 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn initial investigation on optimizing tandem speaker verification and countermeasure systems using reinforcement learning
Feb 06, 2020
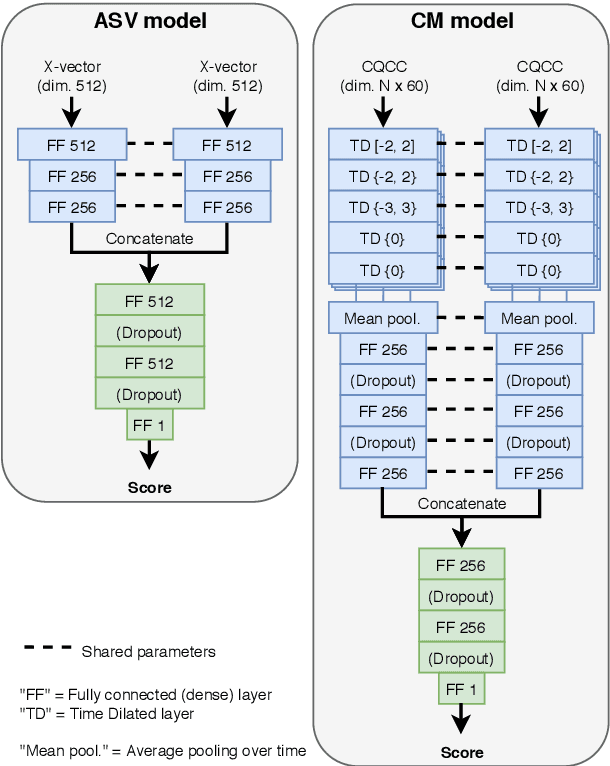

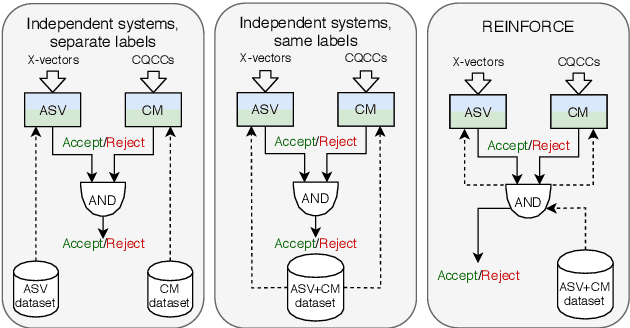
The spoofing countermeasure (CM) systems in automatic speaker verification (ASV) are not typically used in isolation of each other. These systems can be combined, for example, into a cascaded system where CM produces first a decision whether the input is synthetic or bona fide speech. In case the CM decides it is a bona fide sample, then the ASV system will consider it for speaker verification. End users of the system are not interested in the performance of the individual sub-modules, but instead are interested in the performance of the combined system. Such combination can be evaluated with tandem detection cost function (t-DCF) measure, yet the individual components are trained separately from each other using their own performance metrics. In this work we study training the ASV and CM components together for a better t-DCF measure by using reinforcement learning. We demonstrate that such training procedure indeed is able to improve the performance of the combined system, and does so with more reliable results than with the standard supervised learning techniques we compare against.
