 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances in Black-Box VI: Normalizing Flows, Importance Weighting, and Optimization
Jun 18, 2020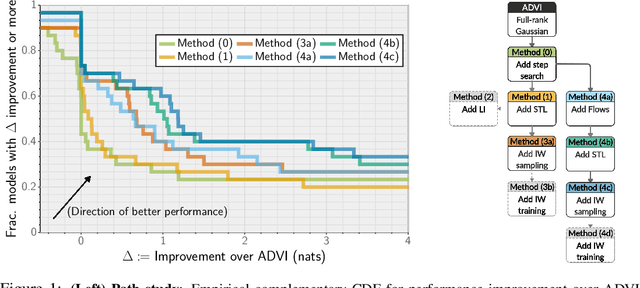
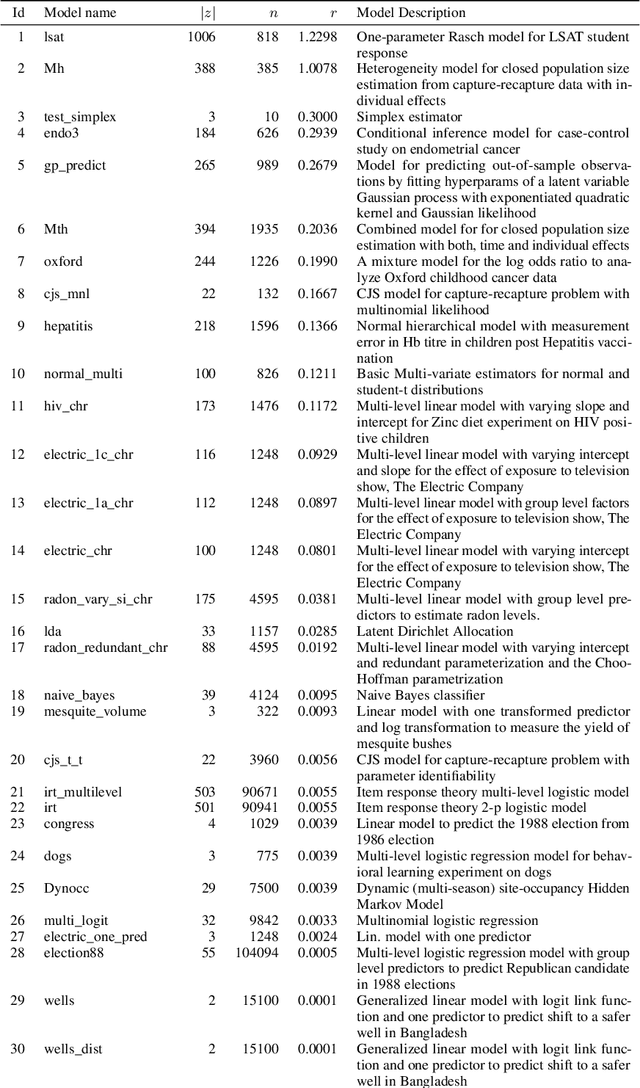
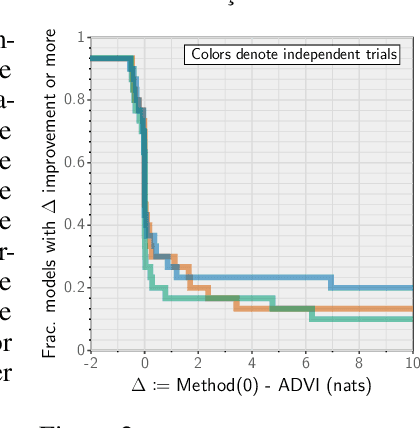
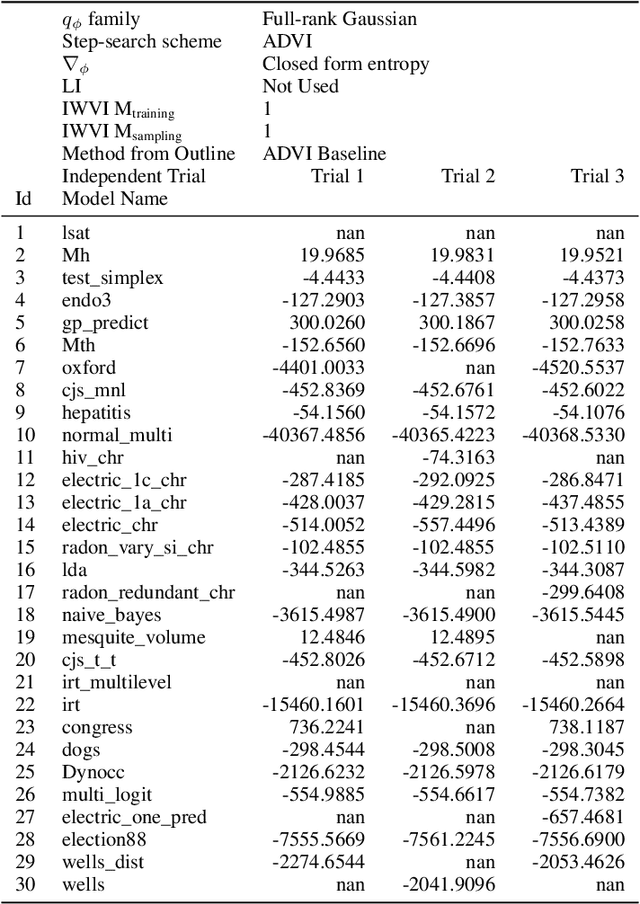
Recent research has seen several advances relevant to black-box VI, but the current state of automatic posterior inference is unclear. One such advance is the use of normalizing flows to define flexible posterior densities for deep latent variable models. Another direction is the integration of Monte-Carlo methods to serve two purposes; first, to obtain tighter variational objectives for optimization, and second, to define enriched variational families through sampling. However, both flows and variational Monte-Carlo methods remain relatively unexplored for black-box VI. Moreover, on a pragmatic front, there are several optimization considerations like step-size scheme, parameter initialization, and choice of gradient estimators, for which there are no clear guidance