 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do Geometric Hallucination Detection Metrics Actually Measure?
Feb 09, 2026Hallucination remains a barrier to deploying generative models in high-consequence applications. This is especially true in cases where external ground truth is not readily available to validate model outputs. This situation has motivated the study of geometric signals in the internal state of an LLM that are predictive of hallucination and require limited external knowledge. Given that there are a range of factors that can lead model output to be called a hallucination (e.g., irrelevance vs incoherence), in this paper we ask what specific properties of a hallucination these geometric statistics actually capture. To assess this, we generate a synthetic dataset which varies distinct properties of output associated with hallucination. This includes output correctness, confidence, relevance, coherence, and completeness. We find that different geometric statistics capture different types of hallucinations. Along the way we show that many existing geometric detection methods have substantial sensitivity to shifts in task domain (e.g., math questions vs. history questions). Motivated by this, we introduce a simple normalization method to mitigate the effect of domain shift on geometric statistics, leading to AUROC gains of +34 points in multi-domain settings.
Adaptive Transfer Learning: a simple but effective transfer learning
Nov 22, 2021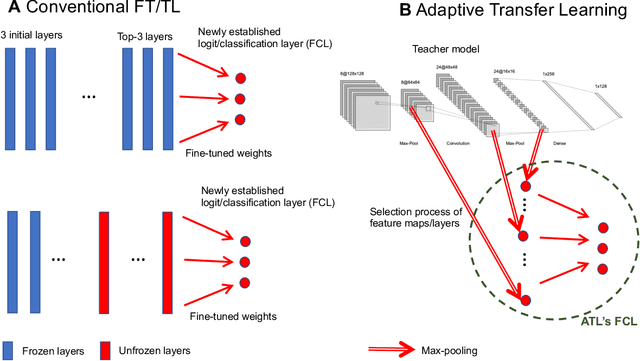
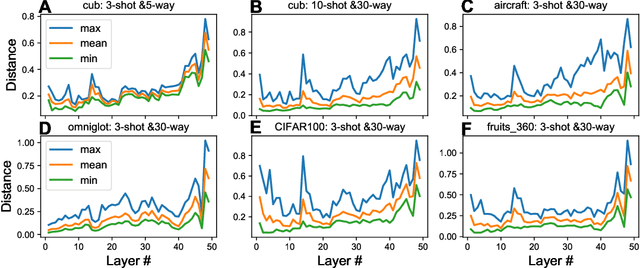
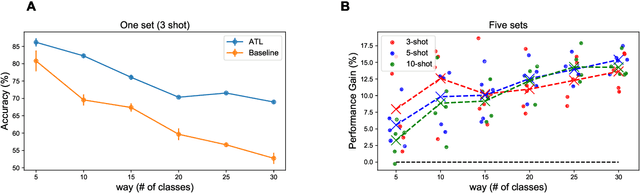
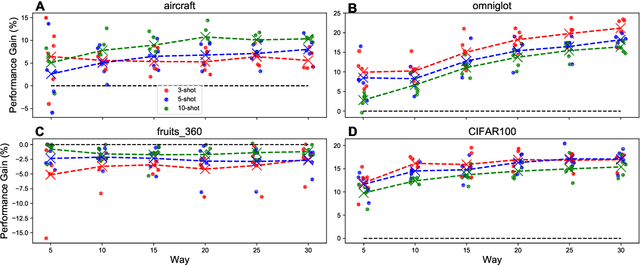
Transfer learning (TL) leverages previously obtained knowledge to learn new tasks efficiently and has been used to train deep learning (DL) models with limited amount of data. When TL is applied to DL, pretrained (teacher) models are fine-tuned to build domain specific (student) models. This fine-tuning relies on the fact that DL model can be decomposed to classifiers and feature extractors, and a line of studies showed that the same feature extractors can be used to train classifiers on multiple tasks. Furthermore, recent studies proposed multiple algorithms that can fine-tune teacher models' feature extractors to train student models more efficiently. We note that regardless of the fine-tuning of feature extractors, the classifiers of student models are trained with final outputs of feature extractors (i.e., the outputs of penultimate layers). However, a recent study suggested that feature maps in ResNets across layers could be functionally equivalent, raising the possibility that feature maps inside the feature extractors can also be used to train student models' classifiers. Inspired by this study, we tested if feature maps in the hidden layers of the teacher models can be used to improve the student models' accuracy (i.e., TL's efficiency). Specifically, we developed 'adaptive transfer learning (ATL)', which can choose an optimal set of feature maps for TL, and tested it in the few-shot learning setting. Our empirical evaluations suggest that ATL can help DL models learn more efficiently, especially when available examples are limited.
One Representation to Rule Them All: Identifying Out-of-Support Examples in Few-shot Learning with Generic Representations
Jun 02, 2021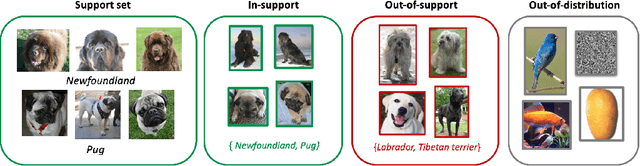
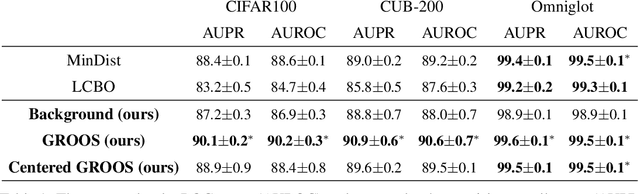
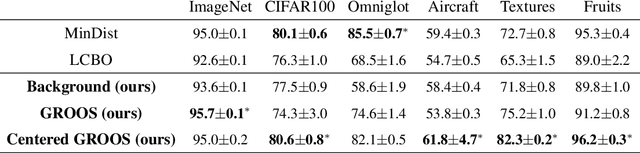
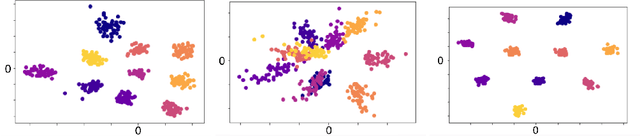
The field of few-shot learning has made remarkable strides in developing powerful models that can operate in the small data regime. Nearly all of these methods assume every unlabeled instance encountered will belong to a handful of known classes for which one has examples. This can be problematic for real-world use cases where one routinely finds 'none-of-the-above' examples. In this paper we describe this challenge of identifying what we term 'out-of-support' (OOS) examples. We describe how this problem is subtly different from out-of-distribution detection and describe a new method of identifying OOS examples within the Prototypical Networks framework using a fixed point which we call the generic representation. We show that our method outperforms other existing approaches in the literature as well as other approaches that we propose in this paper. Finally, we investigate how the use of such a generic point affects the geometry of a model's feature space.