 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounting Hypothesis: Potential Mechanism of In-Context Learning
Feb 02, 2026In-Context Learning (ICL) indicates that large language models (LLMs) pretrained on a massive amount of data can learn specific tasks from input prompts' examples. ICL is notable for two reasons. First, it does not need modification of LLMs' internal structure. Second, it enables LLMs to perform a wide range of tasks/functions with a few examples demonstrating a desirable task. ICL opens up new ways to utilize LLMs in more domains, but its underlying mechanisms still remain poorly understood, making error correction and diagnosis extremely challenging. Thus, it is imperative that we better understand the limitations of ICL and how exactly LLMs support ICL. Inspired by ICL properties and LLMs' functional modules, we propose 1the counting hypothesis' of ICL, which suggests that LLMs' encoding strategy may underlie ICL, and provide supporting evidence.
Searching for internal symbols underlying deep learning
May 31, 2024



Deep learning (DL) enables deep neural networks (DNNs) to automatically learn complex tasks or rules from given examples without instructions or guiding principles. As we do not engineer DNNs' functions, it is extremely difficult to diagnose their decisions, and multiple lines of studies proposed to explain principles of DNNs/DL operations. Notably, one line of studies suggests that DNNs may learn concepts, the high level features recognizable to humans. Thus, we hypothesized that DNNs develop abstract codes, not necessarily recognizable to humans, which can be used to augment DNNs' decision-making. To address this hypothesis, we combined foundation segmentation models and unsupervised learning to extract internal codes and identify potential use of abstract codes to make DL's decision-making more reliable and safer.
Having Second Thoughts? Let's hear it
Nov 26, 2023



Deep learning models loosely mimic bottom-up signal pathways from low-order sensory areas to high-order cognitive areas. After training, DL models can outperform humans on some domain-specific tasks, but their decision-making process has been known to be easily disrupted. Since the human brain consists of multiple functional areas highly connected to one another and relies on intricate interplays between bottom-up and top-down (from high-order to low-order areas) processing, we hypothesize that incorporating top-down signal processing may make DL models more robust. To address this hypothesis, we propose a certification process mimicking selective attention and test if it could make DL models more robust. Our empirical evaluations suggest that this newly proposed certification can improve DL models' accuracy and help us build safety measures to alleviate their vulnerabilities with both artificial and natural adversarial examples.
One Representation to Rule Them All: Identifying Out-of-Support Examples in Few-shot Learning with Generic Representations
Jun 02, 2021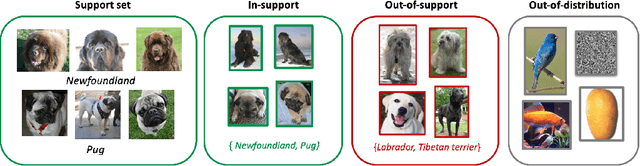
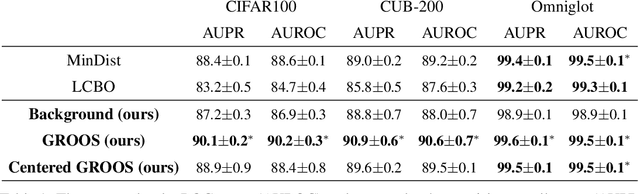
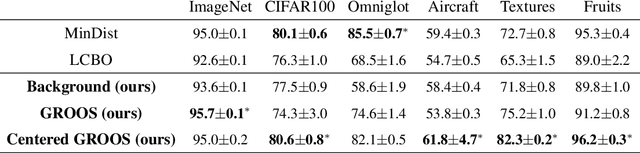
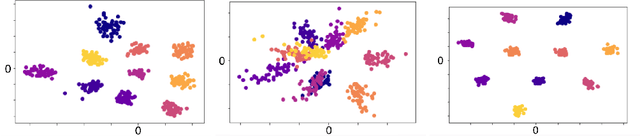
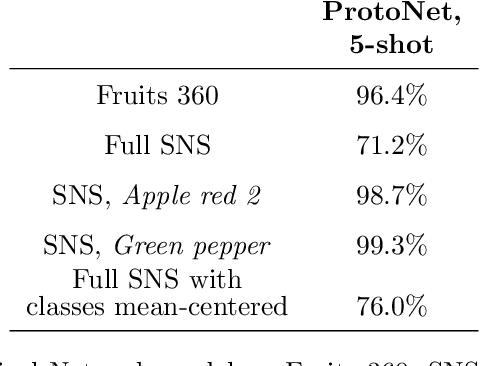
The field of few-shot learning has made remarkable strides in developing powerful models that can operate in the small data regime. Nearly all of these methods assume every unlabeled instance encountered will belong to a handful of known classes for which one has examples. This can be problematic for real-world use cases where one routinely finds 'none-of-the-above' examples. In this paper we describe this challenge of identifying what we term 'out-of-support' (OOS) examples. We describe how this problem is subtly different from out-of-distribution detection and describe a new method of identifying OOS examples within the Prototypical Networks framework using a fixed point which we call the generic representation. We show that our method outperforms other existing approaches in the literature as well as other approaches that we propose in this paper. Finally, we investigate how the use of such a generic point affects the geometry of a model's feature space.