in the existing literature. In this paper, we postulate that black-box VI is best addressed through a careful combination of numerous algorithmic components. We evaluate components relating to optimization, flows, and Monte-Carlo methods on a benchmark of 30 models from the Stan model library. The combination of these algorithmic components significantly advances the state-of-the-art "out of the box" variational inference.
Moment-Matching Conditions for Exponential Families with Conditioning or Hidden Data
Jan 07, 2020
Maximum likelihood learning with exponential families leads to moment-matching of the sufficient statistics, a classic result. This can be generalized to conditional exponential families and/or when there are hidden data. This document gives a first-principles explanation of these generalized moment-matching conditions, along with a self-contained derivation.
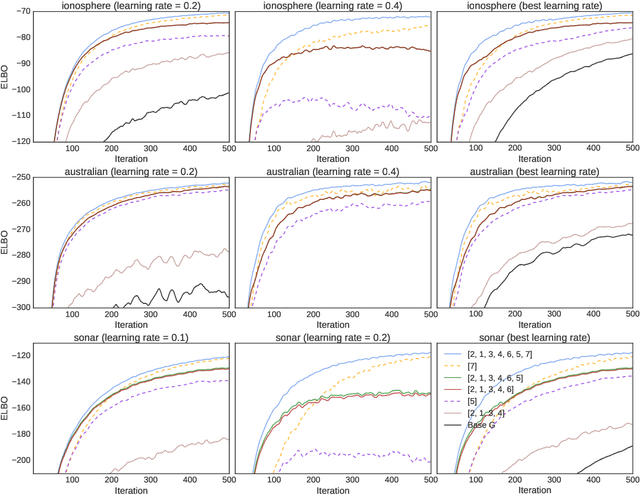
A Rule for Gradient Estimator Selection, with an Application to Variational Inference
Nov 05, 2019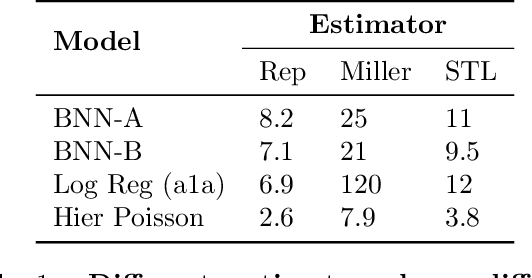
