency compared to alternative accumulation methods. Project website: https://crockwell.github.io/pixelsynth/
Inverting and Understanding Object Detectors
Jun 26, 2021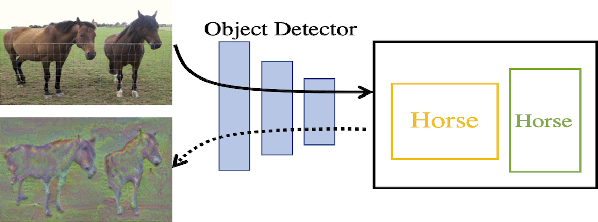
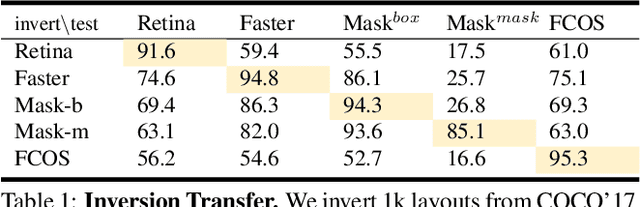
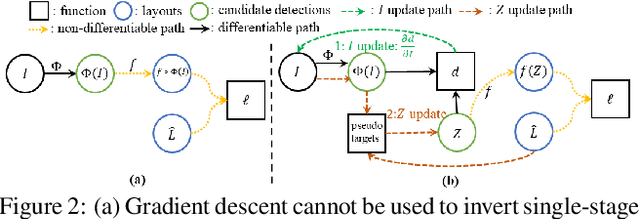
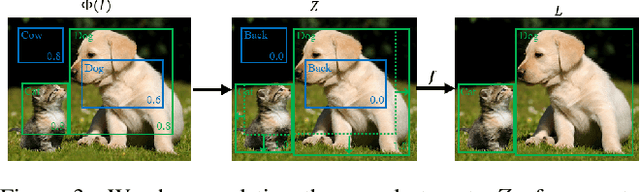
As a core problem in computer vision, the performance of object detection has improved drastically in the past few years. Despite their impressive performance, object detectors suffer from a lack of interpretability. Visualization techniques have been developed and widely applied to introspect the decisions made by other kinds of deep learning models; however, visualizing object detectors has been underexplored. In this paper, we propose using inversion as a primary tool to understand modern object detectors and develop an optimization-based approach to layout inversion, allowing us to generate synthetic images recognized by trained detectors as containing a desired configuration of objects. We reveal intriguing properties of detectors by applying our layout inversion technique to a variety of modern object detectors, and further investigate them via validation experiments: they rely on qualitatively different features for classification and regression; they learn canonical motifs of commonly co-occurring objects; they use diff erent visual cues to recognize objects of varying sizes. We hope our insights can help practitioners improve object detectors.
