 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounting Hypothesis: Potential Mechanism of In-Context Learning
Feb 02, 2026In-Context Learning (ICL) indicates that large language models (LLMs) pretrained on a massive amount of data can learn specific tasks from input prompts' examples. ICL is notable for two reasons. First, it does not need modification of LLMs' internal structure. Second, it enables LLMs to perform a wide range of tasks/functions with a few examples demonstrating a desirable task. ICL opens up new ways to utilize LLMs in more domains, but its underlying mechanisms still remain poorly understood, making error correction and diagnosis extremely challenging. Thus, it is imperative that we better understand the limitations of ICL and how exactly LLMs support ICL. Inspired by ICL properties and LLMs' functional modules, we propose 1the counting hypothesis' of ICL, which suggests that LLMs' encoding strategy may underlie ICL, and provide supporting evidence.
A Nonlinear MPC Framework for Loco-Manipulation of Quadrupedal Robots with Non-Negligible Manipulator Dynamics
Jul 29, 2025Model predictive control (MPC) combined with reduced-order template models has emerged as a powerful tool for trajectory optimization in dynamic legged locomotion. However, loco-manipulation tasks performed by legged robots introduce additional complexity, necessitating computationally efficient MPC algorithms capable of handling high-degree-of-freedom (DoF) models. This letter presents a computationally efficient nonlinear MPC (NMPC) framework tailored for loco-manipulation tasks of quadrupedal robots equipped with robotic manipulators whose dynamics are non-negligible relative to those of the quadruped. The proposed framework adopts a decomposition strategy that couples locomotion template models -- such as the single rigid body (SRB) model -- with a full-order dynamic model of the robotic manipulator for torque-level control. This decomposition enables efficient real-time solution of the NMPC problem in a receding horizon fashion at 60 Hz. The optimal state and input trajectories generated by the NMPC for locomotion are tracked by a low-level nonlinear whole-body controller (WBC) running at 500 Hz, while the optimal torque commands for the manipulator are directly applied. The layered control architecture is validated through extensive numerical simulations and hardware experiments on a 15-kg Unitree Go2 quadrupedal robot augmented with a 4.4-kg 4-DoF Kinova arm. Given that the Kinova arm dynamics are non-negligible relative to the Go2 base, the proposed NMPC framework demonstrates robust stability in performing diverse loco-manipulation tasks, effectively handling external disturbances, payload variations, and uneven terrain.
Spiking Neural Network: a low power solution for physical layer authentication
May 19, 2025Deep learning (DL) is a powerful tool that can solve complex problems, and thus, it seems natural to assume that DL can be used to enhance the security of wireless communication. However, deploying DL models to edge devices in wireless networks is challenging, as they require significant amounts of computing and power resources. Notably, Spiking Neural Networks (SNNs) are known to be efficient in terms of power consumption, meaning they can be an alternative platform for DL models for edge devices. In this study, we ask if SNNs can be used in physical layer authentication. Our evaluation suggests that SNNs can learn unique physical properties (i.e., `fingerprints') of RF transmitters and use them to identify individual devices. Furthermore, we find that SNNs are also vulnerable to adversarial attacks and that an autoencoder can be used clean out adversarial perturbations to harden SNNs against them.
Two out of Three (ToT): using self-consistency to make robust predictions
May 19, 2025Deep learning (DL) can automatically construct intelligent agents, deep neural networks (alternatively, DL models), that can outperform humans in certain tasks. However, the operating principles of DL remain poorly understood, making its decisions incomprehensible. As a result, it poses a great risk to deploy DL in high-stakes domains in which mistakes or errors may lead to critical consequences. Here, we aim to develop an algorithm that can help DL models make more robust decisions by allowing them to abstain from answering when they are uncertain. Our algorithm, named `Two out of Three (ToT)', is inspired by the sensitivity of the human brain to conflicting information. ToT creates two alternative predictions in addition to the original model prediction and uses the alternative predictions to decide whether it should provide an answer or not.
