 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Uncertainty Matching for Unsupervised Domain Adaptation
Jun 24, 2019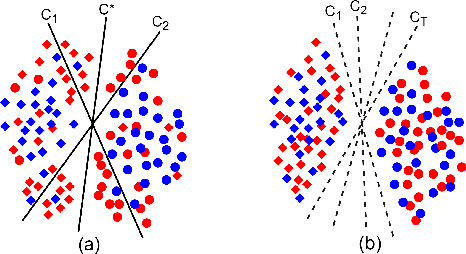
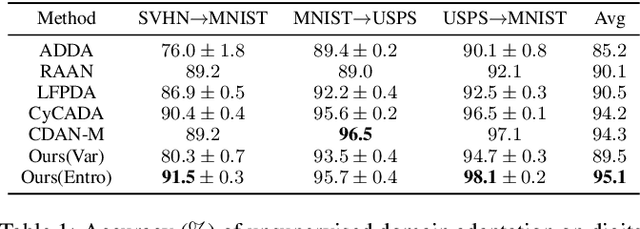
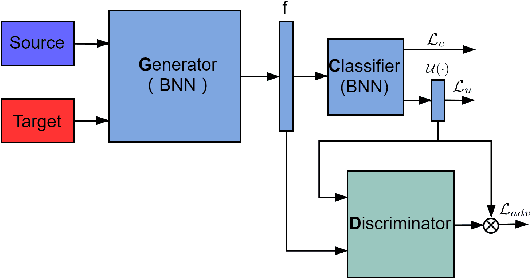
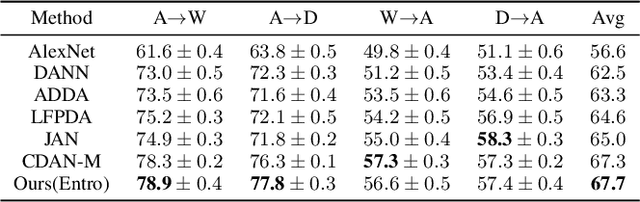
Domain adaptation is an important technique to alleviate performance degradation caused by domain shift, e.g., when training and test data come from different domains. Most existing deep adaptation methods focus on reducing domain shift by matching marginal feature distributions through deep transformations on the input features, due to the unavailability of target domain labels. We show that domain shift may still exist via label distribution shift at the classifier, thus deteriorating model performances. To alleviate this issue, we propose an approximate joint distribution matching scheme by exploiting prediction uncertainty. Specifically, we use a Bayesian neural network to quantify prediction uncertainty of a classifier. By imposing distribution matching on both features and labels (via uncertainty), label distribution mismatching in source and target data is effectively alleviated, encouraging the classifier to produce consistent predictions across domains. We also propose a few techniques to improve our method by adaptively reweighting domain adaptation loss to achieve nontrivial distribution matching and stable training. Comparisons with state of the art unsupervised domain adaptation methods on three popular benchmark datasets demonstrate the superiority of our approach, especially on the effectiveness of alleviating negative transfer.
Exploiting Local Feature Patterns for Unsupervised Domain Adaptation
Nov 18, 2018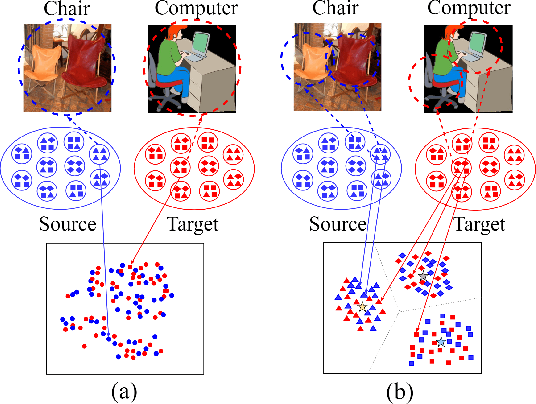
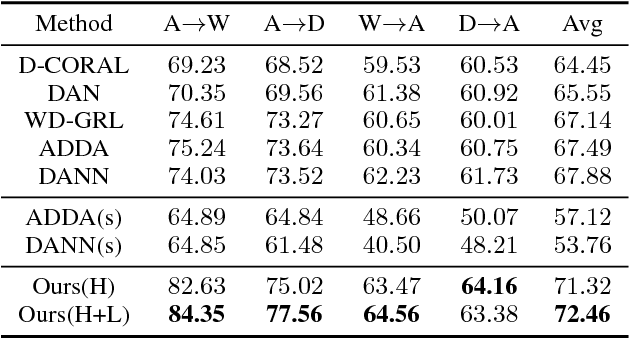
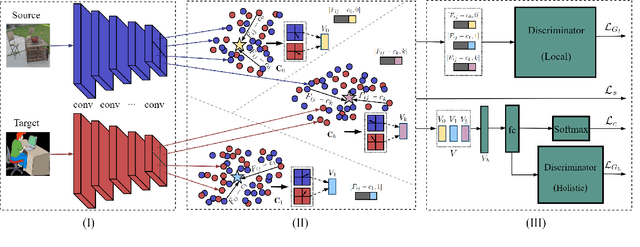
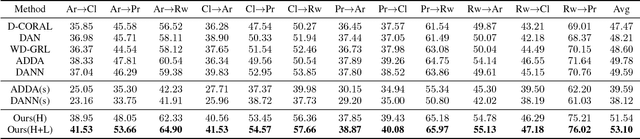