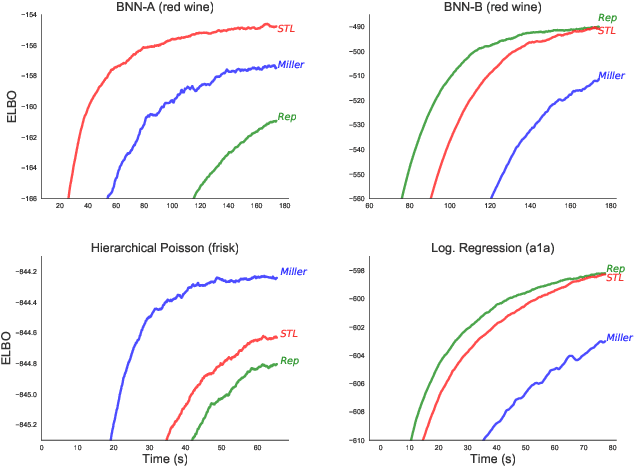

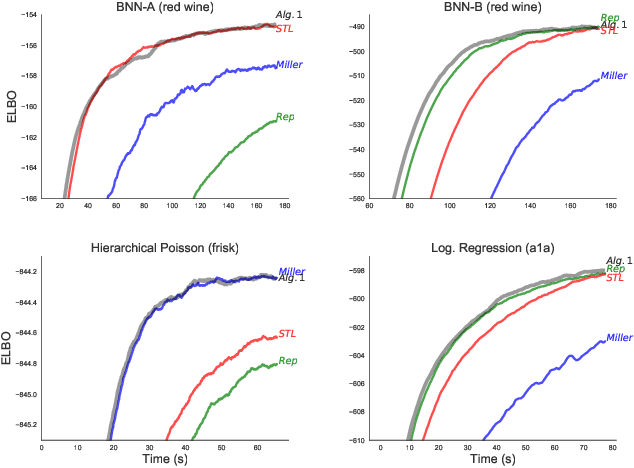
Stochastic gradient descent (SGD) is the workhorse of modern machine learning. Sometimes, there are many different potential gradient estimators that can be used. When so, choosing the one with the best tradeoff between cost and variance is important. This paper analyzes the convergence rates of SGD as a function of time, rather than iterations. This results in a simple rule to select the estimator that leads to the best optimization convergence guarantee. This choice is the same for different variants of SGD, and with different assumptions about the objective (e.g. convexity or smoothness). Inspired by this principle, we propose a technique to automatically select an estimator when a finite pool of estimators is given. Then, we extend to infinite pools of estimators, where each one is indexed by control variate weights. This is enabled by a reduction to a mixed-integer quadratic program. Empirically, automatically choosing an estimator performs comparably to the best estimator chosen with hindsight.