Detecting and Correcting Adversarial Images Using Image Processing Operations
Dec 30, 2019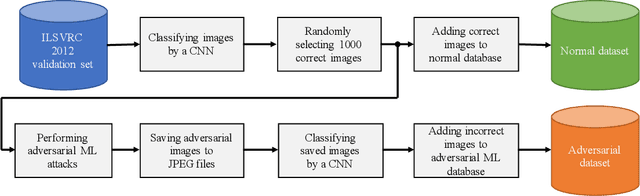

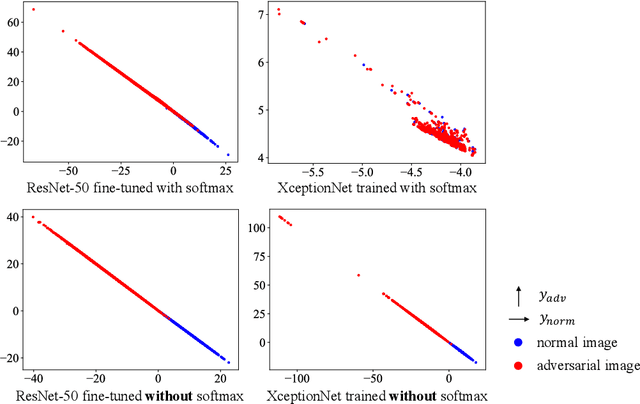
Deep neural networks (DNNs) have achieved excellent performance on several tasks and have been widely applied in both academia and industry. However, DNNs are vulnerable to adversarial machine learning attacks, in which noise is added to the input to change the network output. We have devised an image-processing-based method to detect adversarial images based on our observation that adversarial noise is reduced after applying these operations while the normal images almost remain unaffected. In addition to detection, this method can be used to restore the adversarial images' original labels, which is crucial to restoring the normal functionalities of DNN-based systems. Testing using an adversarial machine learning database we created for generating several types of attack using images from the ImageNet Large Scale Visual Recognition Challenge database demonstrated the efficiency of our proposed method for both detection and correction.
Transferring neural speech waveform synthesizers to musical instrument sounds generation
Nov 19, 2019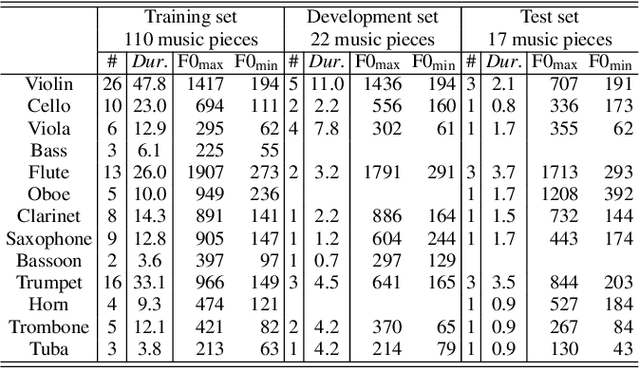
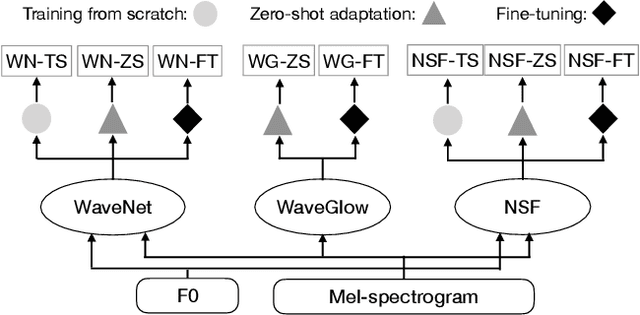
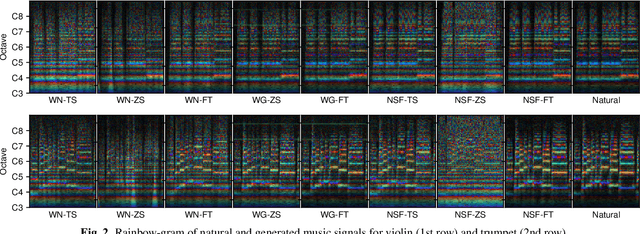
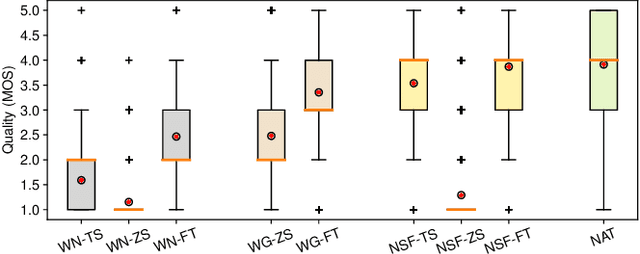
Recent neural waveform synthesizers such as WaveNet, WaveGlow, and the neural-source-filter (NSF) model have shown good performance in speech synthesis despite their different methods of waveform generation. The similarity between speech and music audio synthesis techniques suggests interesting avenues to explore in terms of the best way to apply speech synthesizers in the music domain. This work compares three neural synthesizers used for musical instrument sounds generation under three scenarios: training from scratch on music data, zero-shot learning from the speech domain, and fine-tuning-based adaptation from the speech to the music domain. The results of a large-scale perceptual test demonstrated that the performance of three synthesizers improved when they were pre-trained on speech data and fine-tuned on music data, which indicates the usefulness of knowledge from speech data for music audio generation. Among the synthesizers, WaveGlow showed the best potential in zero-shot learning while NSF performed best in the other scenarios and could generate samples that were perceptually close to natural audio.