Unsupervised domain adaptation methods aim to alleviate performance degradation caused by domain-shift by learning domain-invariant representations. Existing deep domain adaptation methods focus on holistic feature alignment by matching source and target holistic feature distributions, without considering local features and their multi-mode statistics. We show that the learned local feature patterns are more generic and transferable and a further local feature distribution matching enables fine-grained feature alignment. In this paper, we present a method for learning domain-invariant local feature patterns and jointly aligning holistic and local feature statistics. Comparisons to the state-of-the-art unsupervised domain adaptation methods on two popular benchmark datasets demonstrate the superiority of our approach and its effectiveness on alleviating negative transfer.
Object-Level Representation Learning for Few-Shot Image Classification
May 28, 2018
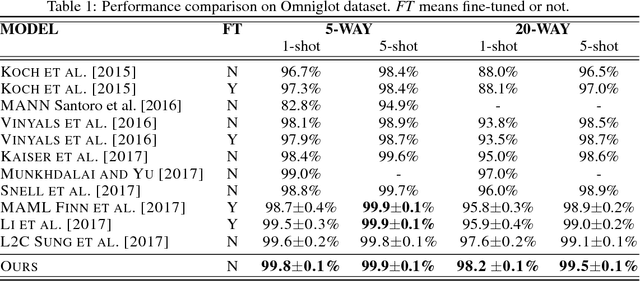
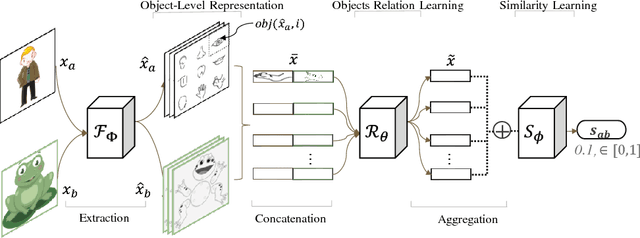
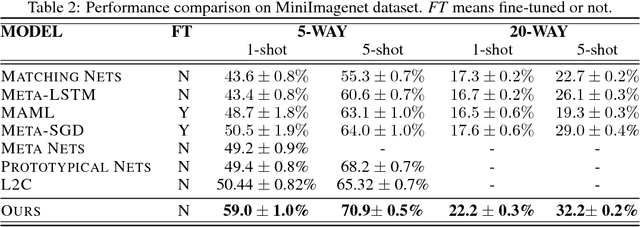
Few-shot learning that trains image classifiers over few labeled examples per category is a challenging task. In this paper, we propose to exploit an additional big dataset with different categories to improve the accuracy of few-shot learning over our target dataset. Our approach is based on the observation that images can be decomposed into objects, which may appear in images from both the additional dataset and our target dataset. We use the object-level relation learned from the additional dataset to infer the similarity of images in our target dataset with unseen categories. Nearest neighbor search is applied to do image classification, which is a non-parametric model and thus does not need fine-tuning. We evaluate our algorithm on two popular datasets, namely Omniglot and MiniImagenet. We obtain 8.5\% and 2.7\% absolute improvements for 5-way 1-shot and 5-way 5-shot experiments on MiniImagenet, respectively. Source code will be published upon acceptance.