Thompson Sampling and Approximate Inference
Aug 14, 2019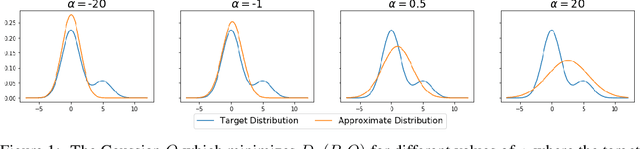
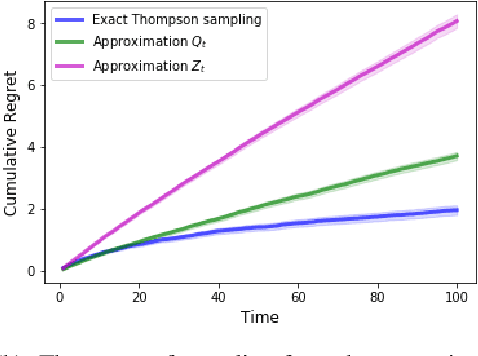
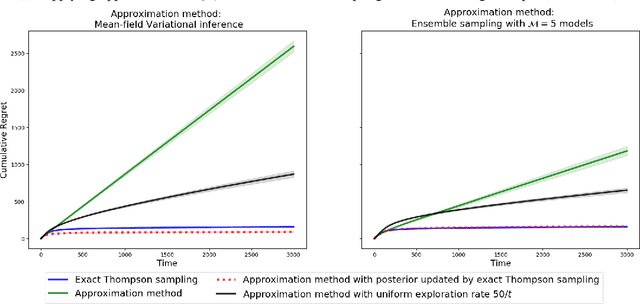
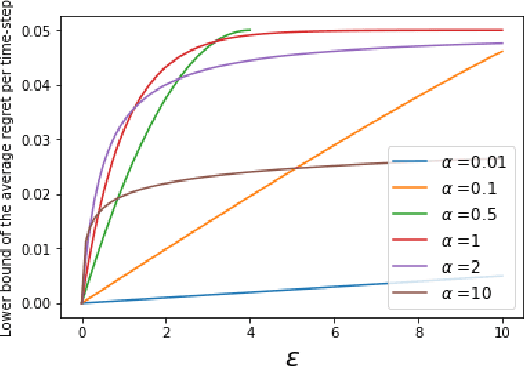
We study the effects of approximate inference on the performance of Thompson sampling in the $k$-armed bandit problems. Thompson sampling is a successful algorithm for online decision-making but requires posterior inference, which often must be approximated in practice. We show that even small constant inference error (in $\alpha$-divergence) can lead to poor performance (linear regret) due to under-exploration (for $\alpha<1$) or over-exploration (for $\alpha>0$) by the approximation. While for $\alpha > 0$ this is unavoidable, for $\alpha \leq 0$ the regret can be improved by adding a small amount of forced exploration even when the inference error is a large constant.
Divide and Couple: Using Monte Carlo Variational Objectives for Posterior Approximation
Jun 24, 2019



Recent work in variational inference (VI) uses ideas from Monte Carlo estimation to tighten the lower bounds on the log-likelihood that are used as objectives. However, there is no systematic understanding of how optimizing different objectives relates to approximating the posterior distribution. Developing such a connection is important if the ideas are to be applied to inference-i.e., applications that require an approximate posterior and not just an approximation of the log-likelihood. Given a VI objective defined by a Monte Carlo estimator of the likelihood, we use a "divide and couple" procedure to identify augmented proposal and target distributions. The divergence between these is equal to the gap between the VI objective and the log-likelihood. Thus, after maximizing the VI objective, the augmented variational distribution may be used to approximate the posterior distribution.
