 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Statistical Recurrent Unit
Mar 01, 2017
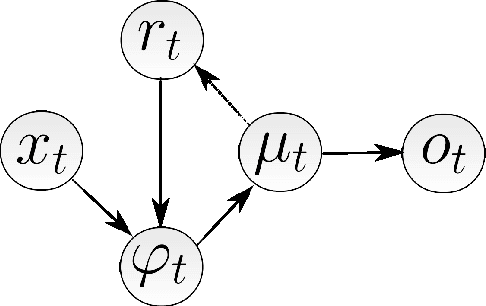
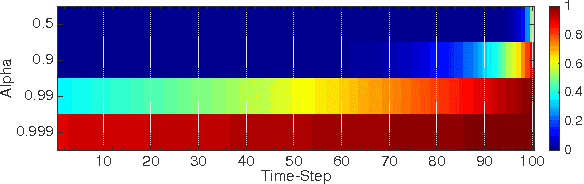

Sophisticated gated recurrent neural network architectures like LSTMs and GRUs have been shown to be highly effective in a myriad of applications. We develop an un-gated unit, the statistical recurrent unit (SRU), that is able to learn long term dependencies in data by only keeping moving averages of statistics. The SRU's architecture is simple, un-gated, and contains a comparable number of parameters to LSTMs; yet, SRUs perform favorably to more sophisticated LSTM and GRU alternatives, often outperforming one or both in various tasks. We show the efficacy of SRUs as compared to LSTMs and GRUs in an unbiased manner by optimizing respective architectures' hyperparameters in a Bayesian optimization scheme for both synthetic and real-world tasks.
Deep Mean Maps
Nov 13, 2015The use of distributions and high-level features from deep architecture has become commonplace in modern computer vision. Both of these methodologies have separately achieved a great deal of success in many computer vision tasks. However, there has been little work attempting to leverage the power of these to methodologies jointly. To this end, this paper presents the Deep Mean Maps (DMMs) framework, a novel family of methods to non-parametrically represent distributions of features in convolutional neural network models. DMMs are able to both classify images using the distribution of top-level features, and to tune the top-level features for performing this task. We show how to implement DMMs using a special mean map layer composed of typical CNN operations, making both forward and backward propagation simple. We illustrate the efficacy of DMMs at analyzing distributional patterns in image data in a synthetic data experiment. We also show that we extending existing deep architectures with DMMs improves the performance of existing CNNs on several challenging real-world datasets.
Linear-time Learning on Distributions with Approximate Kernel Embeddings
Sep 24, 2015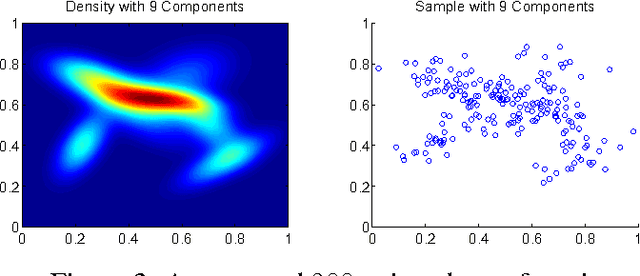
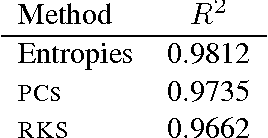
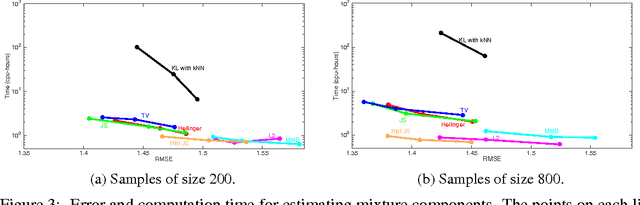
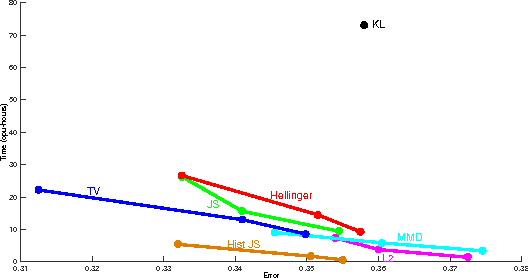
Many interesting machine learning problems are best posed by considering instances that are distributions, or sample sets drawn from distributions. Previous work devoted to machine learning tasks with distributional inputs has done so through pairwise kernel evaluations between pdfs (or sample sets). While such an approach is fine for smaller datasets, the computation of an $N \times N$ Gram matrix is prohibitive in large datasets. Recent scalable estimators that work over pdfs have done so only with kernels that use Euclidean metrics, like the $L_2$ distance. However, there are a myriad of other useful metrics available, such as total variation, Hellinger distance, and the Jensen-Shannon divergence. This work develops the first random features for pdfs whose dot product approximates kernels using these non-Euclidean metrics, allowing estimators using such kernels to scale to large datasets by working in a primal space, without computing large Gram matrices. We provide an analysis of the approximation error in using our proposed random features and show empirically the quality of our approximation both in estimating a Gram matrix and in solving learning tasks in real-world and synthetic data.