Bootstrap Your Own Correspondences
Jun 01, 2021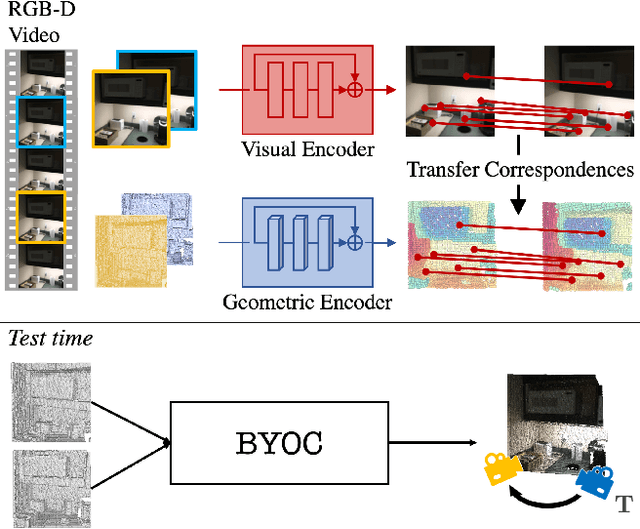
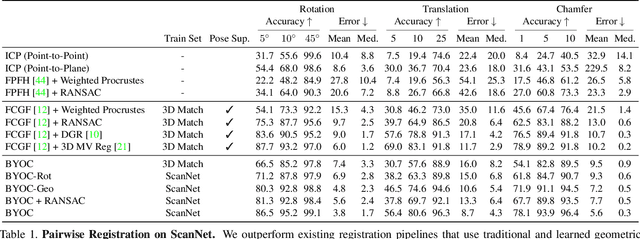
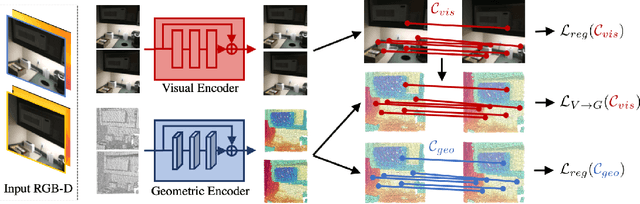
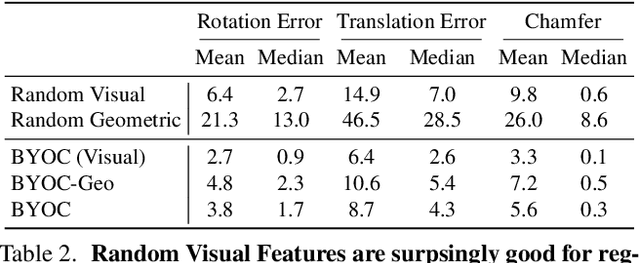
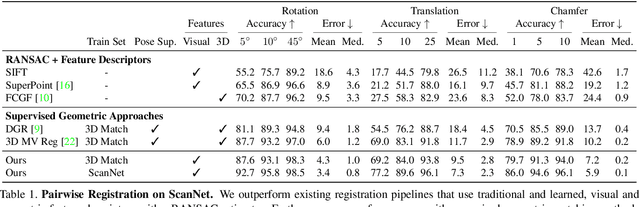
Geometric feature extraction is a crucial component of point cloud registration pipelines. Recent work has demonstrated how supervised learning can be leveraged to learn better and more compact 3D features. However, those approaches' reliance on ground-truth annotation limits their scalability. We propose BYOC: a self-supervised approach that learns visual and geometric features from RGB-D video without relying on ground-truth pose or correspondence. Our key observation is that randomly-initialized CNNs readily provide us with good correspondences; allowing us to bootstrap the learning of both visual and geometric features. Our approach combines classic ideas from point cloud registration with more recent representation learning approaches. We evaluate our approach on indoor scene datasets and find that our method outperforms traditional and learned descriptors, while being competitive with current state-of-the-art supervised approaches.