Searching for internal symbols underlying deep learning
May 31, 2024



Deep learning (DL) enables deep neural networks (DNNs) to automatically learn complex tasks or rules from given examples without instructions or guiding principles. As we do not engineer DNNs' functions, it is extremely difficult to diagnose their decisions, and multiple lines of studies proposed to explain principles of DNNs/DL operations. Notably, one line of studies suggests that DNNs may learn concepts, the high level features recognizable to humans. Thus, we hypothesized that DNNs develop abstract codes, not necessarily recognizable to humans, which can be used to augment DNNs' decision-making. To address this hypothesis, we combined foundation segmentation models and unsupervised learning to extract internal codes and identify potential use of abstract codes to make DL's decision-making more reliable and safer.
Having Second Thoughts? Let's hear it
Nov 26, 2023



Deep learning models loosely mimic bottom-up signal pathways from low-order sensory areas to high-order cognitive areas. After training, DL models can outperform humans on some domain-specific tasks, but their decision-making process has been known to be easily disrupted. Since the human brain consists of multiple functional areas highly connected to one another and relies on intricate interplays between bottom-up and top-down (from high-order to low-order areas) processing, we hypothesize that incorporating top-down signal processing may make DL models more robust. To address this hypothesis, we propose a certification process mimicking selective attention and test if it could make DL models more robust. Our empirical evaluations suggest that this newly proposed certification can improve DL models' accuracy and help us build safety measures to alleviate their vulnerabilities with both artificial and natural adversarial examples.
Analysis of functional neural codes of deep learning models
May 22, 2022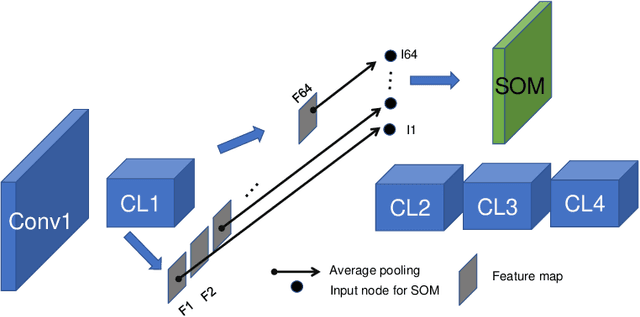
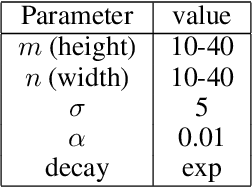
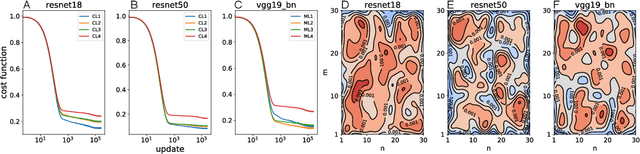
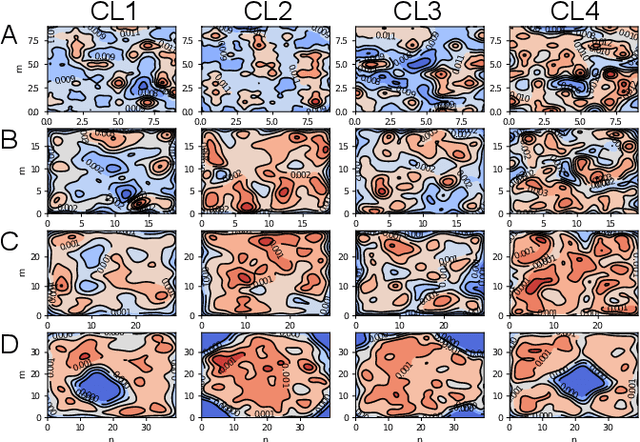
Deep neural networks (DNNs), the agents of deep learning (DL), require a massive number of parallel/sequential operations. This makes it extremely challenging to comprehend DNNs' operations and hinders proper diagnosis. Consequently, DNNs cannot be readily used in high-stakes domains, in which incorrect decisions can lead to catastrophic failures. Therefore, to build more reliable DNNs/DL to be deployed in high-stakes real-world problems, it is imperative that we develop proper analysis tools that will allow us to better understand DNNs' internal operations underlying their decision-making. Here, we used the self-organizing map (SOM) to analyze internal codes of DL models associated with their decision-making. Our analyses suggest that hidden layer activation patterns can be mapped onto a finite number of patterns and are correlated with DL predictions, raising the possibility that they could serve as functional codes of DL models. Encouraged by this observation, we further used SOM to estimate input features coded in hidden layers, analyzed the effects of adversarial inputs to better understand characterized internal representations' evolution and adversarial perturbations' propagation in DL models.