Security of Facial Forensics Models Against Adversarial Attacks
Nov 02, 2019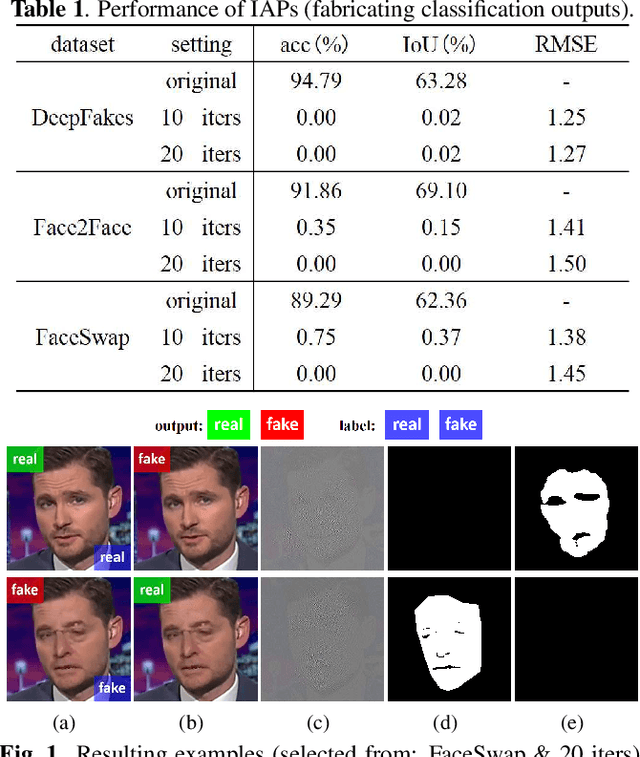

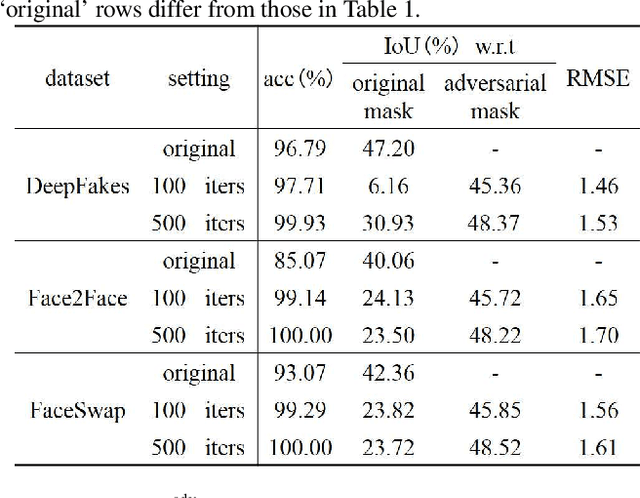

Deep neural networks (DNNs) have been used in forensics to identify fake facial images. We investigated several DNN-based forgery forensics models (FFMs) to determine whether they are secure against adversarial attacks. We experimentally demonstrated the existence of individual adversarial perturbations (IAPs) and universal adversarial perturbations (UAPs) that can lead a well-performed FFM to misbehave. Based on iterative procedure, gradient information is used to generate two kinds of IAPs that can be used to fabricate classification and segmentation outputs. In contrast, UAPs are generated on the basis of over-firing. We designed a new objective function that encourages neurons to over-fire, which makes UAP generation feasible even without using training data. Experiments demonstrated the transferability of UAPs across unseen datasets and unseen FFMs. Moreover, we are the first to conduct subjective assessment for imperceptibility of the adversarial perturbations, revealing that the crafted UAPs are visually negligible. There findings provide a baseline for evaluating the adversarial security of FFMs.