Fast Distribution To Real Regression
Mar 09, 2014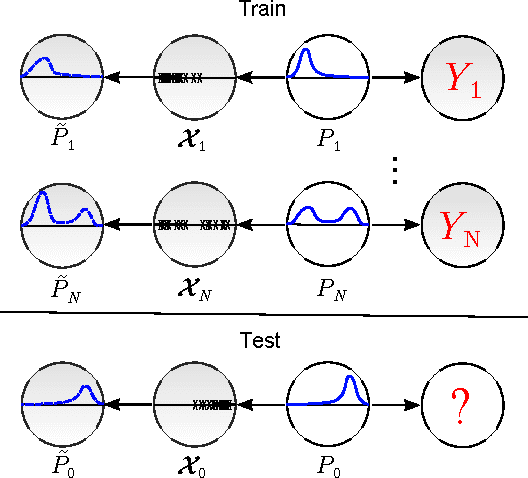
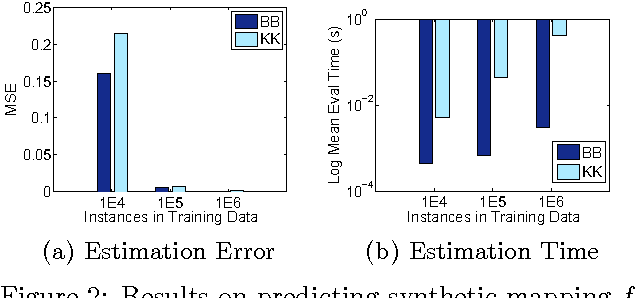
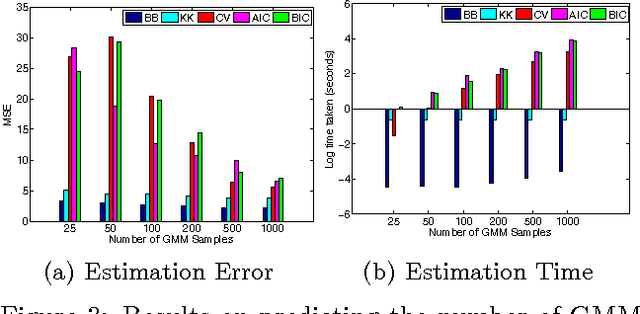
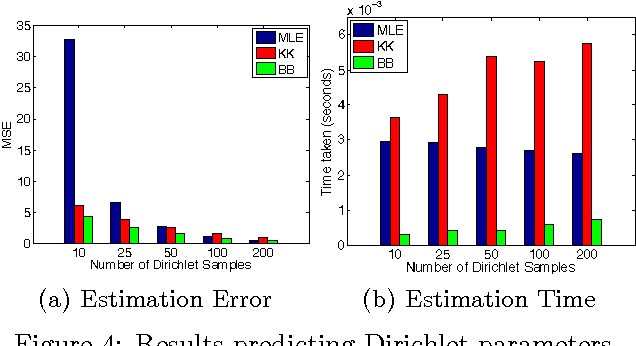
We study the problem of distribution to real-value regression, where one aims to regress a mapping $f$ that takes in a distribution input covariate $P\in \mathcal{I}$ (for a non-parametric family of distributions $\mathcal{I}$) and outputs a real-valued response $Y=f(P) + \epsilon$. This setting was recently studied, and a "Kernel-Kernel" estimator was introduced and shown to have a polynomial rate of convergence. However, evaluating a new prediction with the Kernel-Kernel estimator scales as $\Omega(N)$. This causes the difficult situation where a large amount of data may be necessary for a low estimation risk, but the computation cost of estimation becomes infeasible when the data-set is too large. To this end, we propose the Double-Basis estimator, which looks to alleviate this big data problem in two ways: first, the Double-Basis estimator is shown to have a computation complexity that is independent of the number of of instances $N$ when evaluating new predictions after training; secondly, the Double-Basis estimator is shown to have a fast rate of convergence for a general class of mappings $f\in\mathcal{F}$.