Provable Gradient Variance Guarantees for Black-Box Variational Inference
Jun 19, 2019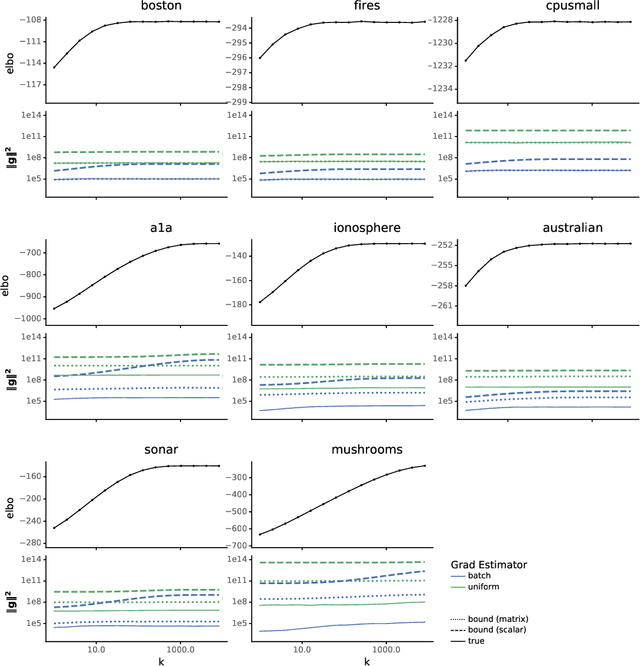
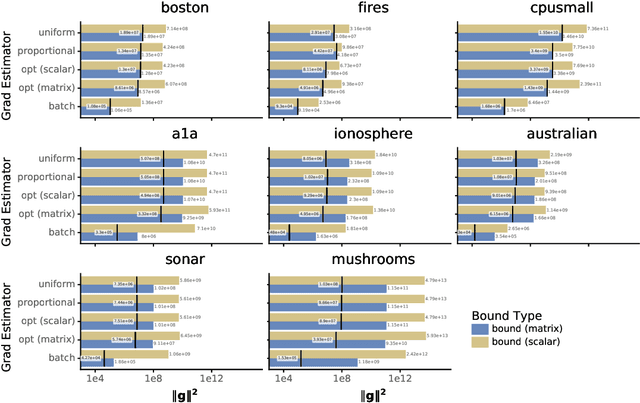
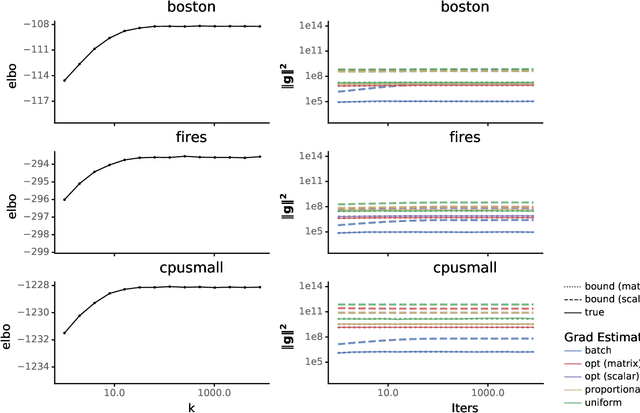
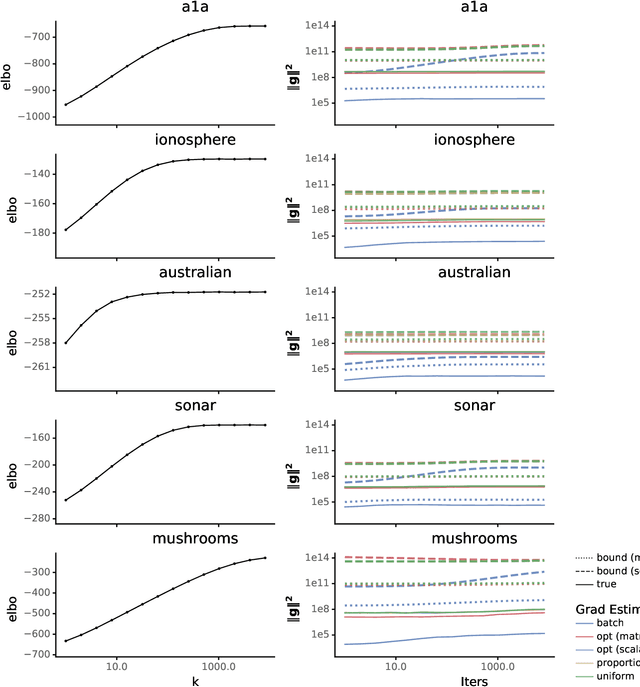
Recent variational inference methods use stochastic gradient estimators whose variance is not well understood. Theoretical guarantees for these estimators are important to understand when these methods will or will not work. This paper gives bounds for the common "reparameterization" estimators when the target is smooth and the variational family is a location-scale distribution. These bounds are unimprovable and thus provide the best possible guarantees under the stated assumptions.