A Method for Identifying Origin of Digital Images Using a Convolution Neural Network
Nov 02, 2019

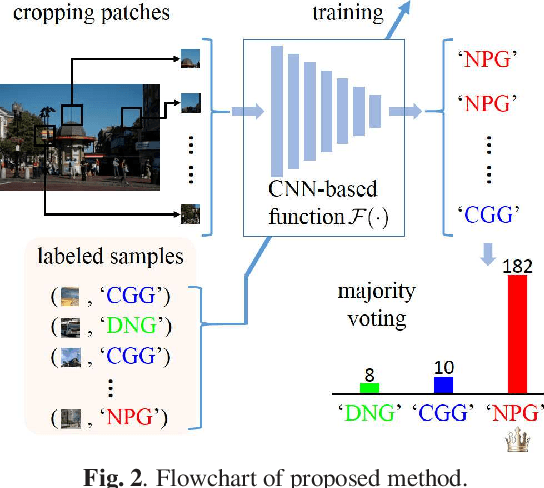
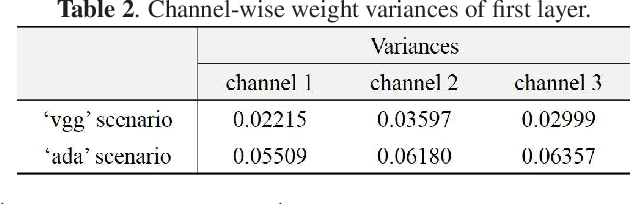
The rapid development of deep learning techniques has created new challenges in identifying the origin of digital images because generative adversarial networks and variational autoencoders can create plausible digital images whose contents are not present in natural scenes. In this paper, we consider the origin that can be broken down into three categories: natural photographic image (NPI), computer generated graphic (CGG), and deep network generated image (DGI). A method is presented for effectively identifying the origin of digital images that is based on a convolutional neural network (CNN) and uses a local-to-global framework to reduce training complexity. By feeding labeled data, the CNN is trained to predict the origin of local patches cropped from an image. The origin of the full-size image is then determined by majority voting. Unlike previous forensic methods, the CNN takes the raw pixels as input without the aid of "residual map". Experimental results revealed that not only the high-frequency components but also the middle-frequency ones contribute to origin identification. The proposed method achieved up to 95.21% identification accuracy and behaved robustly against several common post-processing operations including JPEG compression, scaling, geometric transformation, and contrast stretching. The quantitative results demonstrate that the proposed method is more effective than handcrafted feature-based methods.
Use of a Capsule Network to Detect Fake Images and Videos
Oct 29, 2019


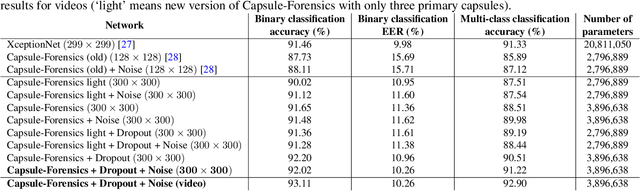
The revolution in computer hardware, especially in graphics processing units and tensor processing units, has enabled significant advances in computer graphics and artificial intelligence algorithms. In addition to their many beneficial applications in daily life and business, computer-generated/manipulated images and videos can be used for malicious purposes that violate security systems, privacy, and social trust. The deepfake phenomenon and its variations enable a normal user to use his or her personal computer to easily create fake videos of anybody from a short real online video. Several countermeasures have been introduced to deal with attacks using such videos. However, most of them are targeted at certain domains and are ineffective when applied to other domains or new attacks. In this paper, we introduce a capsule network that can detect various kinds of attacks, from presentation attacks using printed images and replayed videos to attacks using fake videos created using deep learning. It uses many fewer parameters than traditional convolutional neural networks with similar performance. Moreover, we explain, for the first time ever in the literature, the theory behind the application of capsule networks to the forensics problem through detailed analysis and visualization.
