 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Dense Subgraph Discovery via Blurred-Graph Feedback
Jun 24, 2020



Dense subgraph discovery aims to find a dense component in edge-weighted graphs. This is a fundamental graph-mining task with a variety of applications and thus has received much attention recently. Although most existing methods assume that each individual edge weight is easily obtained, such an assumption is not necessarily valid in practice. In this paper, we introduce a novel learning problem for dense subgraph discovery in which a learner queries edge subsets rather than only single edges and observes a noisy sum of edge weights in a queried subset. For this problem, we first propose a polynomial-time algorithm that obtains a nearly-optimal solution with high probability. Moreover, to deal with large-sized graphs, we design a more scalable algorithm with a theoretical guarantee. Computational experiments using real-world graphs demonstrate the effectiveness of our algorithms.
Analysis and Design of Thompson Sampling for Stochastic Partial Monitoring
Jun 17, 2020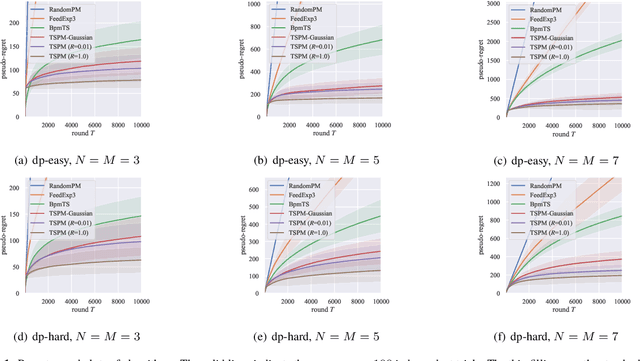

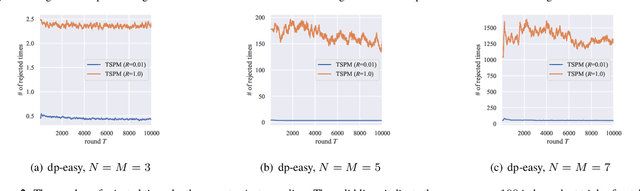
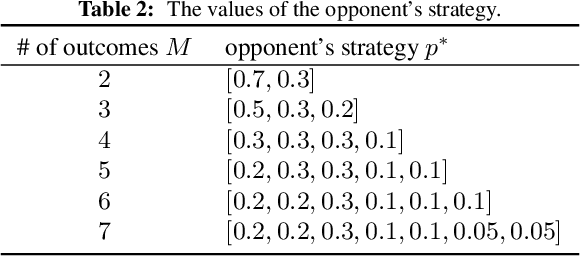
We investigate finite stochastic partial monitoring, which is a general model for sequential learning with limited feedback. While Thompson sampling is one of the most promising algorithms on a variety of online decision-making problems, its properties for stochastic partial monitoring have not been theoretically investigated, and the existing algorithm relies on a heuristic approximation of the posterior distribution. To mitigate these problems, we present a novel Thompson-sampling-based algorithm, which enables us to exactly sample the target parameter from the posterior distribution. Besides, we prove that the new algorithm achieves the logarithmic problem-dependent expected pseudo-regret $\mathrm{O}(\log T)$ for a linearized variant of the problem with local observability. This result is the first regret bound of Thompson sampling for partial monitoring, which also becomes the first logarithmic regret bound of Thompson sampling for linear bandits.