Provable Smoothness Guarantees for Black-Box Variational Inference
Jan 24, 2019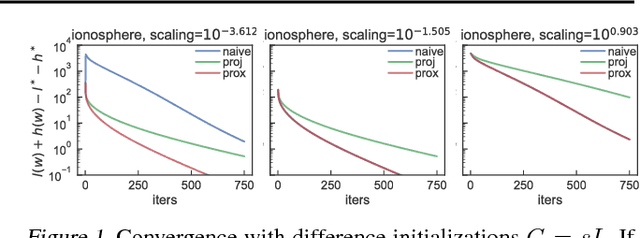

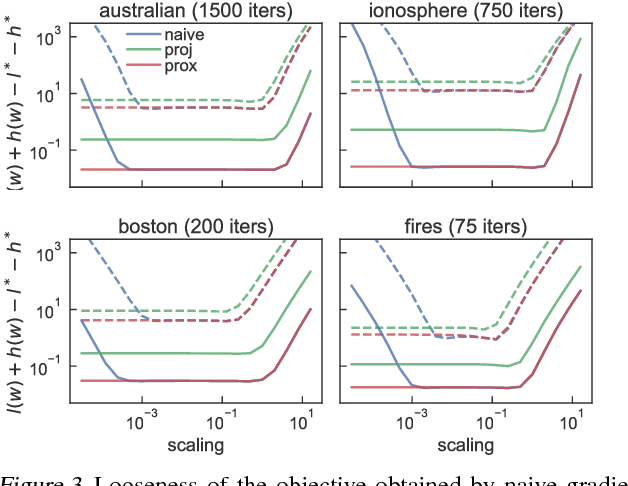
Black-box variational inference tries to approximate a complex target distribution though a gradient-based optimization of the parameters of a simpler distribution. Provable convergence guarantees require structural properties of the objective. This paper shows that for location-scale family approximations, if the target is M-Lipschitz smooth, then so is the objective, if the entropy is excluded. The key proof idea is to describe gradients in a certain inner-product space, thus permitting use of Bessel's inequality. This result gives insight into how to parameterize distributions, gives bounds the location of the optimal parameters, and is a key ingredient for convergence guarantees.
Using Large Ensembles of Control Variates for Variational Inference
Oct 30, 2018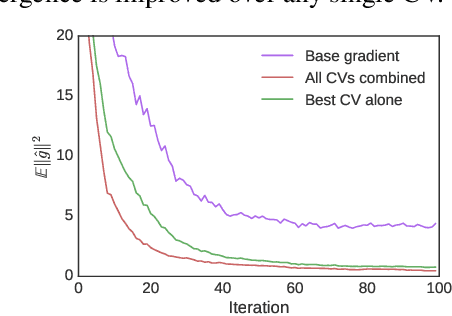


Variational inference is increasingly being addressed with stochastic optimization. In this setting, the gradient's variance plays a crucial role in the optimization procedure, since high variance gradients lead to poor convergence. A popular approach used to reduce gradient's variance involves the use of control variates. Despite the good results obtained, control variates developed for variational inference are typically looked at in isolation. In this paper we clarify the large number of control variates that are available by giving a systematic view of how they are derived. We also present a Bayesian risk minimization framework in which the quality of a procedure for combining control variates is quantified by its effect on optimization convergence rates, which leads to a very simple combination rule. Results show that combining a large number of control variates this way significantly improves the convergence of inference over using the typical gradient estimators or a reduced number of control variates.