Rethinking "Batch" in BatchNorm
May 17, 2021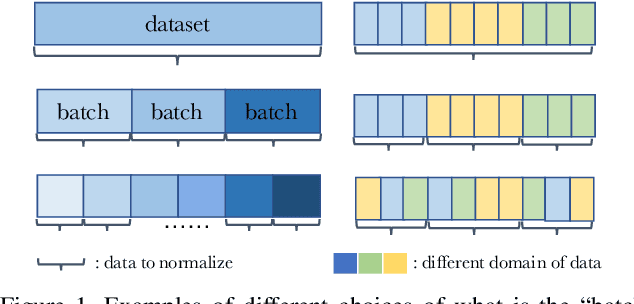
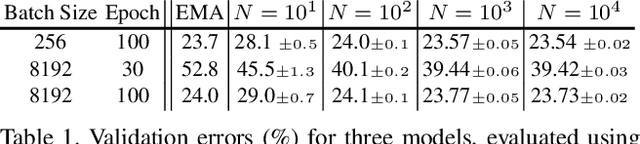
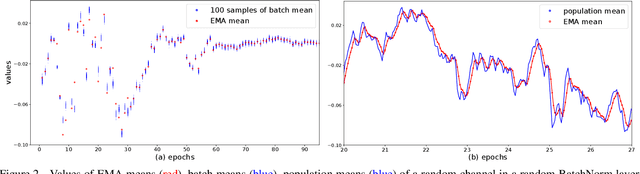
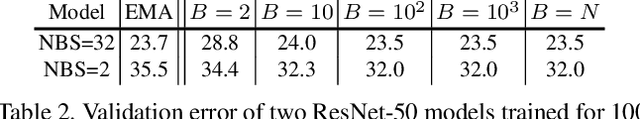
BatchNorm is a critical building block in modern convolutional neural networks. Its unique property of operating on "batches" instead of individual samples introduces significantly different behaviors from most other operations in deep learning. As a result, it leads to many hidden caveats that can negatively impact model's performance in subtle ways. This paper thoroughly reviews such problems in visual recognition tasks, and shows that a key to address them is to rethink different choices in the concept of "batch" in BatchNorm. By presenting these caveats and their mitigations, we hope this review can help researchers use BatchNorm more effectively.
UnsupervisedR&R: Unsupervised Point Cloud Registration via Differentiable Rendering
Feb 23, 2021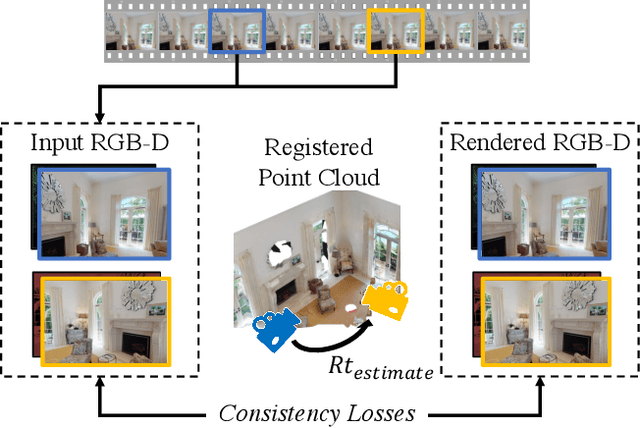
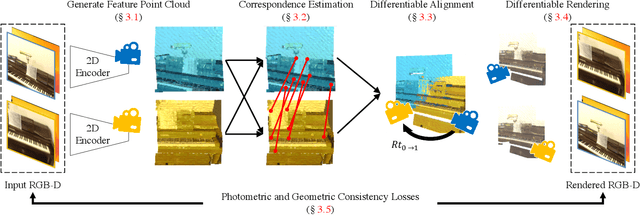
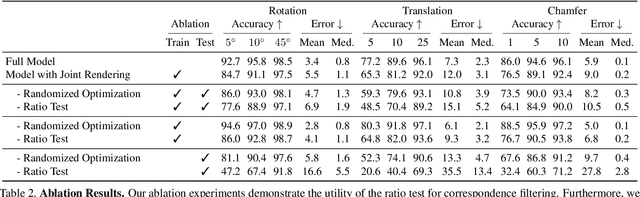
Aligning partial views of a scene into a single whole is essential to understanding one's environment and is a key component of numerous robotics tasks such as SLAM and SfM. Recent approaches have proposed end-to-end systems that can outperform traditional methods by leveraging pose supervision. However, with the rising prevalence of cameras with depth sensors, we can expect a new stream of raw RGB-D data without the annotations needed for supervision. We propose UnsupervisedR&R: an end-to-end unsupervised approach to learning point cloud registration from raw RGB-D video. The key idea is to leverage differentiable alignment and rendering to enforce photometric and geometric consistency between frames. We evaluate our approach on indoor scene datasets and find that we outperform existing traditional approaches with classic and learned descriptors while being competitive with supervised geometric point cloud registration approaches.