Time-varying Gaussian Process Bandit Optimization with Non-constant Evaluation Time
Mar 11, 2020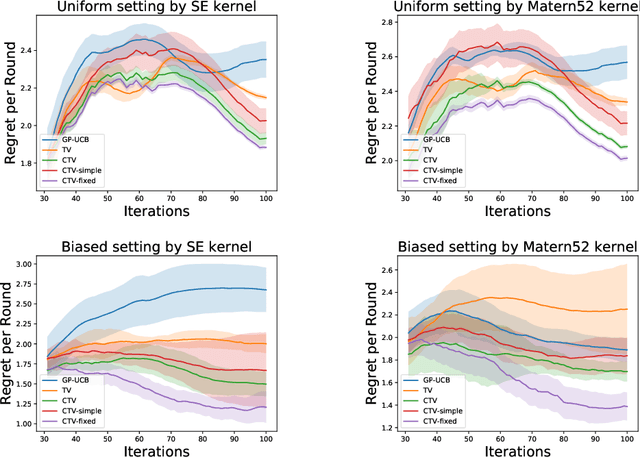
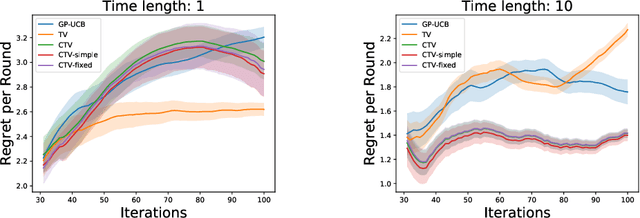
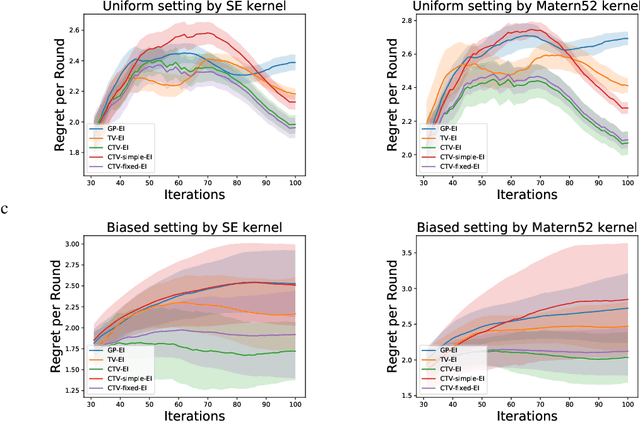
The Gaussian process bandit is a problem in which we want to find a maximizer of a black-box function with the minimum number of function evaluations. If the black-box function varies with time, then time-varying Bayesian optimization is a promising framework. However, a drawback with current methods is in the assumption that the evaluation time for every observation is constant, which can be unrealistic for many practical applications, e.g., recommender systems and environmental monitoring. As a result, the performance of current methods can be degraded when this assumption is violated. To cope with this problem, we propose a novel time-varying Bayesian optimization algorithm that can effectively handle the non-constant evaluation time. Furthermore, we theoretically establish a regret bound of our algorithm. Our bound elucidates that a pattern of the evaluation time sequence can hugely affect the difficulty of the problem. We also provide experimental results to validate the practical effectiveness of the proposed method.
Adaptive Experimental Design for Efficient Treatment Effect Estimation: Randomized Allocation via Contextual Bandit Algorithm
Feb 13, 2020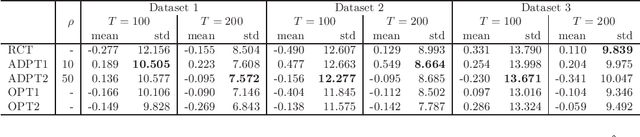
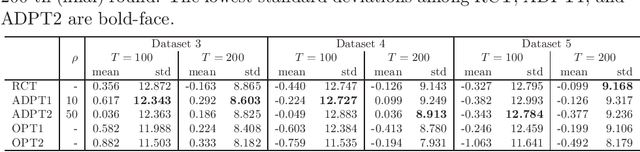


Many scientific experiments have an interest in the estimation of the average treatment effect (ATE), which is defined as the difference between the expected outcomes of two or more treatments. In this paper, we consider a situation called adaptive experimental design where research subjects sequentially visit a researcher, and the researcher assigns a treatment. For estimating the ATE efficiently, we consider changing the probability of assigning a treatment at a period by using past information obtained until the period. However, in this approach, it is difficult to apply the standard statistical method to construct an estimator because the observations are not independent and identically distributed. In this paper, to construct an efficient estimator, we overcome this conventional problem by using an algorithm of the multi-armed bandit problem and the theory of martingale. In the proposed method, we use the probability of assigning a treatment that minimizes the asymptotic variance of an estimator of the ATE. We also elucidate the theoretical properties of an estimator obtained from the proposed algorithm for both infinite and finite samples. Finally, we experimentally show that the proposed algorithm outperforms the standard RCT in some cases.