Fuzzy Simplicial Networks: A Topology-Inspired Model to Improve Task Generalization in Few-shot Learning
Sep 23, 2020


Deep learning has shown great success in settings with massive amounts of data but has struggled when data is limited. Few-shot learning algorithms, which seek to address this limitation, are designed to generalize well to new tasks with limited data. Typically, models are evaluated on unseen classes and datasets that are defined by the same fundamental task as they are trained for (e.g. category membership). One can also ask how well a model can generalize to fundamentally different tasks within a fixed dataset (for example: moving from category membership to tasks that involve detecting object orientation or quantity). To formalize this kind of shift we define a notion of "independence of tasks" and identify three new sets of labels for established computer vision datasets that test a model's ability to generalize to tasks which draw on orthogonal attributes in the data. We use these datasets to investigate the failure modes of metric-based few-shot models. Based on our findings, we introduce a new few-shot model called Fuzzy Simplicial Networks (FSN) which leverages a construction from topology to more flexibly represent each class from limited data. In particular, FSN models can not only form multiple representations for a given class but can also begin to capture the low-dimensional structure which characterizes class manifolds in the encoded space of deep networks. We show that FSN outperforms state-of-the-art models on the challenging tasks we introduce in this paper while remaining competitive on standard few-shot benchmarks.
DynMat, a network that can learn after learning
Jun 16, 2018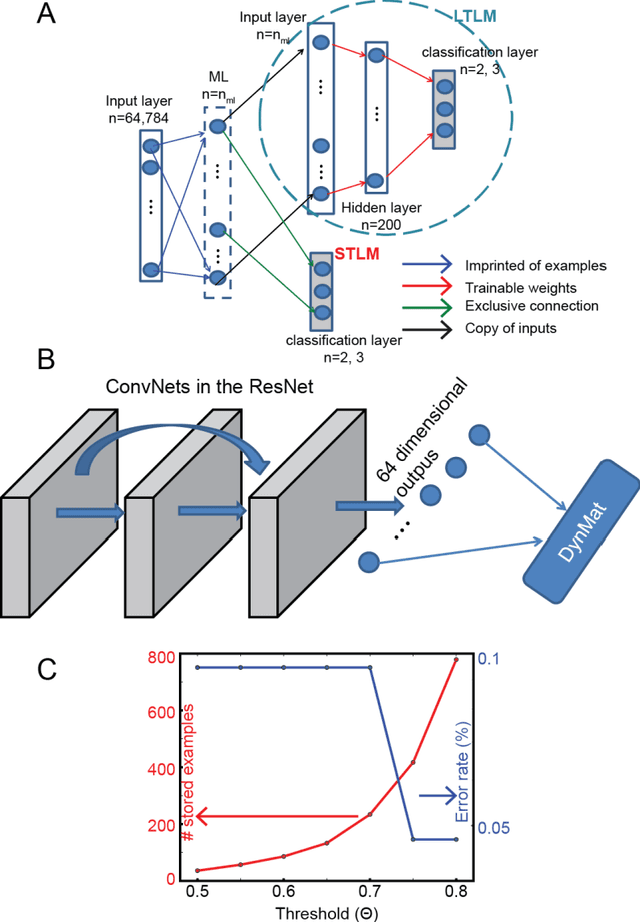
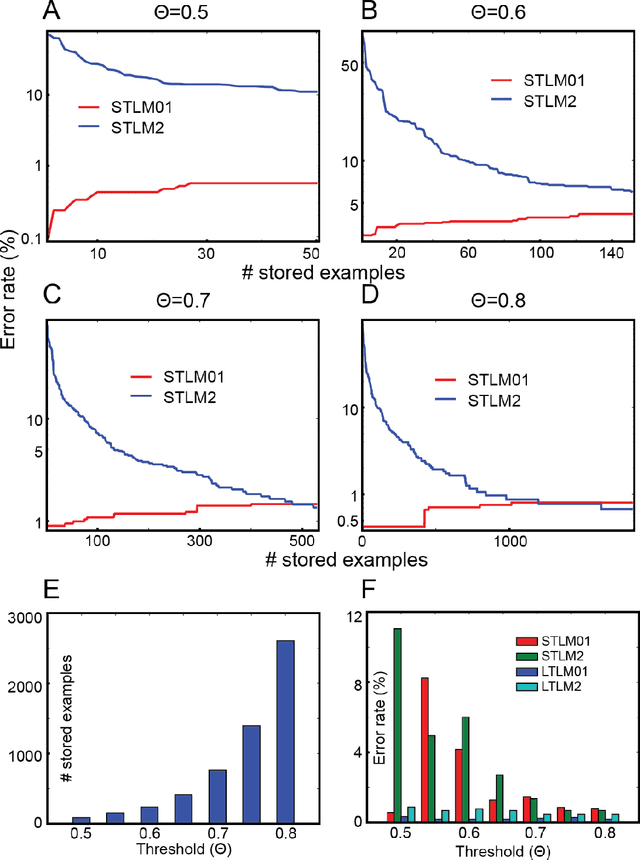
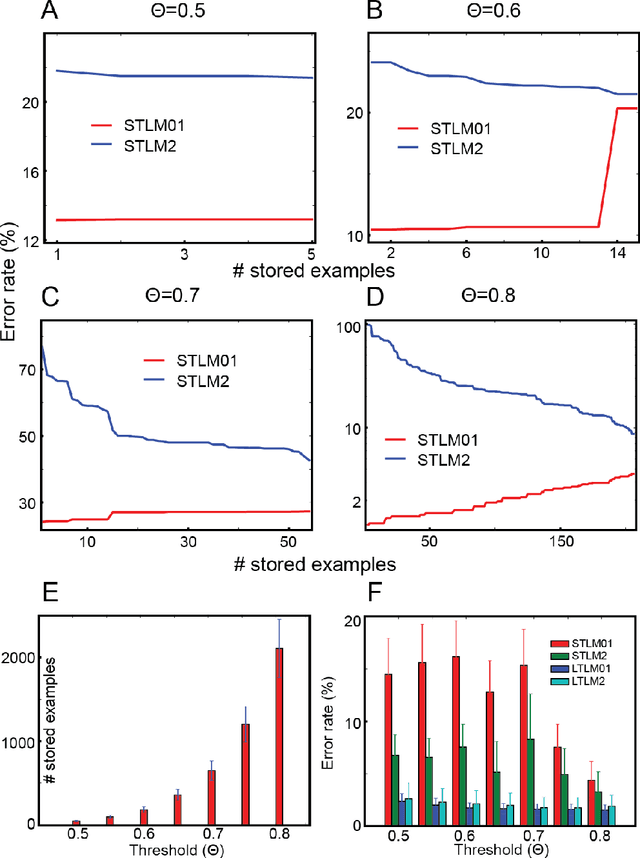
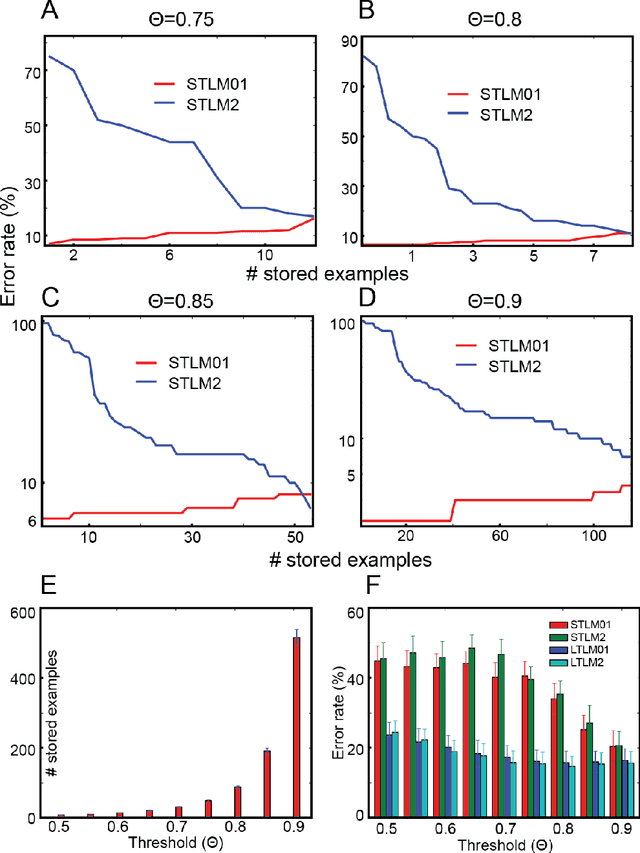
To survive in the dynamically-evolving world, we accumulate knowledge and improve our skills based on experience. In the process, gaining new knowledge does not disrupt our vigilance to external stimuli. In other words, our learning process is 'accumulative' and 'online' without interruption. However, despite the recent success, artificial neural networks (ANNs) must be trained offline, and they suffer catastrophic interference between old and new learning, indicating that ANNs' conventional learning algorithms may not be suitable for building intelligent agents comparable to our brain. In this study, we propose a novel neural network architecture (DynMat) consisting of dual learning systems, inspired by the complementary learning system (CLS) theory suggesting that the brain relies on short- and long-term learning systems to learn continuously. Our experiments show that 1) DynMat can learn a new class without catastrophic interference and 2) it does not strictly require offline training.