CASTing Your Model: Learning to Localize Improves Self-Supervised Representations
Dec 08, 2020

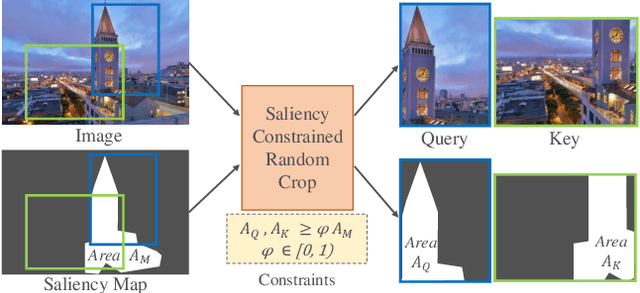
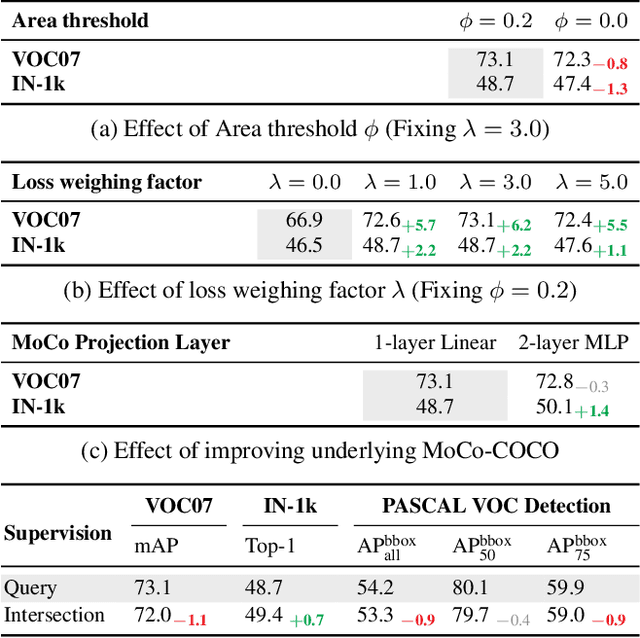
Recent advances in self-supervised learning (SSL) have largely closed the gap with supervised ImageNet pretraining. Despite their success these methods have been primarily applied to unlabeled ImageNet images, and show marginal gains when trained on larger sets of uncurated images. We hypothesize that current SSL methods perform best on iconic images, and struggle on complex scene images with many objects. Analyzing contrastive SSL methods shows that they have poor visual grounding and receive poor supervisory signal when trained on scene images. We propose Contrastive Attention-Supervised Tuning(CAST) to overcome these limitations. CAST uses unsupervised saliency maps to intelligently sample crops, and to provide grounding supervision via a Grad-CAM attention loss. Experiments on COCO show that CAST significantly improves the features learned by SSL methods on scene images, and further experiments show that CAST-trained models are more robust to changes in backgrounds.