Uncoupled Regression from Pairwise Comparison Data
Jun 03, 2019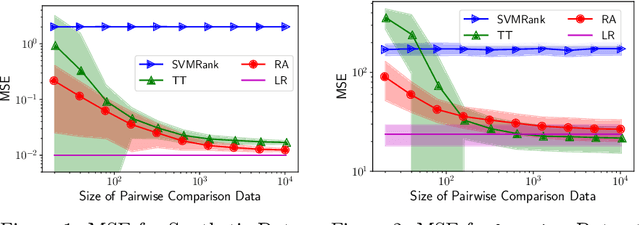
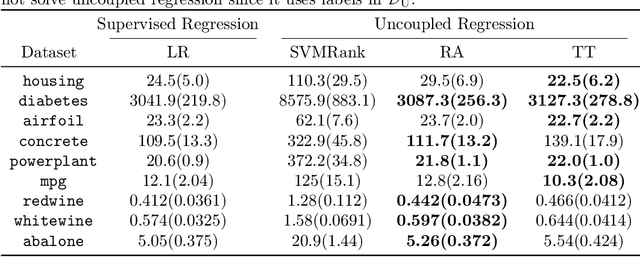
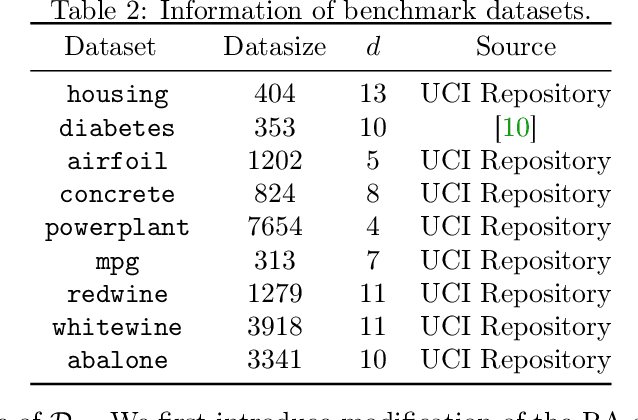
Uncoupled regression is the problem to learn a model from unlabeled data and the set of target values while the correspondence between them is unknown. Such a situation arises in predicting anonymized targets that involve sensitive information, e.g., one's annual income. Since existing methods for uncoupled regression often require strong assumptions on the true target function, and thus, their range of applications is limited, we introduce a novel framework that does not require such assumptions in this paper. Our key idea is to utilize pairwise comparison data, which consists of pairs of unlabeled data that we know which one has a larger target value. Such pairwise comparison data is easy to collect, as typically discussed in the learning-to-rank scenario, and does not break the anonymity of data. We propose two practical methods for uncoupled regression from pairwise comparison data and show that the learned regression model converges to the optimal model with the optimal parametric convergence rate when the target variable distributes uniformly. Moreover, we empirically show that for linear models the proposed methods are comparable to ordinary supervised regression with labeled data.
A Note on KL-UCB+ Policy for the Stochastic Bandit
Mar 20, 2019A classic setting of the stochastic K-armed bandit problem is considered in this note. In this problem it has been known that KL-UCB policy achieves the asymptotically optimal regret bound and KL-UCB+ policy empirically performs better than the KL-UCB policy although the regret bound for the original form of the KL-UCB+ policy has been unknown. This note demonstrates that a simple proof of the asymptotic optimality of the KL-UCB+ policy can be given by the same technique as those used for analyses of other known policies.
Polynomial-time Algorithms for Combinatorial Pure Exploration with Full-bandit Feedback
Feb 27, 2019
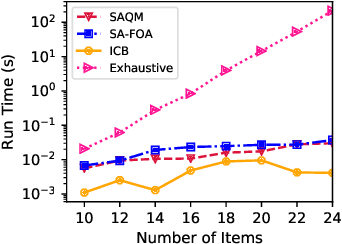
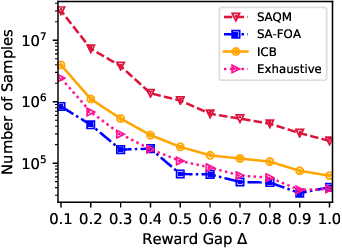
We study the problem of stochastic combinatorial pure exploration (CPE), where an agent sequentially pulls a set of single arms (a.k.a. a super arm) and tries to find the best super arm. Among a variety of problem settings of the CPE, we focus on the full-bandit setting, where we cannot observe the reward of each single arm, but only the sum of the rewards. Although we can regard the CPE with full-bandit feedback as a special case of pure exploration in linear bandits, an approach based on linear bandits is not computationally feasible since the number of super arms may be exponential. In this paper, we first propose a polynomial-time bandit algorithm for the CPE under general combinatorial constraints and provide an upper bound of the sample complexity. Second, we design an approximation algorithm for the 0-1 quadratic maximization problem, which arises in many bandit algorithms with confidence ellipsoids. Based on our approximation algorithm, we propose novel bandit algorithms for the top-k selection problem, and prove that our algorithms run in polynomial time. Finally, we conduct experiments on synthetic and real-world datasets, and confirm the validity of our theoretical analysis in terms of both the computation time and the sample complexity.