FuSSO: Functional Shrinkage and Selection Operator
Mar 09, 2014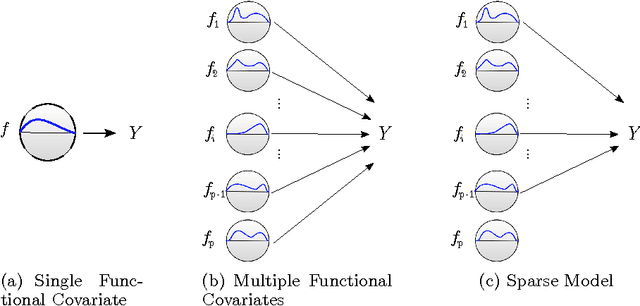
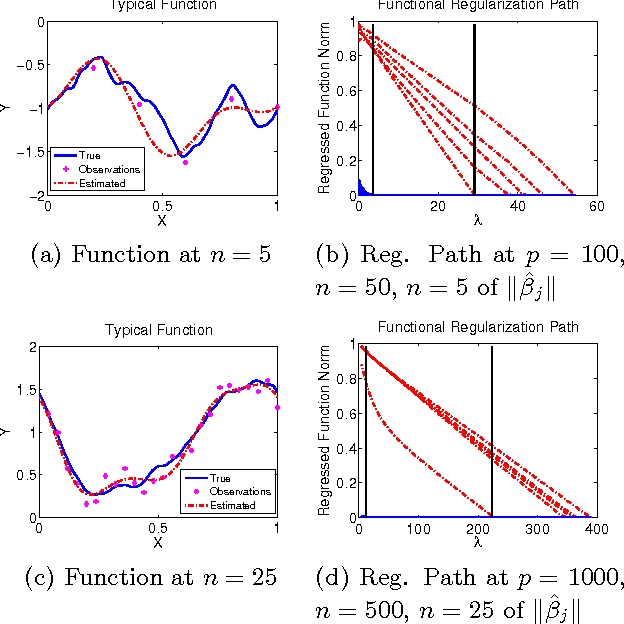
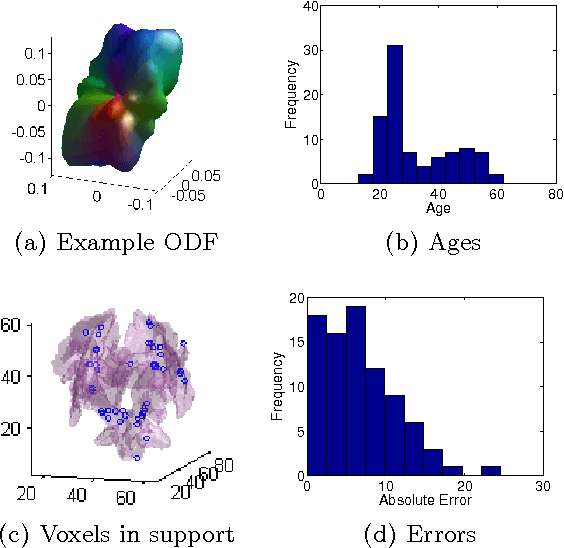
We present the FuSSO, a functional analogue to the LASSO, that efficiently finds a sparse set of functional input covariates to regress a real-valued response against. The FuSSO does so in a semi-parametric fashion, making no parametric assumptions about the nature of input functional covariates and assuming a linear form to the mapping of functional covariates to the response. We provide a statistical backing for use of the FuSSO via proof of asymptotic sparsistency under various conditions. Furthermore, we observe good results on both synthetic and real-world data.