Effect of choice of probability distribution, randomness, and search methods for alignment modeling in sequence-to-sequence text-to-speech synthesis using hard alignment
Oct 28, 2019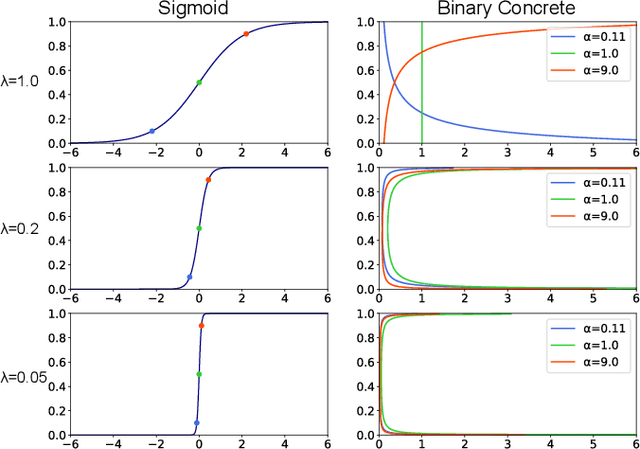
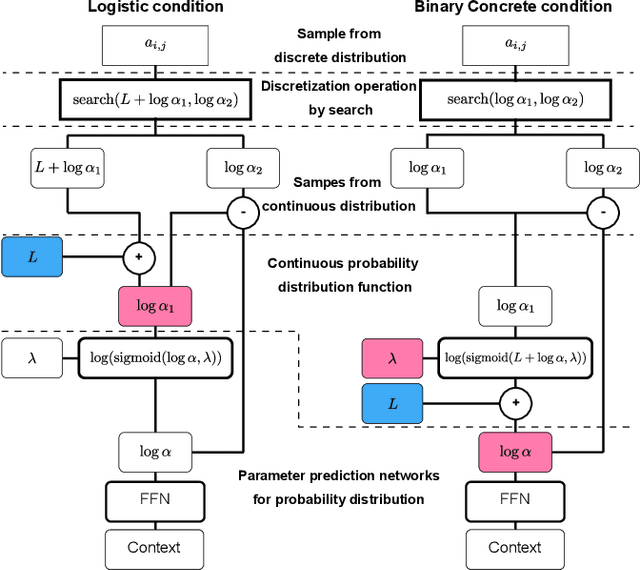
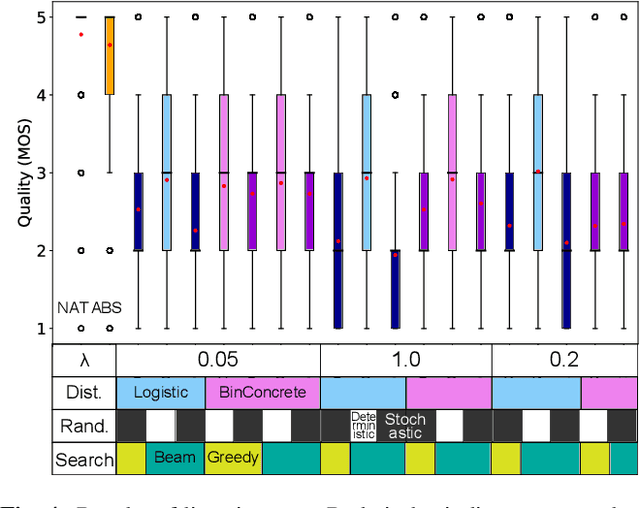
Sequence-to-sequence text-to-speech (TTS) is dominated by soft-attention-based methods. Recently, hard-attention-based methods have been proposed to prevent fatal alignment errors, but their sampling method of discrete alignment is poorly investigated. This research investigates various combinations of sampling methods and probability distributions for alignment transition modeling in a hard-alignment-based sequence-to-sequence TTS method called SSNT-TTS. We clarify the common sampling methods of discrete variables including greedy search, beam search, and random sampling from a Bernoulli distribution in a more general way. Furthermore, we introduce the binary Concrete distribution to model discrete variables more properly. The results of a listening test shows that deterministic search is more preferable than stochastic search, and the binary Concrete distribution is robust with stochastic search for natural alignment transition.