A Bad Arm Existence Checking Problem
Jan 31, 2019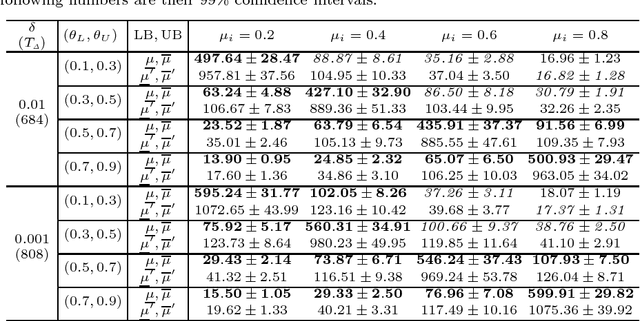
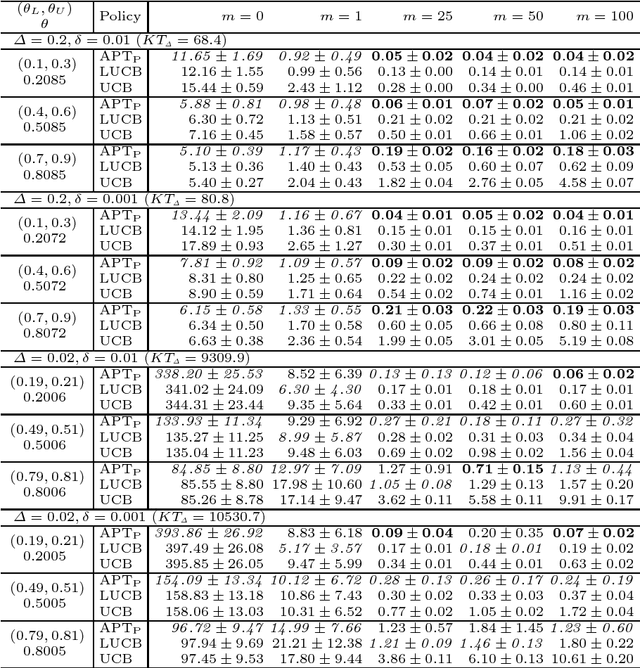

We study a bad arm existing checking problem in which a player's task is to judge whether a positive arm exists or not among given K arms by drawing as small number of arms as possible. Here, an arm is positive if its expected loss suffered by drawing the arm is at least a given threshold. This problem is a formalization of diagnosis of disease or machine failure. An interesting structure of this problem is the asymmetry of positive and negative (non-positive) arms' roles; finding one positive arm is enough to judge existence while all the arms must be discriminated as negative to judge non-existence. We propose an algorithms with arm selection policy (policy to determine the next arm to draw) and stopping condition (condition to stop drawing arms) utilizing this asymmetric problem structure and prove its effectiveness theoretically and empirically.
On Possibility and Impossibility of Multiclass Classification with Rejection
Jan 30, 2019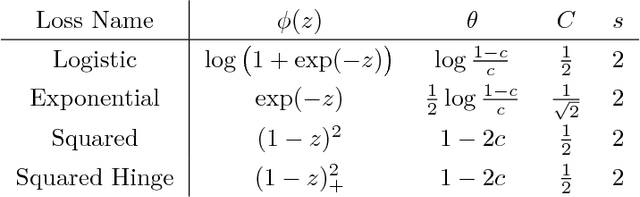
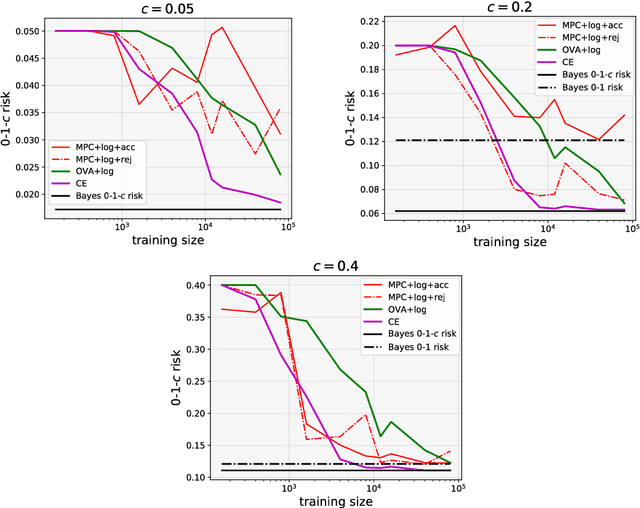

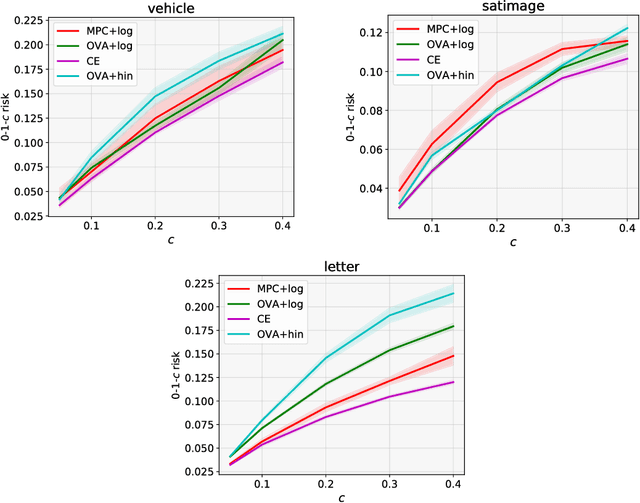
We investigate the problem of multiclass classification with rejection, where a classifier can choose not to make a prediction to avoid critical misclassification. We consider two approaches for this problem: a traditional one based on confidence scores and a more recent one based on simultaneous training of a classifier and a rejector. An existing method in the former approach focuses on a specific class of losses and its empirical performance is not very