Accelerating 3D Deep Learning with PyTorch3D
Jul 16, 2020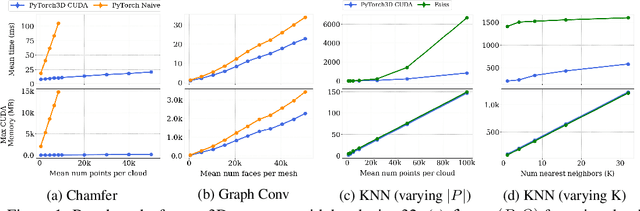
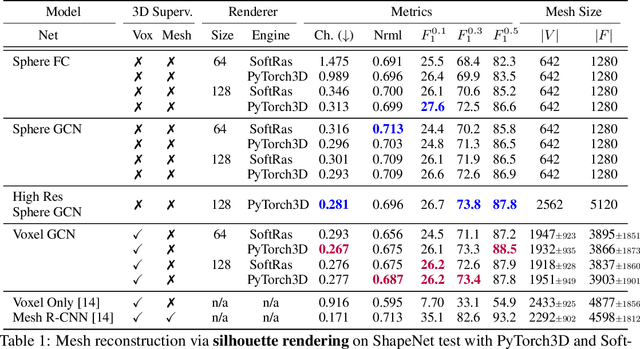
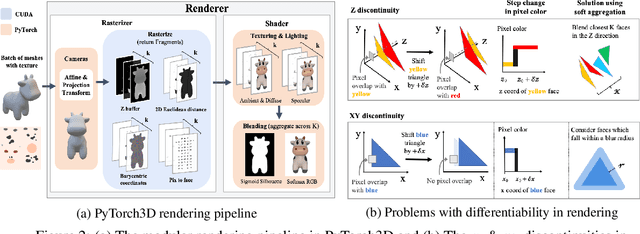
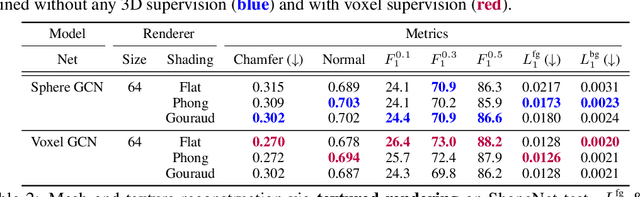
Deep learning has significantly improved 2D image recognition. Extending into 3D may advance many new applications including autonomous vehicles, virtual and augmented reality, authoring 3D content, and even improving 2D recognition. However despite growing interest, 3D deep learning remains relatively underexplored. We believe that some of this disparity is due to the engineering challenges involved in 3D deep learning, such as efficiently processing heterogeneous data and reframing graphics operations to be differentiable. We address these challenges by introducing PyTorch3D, a library of modular, efficient, and differentiable operators for 3D deep learning. It includes a fast, modular differentiable renderer for meshes and point clouds, enabling analysis-by-synthesis approaches. Compared with other differentiable renderers, PyTorch3D is more modular and efficient, allowing users to more easily extend it while also gracefully scaling to large meshes and images. We compare the PyTorch3D operators and renderer with other implementations and demonstrate significant speed and memory improvements. We also use PyTorch3D to improve the state-of-the-art for unsupervised 3D mesh and point cloud prediction from 2D images on ShapeNet. PyTorch3D is open-source and we hope it will help accelerate research in 3D deep learning.
VirTex: Learning Visual Representations from Textual Annotations
Jun 11, 2020
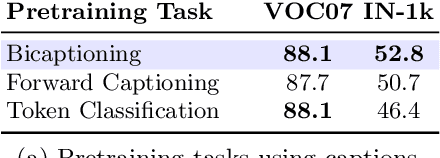
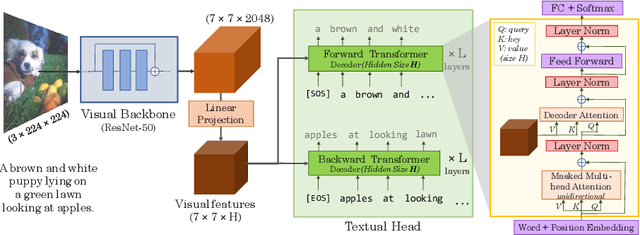

The de-facto approach to many vision tasks is to start from pretrained visual representations, typically learned via supervised training on ImageNet. Recent methods have explored unsupervised pretraining to scale to vast quantities of unlabeled images. In contrast, we aim to learn high-quality visual representations from fewer images. To this end, we revisit supervised pretraining, and seek data-efficient alternatives to classification-based pretraining. We propose VirTex -- a pretraining approach using semantically dense captions to learn visual representations. We train convolutional networks from scratch on COCO Captions, and transfer them to downstream recognition tasks including image classification, object detection, and instance segmentation. On all tasks, VirTex yields features that match or exceed those learned on ImageNet -- supervised or unsupervised -- despite using up to ten times fewer images.