Bootstrapping non-parallel voice conversion from speaker-adaptive text-to-speech
Sep 14, 2019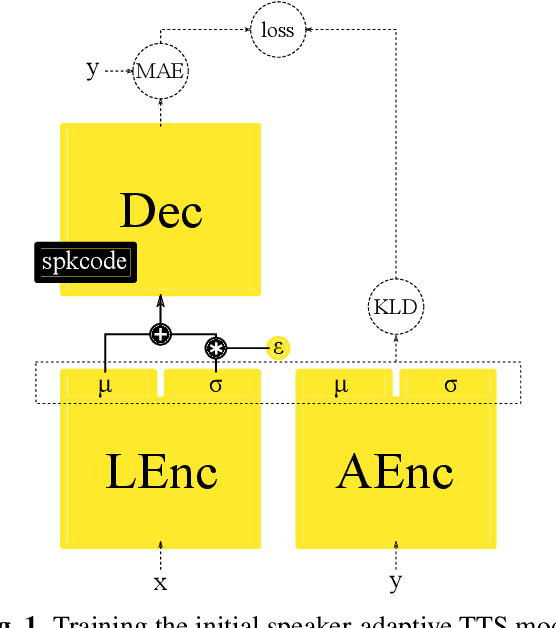
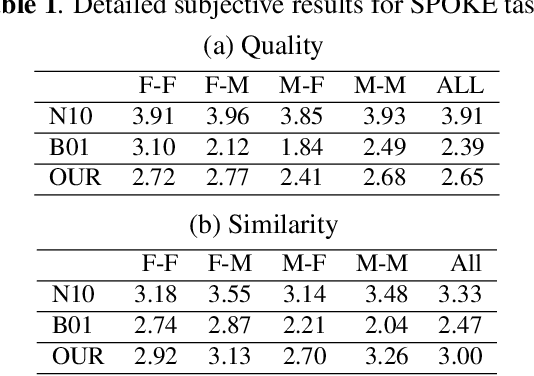
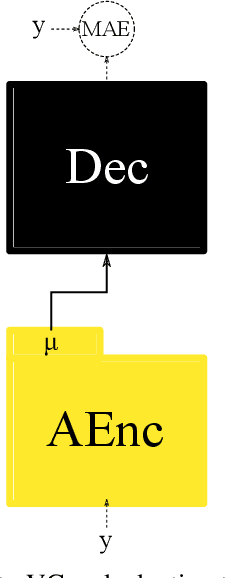
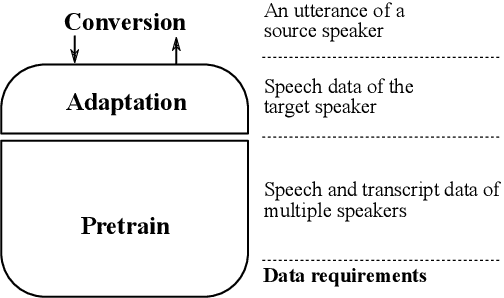
Voice conversion (VC) and text-to-speech (TTS) are two tasks that share a similar objective, generating speech with a target voice. However, they are usually developed independently under vastly different frameworks. In this paper, we propose a methodology to bootstrap a VC system from a pretrained speaker-adaptive TTS model and unify the techniques as well as the interpretations of these two tasks. Moreover by offloading the heavy data demand to the training stage of the TTS model, our VC system can be built using a small amount of target speaker speech data. It also opens up the possibility of using speech in a foreign unseen language to build the system. Our subjective evaluations show that the proposed framework is able to not only achieve competitive performance in the standard intra-language scenario but also adapt and convert using speech utterances in an unseen language.