Importance Weighting and Variational Inference
Oct 27, 2018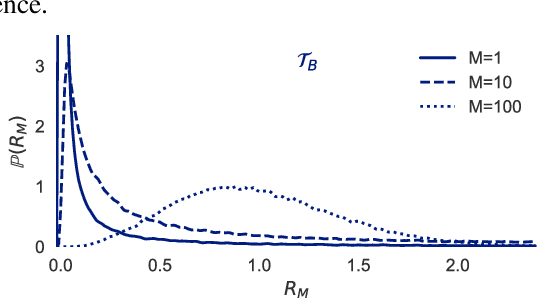
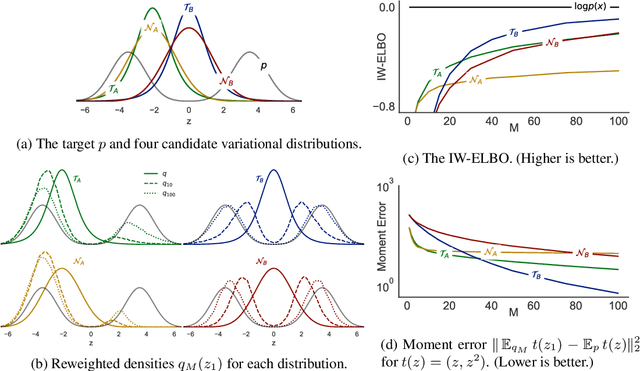
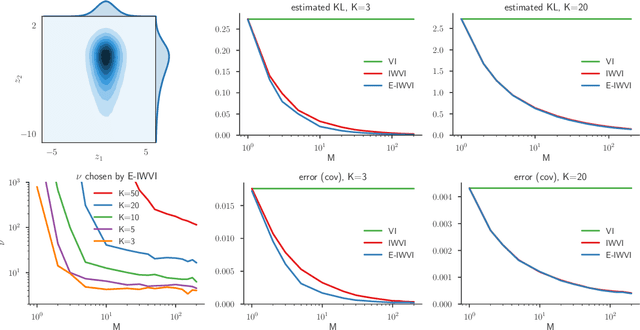
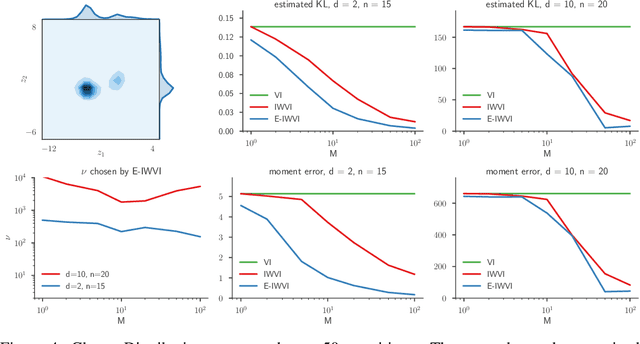
Recent work used importance sampling ideas for better variational bounds on likelihoods. We clarify the applicability of these ideas to pure probabilistic inference, by showing the resulting Importance Weighted Variational Inference (IWVI) technique is an instance of augmented variational inference, thus identifying the looseness in previous work. Experiments confirm IWVI's practicality for probabilistic inference. As a second contribution, we investigate inference with elliptical distributions, which improves accuracy in low dimensions, and convergence in high dimensions.
Conditional Inference in Pre-trained Variational Autoencoders via Cross-coding
Oct 03, 2018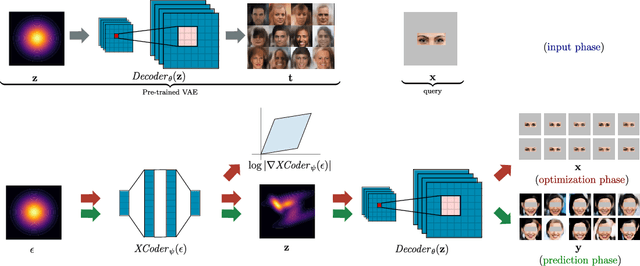



Variational Autoencoders (VAEs) are a popular generative model, but one in which conditional inference can be challenging. If the decomposition into query and evidence variables is fixed, conditional VAEs provide an attractive solution. To support arbitrary queries, one is generally reduced to Markov Chain Monte Carlo sampling methods that can suffer from long mixing times. In this paper, we propose an idea we term cross-coding to approximate the distribution over the latent variables after conditioning on an evidence assignment to some subset of the variables. This allows generating query samples without retraining the full VAE. We experimentally evaluate three variations of cross-coding showing that (i) they can be quickly optimized for different decompositions of evidence and query and (ii) they quantitatively and qualitatively outperform Hamiltonian Monte Carlo.