 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Pass Rate Tell the Whole Story? Evaluating Design Constraint Compliance in LLM-based Issue Resolution
Apr 07, 2026Repository-level issue resolution benchmarks have become a standard testbed for evaluating LLM-based agents, yet success is still predominantly measured by test pass rates. In practice, however, acceptable patches must also comply with project-specific design constraints, such as architectural conventions, error-handling policies, and maintainability requirements, which are rarely encoded in tests and are often documented only implicitly in code review discussions. This paper introduces \textit{design-aware issue resolution} and presents \bench{}, a benchmark that makes such implicit design constraints explicit and measurable. \bench{} is constructed by mining and validating design constraints from real-world pull requests, linking them to issue instances, and automatically checking patch compliance using an LLM-based verifier, yielding 495 issues and 1,787 validated constraints across six repositories, aligned with SWE-bench-Verified and SWE-bench-Pro. Experiments with state-of-the-art agents show that test-based correctness substantially overestimates patch quality: fewer than half of resolved issues are fully design-satisfying, design violations are widespread, and functional correctness exhibits negligible statistical association with design satisfaction. While providing issue-specific design guidance reduces violations, substantial non-compliance remains, highlighting a fundamental gap in current agent capabilities and motivating design-aware evaluation beyond functional correctness.
Application of Deep Self-Attention in Knowledge Tracing
May 23, 2021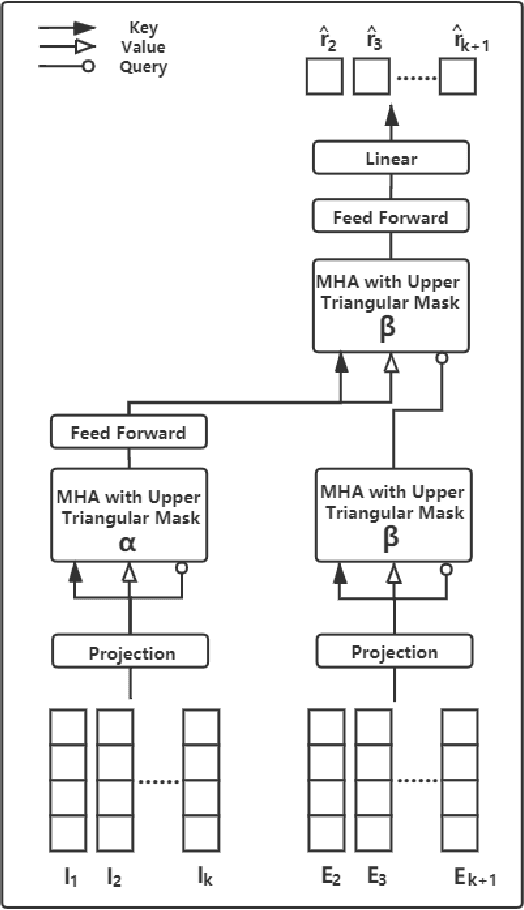
The development of intelligent tutoring system has greatly influenced the way students learn and practice, which increases their learning efficiency. The intelligent tutoring system must model learners' mastery of the knowledge before providing feedback and advices to learners, so one class of algorithm called "knowledge tracing" is surely important. This paper proposed Deep Self-Attentive Knowledge Tracing (DSAKT) based on the data of PTA, an online assessment system used by students in many universities in China, to help these students learn more efficiently. Experimentation on the data of PTA shows that DSAKT outperforms the other models for knowledge tracing an improvement of AUC by 2.1% on average, and this model also has a good performance on the ASSIST dataset.