Initial investigation of an encoder-decoder end-to-end TTS framework using marginalization of monotonic hard latent alignments
Aug 30, 2019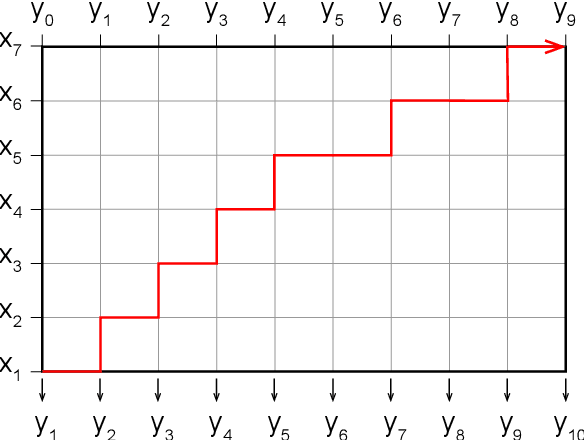

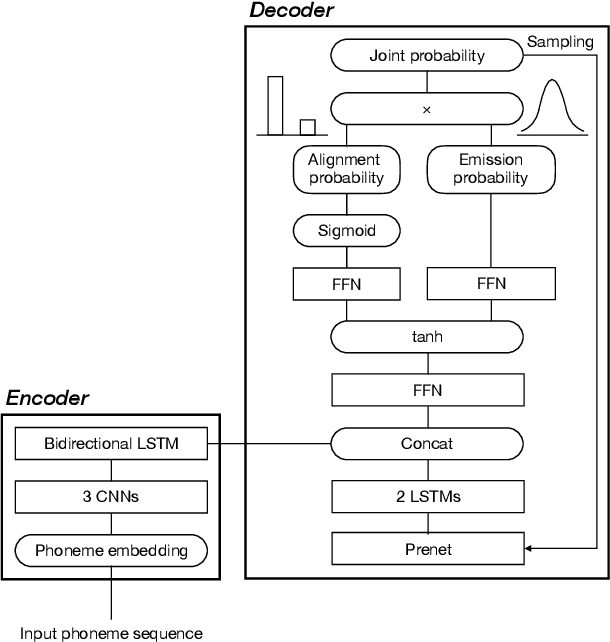
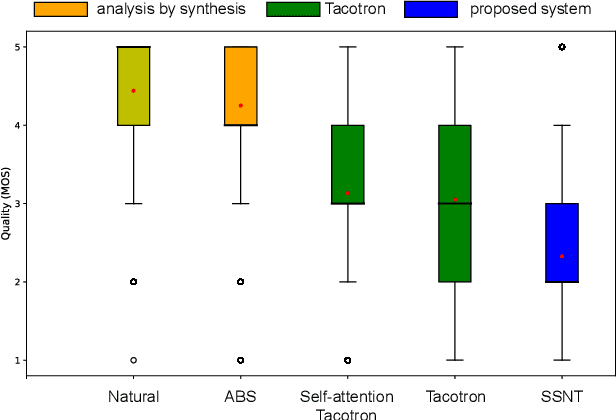
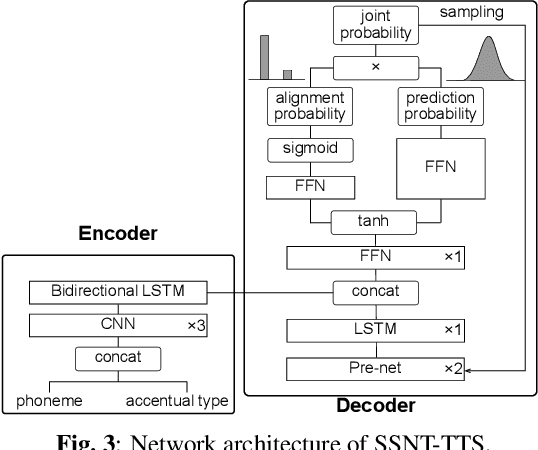
End-to-end text-to-speech (TTS) synthesis is a method that directly converts input text to output acoustic features using a single network. A recent advance of end-to-end TTS is due to a key technique called attention mechanisms, and all successful methods proposed so far have been based on soft attention mechanisms. However, although network structures are becoming increasingly complex, end-to-end TTS systems with soft attention mechanisms may still fail to learn and to predict accurate alignment between the input and output. This may be because the soft attention mechanisms are too flexible. Therefore, we propose an approach that has more explicit but natural constraints suitable for speech signals to make alignment learning and prediction of end-to-end TTS systems more robust. The proposed system, with the constrained alignment scheme borrowed from segment-to-segment neural transduction (SSNT), directly calculates the joint probability of acoustic features and alignment given an input text. The alignment is designed to be hard and monotonically increase by considering the speech nature, and it is treated as a latent variable and marginalized during training. During prediction, both the alignment and acoustic features can be generated from the probabilistic distributions. The advantages of our approach are that we can simplify many modules for the soft attention and that we can train the end-to-end TTS model using a single likelihood function. As far as we know, our approach is the first end-to-end TTS without a soft attention mechanism.