convincing. In this paper, we propose confidence-based rejection criteria for multiclass classification, which can handle more general losses and guarantee calibration to the Bayes-optimal solution. The latter approach is relatively new and has been available only for the binary case, to the best of our knowledge. Our second contribution is to prove that calibration to the Bayes-optimal solution is almost impossible by this approach in the multiclass case. Finally, we conduct experiments to validate the relevance of our theoretical findings.
Dueling Bandits with Qualitative Feedback
Sep 18, 2018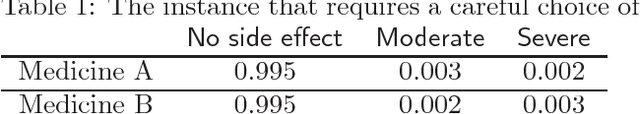
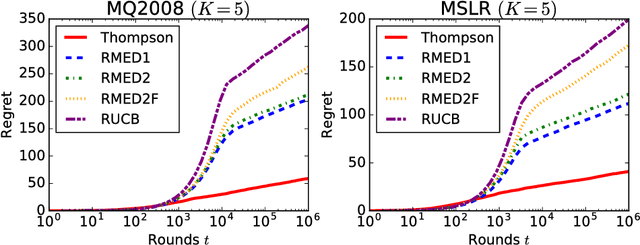
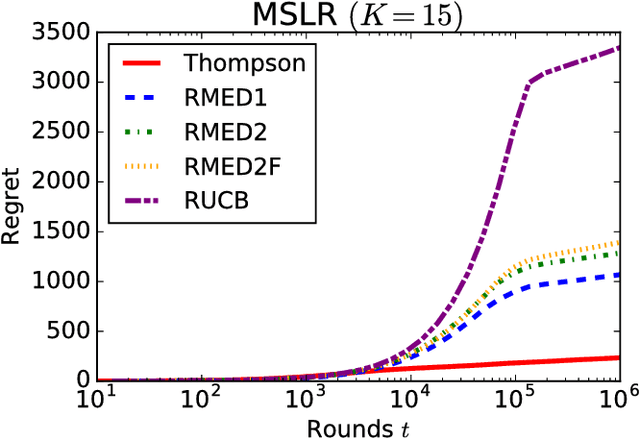
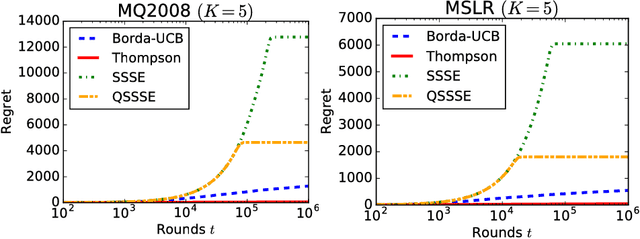
We formulate and study a novel multi-armed bandit problem called the qualitative dueling bandit (QDB) problem, where an agent observes not numeric but qualitative feedback by pulling each arm. We employ the same regret as the dueling bandit (DB) problem where the duel is carried out by comparing the qualitative feedback. Although we can naively use classic DB algorithms for solving the QDB problem, this reduction significantly worsens the performance---actually, in the QDB problem, the probability that one arm wins the duel over another arm can be directly estimated without carrying out actual duels. In this paper, we propose such direct algorithms for the QDB problem. Our theoretical analysis shows that the proposed algorithms significantly outperform DB algorithms by incorporating the qualitative feedback, and experimental results also demonstrate vast improvement over the existing DB algorithms.