 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHg-I2P: Bridging Modalities for Generalizable Image-to-Point-Cloud Registration via Heterogeneous Graphs
Mar 30, 2026Image-to-point-cloud (I2P) registration aims to align 2D images with 3D point clouds by establishing reliable 2D-3D correspondences. The drastic modality gap between images and point clouds makes it challenging to learn features that are both discriminative and generalizable, leading to severe performance drops in unseen scenarios. We address this challenge by introducing a heterogeneous graph that enables refining both cross-modal features and correspondences within a unified architecture. The proposed graph represents a mapping between segmented 2D and 3D regions, which enhances cross-modal feature interaction and thus improves feature discriminability. In addition, modeling the consistency among vertices and edges within the graph enables pruning of unreliable correspondences. Building on these insights, we propose a heterogeneous graph embedded I2P registration method, termed Hg-I2P. It learns a heterogeneous graph by mining multi-path feature relationships, adapts features under the guidance of heterogeneous edges, and prunes correspondences using graph-based projection consistency. Experiments on six indoor and outdoor benchmarks under cross-domain setups demonstrate that Hg-I2P significantly outperforms existing methods in both generalization and accuracy. Code is released on https://github.com/anpei96/hg-i2p-demo.
SDGOCC: Semantic and Depth-Guided Bird's-Eye View Transformation for 3D Multimodal Occupancy Prediction
Jul 22, 2025Multimodal 3D occupancy prediction has garnered significant attention for its potential in autonomous driving. However, most existing approaches are single-modality: camera-based methods lack depth information, while LiDAR-based methods struggle with occlusions. Current lightweight methods primarily rely on the Lift-Splat-Shoot (LSS) pipeline, which suffers from inaccurate depth estimation and fails to fully exploit the geometric and semantic information of 3D LiDAR points. Therefore, we propose a novel multimodal occupancy prediction network called SDG-OCC, which incorporates a joint semantic and depth-guided view transformation coupled with a fusion-to-occupancy-driven active distillation. The enhanced view transformation constructs accurate depth distributions by integrating pixel semantics and co-point depth through diffusion and bilinear discretization. The fusion-to-occupancy-driven active distillation extracts rich semantic information from multimodal data and selectively transfers knowledge to image features based on LiDAR-identified regions. Finally, for optimal performance, we introduce SDG-Fusion, which uses fusion alone, and SDG-KL, which integrates both fusion and distillation for faster inference. Our method achieves state-of-the-art (SOTA) performance with real-time processing on the Occ3D-nuScenes dataset and shows comparable performance on the more challenging SurroundOcc-nuScenes dataset, demonstrating its effectiveness and robustness. The code will be released at https://github.com/DzpLab/SDGOCC.
Transferable Force-Torque Dynamics Model for Peg-in-hole Task
Nov 30, 2019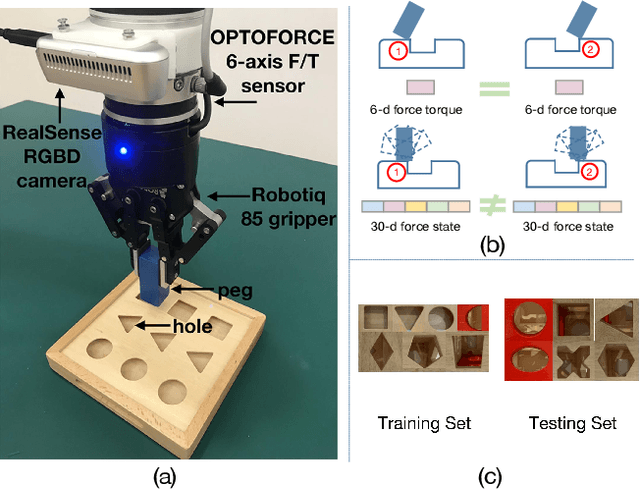
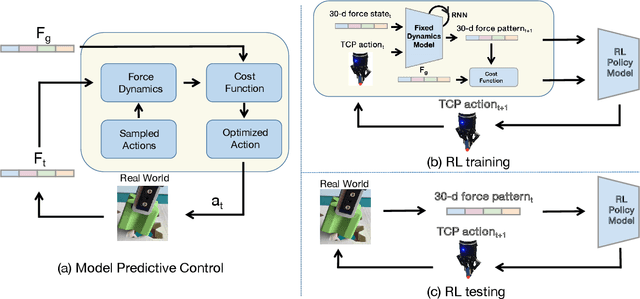
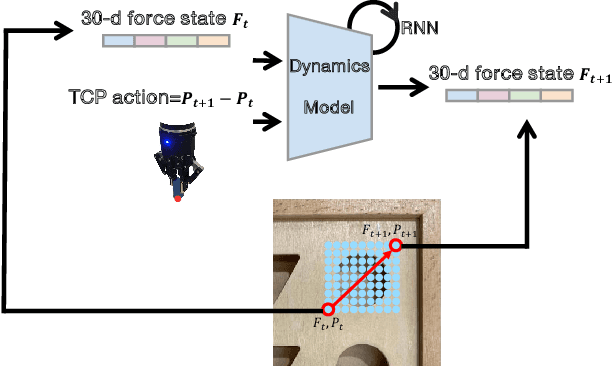
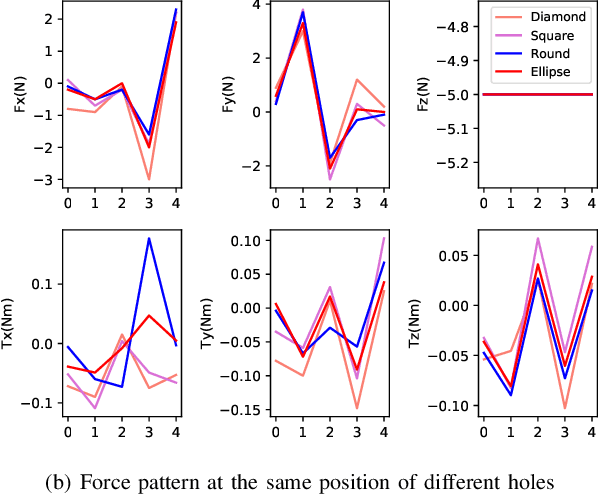
We present a learning-based force-torque dynamics to achieve model-based control for contact-rich peg-in-hole task using force-only inputs. Learning the force-torque dynamics is challenging because of the ambiguity of the low-dimensional 6-d force signal and the requirement of excessive training data. To tackle these problems, we propose a multi-pose force-torque state representation, based on which a dynamics model is learned with the data generated in a sample-efficient offline fashion. In addition, by training the dynamics model with peg-and-holes of various shapes, scales, and elasticities, the model could quickly transfer to new peg-and-holes after a small number of trials. Extensive experiments show that our dynamics model could adapt to unseen peg-and-holes with 70% fewer samples required compared to learning from scratch. Along with the learned dynamics, model predictive control and model-based reinforcement learning policies achieve over 80% insertion success rate. Our video is available at https://youtu.be/ZAqldpVZgm4.