Generating Sentiment-Preserving Fake Online Reviews Using Neural Language Models and Their Human- and Machine-based Detection
Jul 22, 2019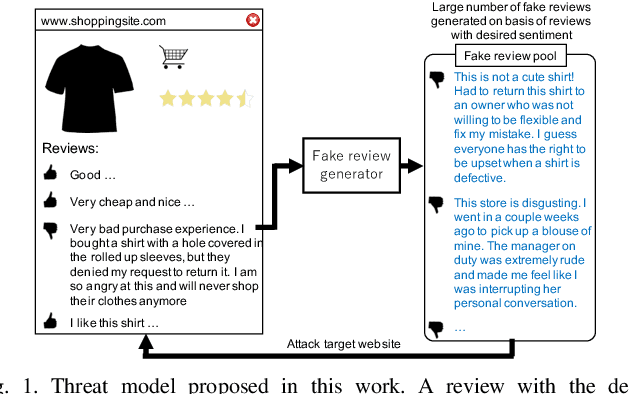
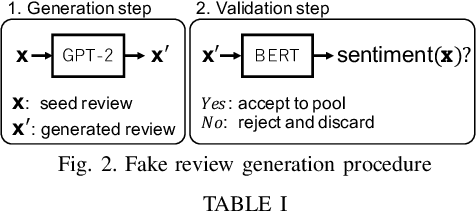


Advanced neural language models (NLMs) are widely used in sequence generation tasks because they are able to produce fluent and meaningful sentences. They can also be used to generate fake reviews, which can then be used to attack online review systems and influence the buying decisions of online shoppers. A problem in fake review generation is how to generate the desired sentiment/topic. Existing solutions first generate an initial review based on some keywords and then modify some of the words in the initial review so that the review has the desired sentiment/topic. We overcome this problem by using the GPT-2 NLM to generate a large number of high-quality reviews based on a review with the desired sentiment and then using a BERT based text classifier (with accuracy of 96\%) to filter out reviews with undesired sentiments. Because none of the words in the review are modified, fluent samples like the training data can be generated from the learned distribution. A subjective evaluation with 80 participants demonstrated that this simple method can produce reviews that are as fluent as those written by people. It also showed that the participants tended to distinguish fake reviews randomly. Two countermeasures, GROVER and GLTR, were found to be able to accurately detect fake review.