 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Assessment of Lidar Odometry Frameworks: A Case Study at the Australian Botanic Garden Mount Annan
Nov 25, 2024



Autonomous vehicles are being tested in diverse environments worldwide. However, a notable gap exists in evaluating datasets representing natural, unstructured environments such as forests or gardens. To address this, we present a study on localisation at the Australian Botanic Garden Mount Annan. This area encompasses open grassy areas, paved pathways, and densely vegetated sections with trees and other objects. The dataset was recorded using a 128-beam LiDAR sensor and GPS and IMU readings to track the ego-vehicle. This paper evaluates the performance of two state-of-the-art LiDARinertial odometry frameworks, COIN-LIO and LIO-SAM, on this dataset. We analyse trajectory estimates in both horizontal and vertical dimensions and assess relative translation and yaw errors over varying distances. Our findings reveal that while both frameworks perform adequately in the vertical plane, COINLIO demonstrates superior accuracy in the horizontal plane, particularly over extended trajectories. In contrast, LIO-SAM shows increased drift and yaw errors over longer distances.
Label-Efficient 3D Object Detection For Road-Side Units
Apr 09, 2024



Occlusion presents a significant challenge for safety-critical applications such as autonomous driving. Collaborative perception has recently attracted a large research interest thanks to the ability to enhance the perception of autonomous vehicles via deep information fusion with intelligent roadside units (RSU), thus minimizing the impact of occlusion. While significant advancement has been made, the data-hungry nature of these methods creates a major hurdle for their real-world deployment, particularly due to the need for annotated RSU data. Manually annotating the vast amount of RSU data required for training is prohibitively expensive, given the sheer number of intersections and the effort involved in annotating point clouds. We address this challenge by devising a label-efficient object detection method for RSU based on unsupervised object discovery. Our paper introduces two new modules: one for object discovery based on a spatial-temporal aggregation of point clouds, and another for refinement. Furthermore, we demonstrate that fine-tuning on a small portion of annotated data allows our object discovery models to narrow the performance gap with, or even surpass, fully supervised models. Extensive experiments are carried out in simulated and real-world datasets to evaluate our method.
OccFusion: A Straightforward and Effective Multi-Sensor Fusion Framework for 3D Occupancy Prediction
Mar 13, 2024



This paper introduces OccFusion, a straightforward and efficient sensor fusion framework for predicting 3D occupancy. A comprehensive understanding of 3D scenes is crucial in autonomous driving, and recent models for 3D semantic occupancy prediction have successfully addressed the challenge of describing real-world objects with varied shapes and classes. However, existing methods for 3D occupancy prediction heavily rely on surround-view camera images, making them susceptible to changes in lighting and weather conditions. By integrating features from additional sensors, such as lidar and surround view radars, our framework enhances the accuracy and robustness of occupancy prediction, resulting in top-tier performance on the nuScenes benchmark. Furthermore, extensive experiments conducted on the nuScenes dataset, including challenging night and rainy scenarios, confirm the superior performance of our sensor fusion strategy across various perception ranges. The code for this framework will be made available at https://github.com/DanielMing123/OCCFusion.
InverseMatrixVT3D: An Efficient Projection Matrix-Based Approach for 3D Occupancy Prediction
Jan 23, 2024



This paper introduces InverseMatrixVT3D, an efficient method for transforming multi-view image features into 3D feature volumes for 3D semantic occupancy prediction. Existing methods for constructing 3D volumes often rely on depth estimation, device-specific operators, or transformer queries, which hinders the widespread adoption of 3D occupancy models. In contrast, our approach leverages two projection matrices to store the static mapping relationships and matrix multiplications to efficiently generate global Bird's Eye View (BEV) features and local 3D feature volumes. Specifically, we achieve this by performing matrix multiplications between multi-view image feature maps and two sparse projection matrices. We introduce a sparse matrix handling technique for the projection matrices to optimise GPU memory usage. Moreover, a global-local attention fusion module is proposed to integrate the global BEV features with the local 3D feature volumes to obtain the final 3D volume. We also employ a multi-scale supervision mechanism to further enhance performance. Comprehensive experiments on the nuScenes dataset demonstrate the simplicity and effectiveness of our method. The code will be made available at:https://github.com/DanielMing123/InverseMatrixVT3D
Classification of Safety Driver Attention During Autonomous Vehicle Operation
Oct 17, 2023



Despite the continual advances in Advanced Driver Assistance Systems (ADAS) and the development of high-level autonomous vehicles (AV), there is a general consensus that for the short to medium term, there is a requirement for a human supervisor to handle the edge cases that inevitably arise. Given this requirement, it is essential that the state of the vehicle operator is monitored to ensure they are contributing to the vehicle's safe operation. This paper introduces a dual-source approach integrating data from an infrared camera facing the vehicle operator and vehicle perception systems to produce a metric for driver alertness in order to promote and ensure safe operator behaviour. The infrared camera detects the driver's head, enabling the calculation of head orientation, which is relevant as the head typically moves according to the individual's focus of attention. By incorporating environmental data from the perception system, it becomes possible to determine whether the vehicle operator observes objects in the surroundings. Experiments were conducted using data collected in Sydney, Australia, simulating AV operations in an urban environment. Our results demonstrate that the proposed system effectively determines a metric for the attention levels of the vehicle operator, enabling interventions such as warnings or reducing autonomous functionality as appropriate. This comprehensive solution shows promise in contributing to ADAS and AVs' overall safety and efficiency in a real-world setting.
MS3D++: Ensemble of Experts for Multi-Source Unsupervised Domain Adaption in 3D Object Detection
Aug 11, 2023



Deploying 3D detectors in unfamiliar domains has been demonstrated to result in a drastic drop of up to 70-90% in detection rate due to variations in lidar, geographical region, or weather conditions from their original training dataset. This domain gap leads to missing detections for densely observed objects, misaligned confidence scores, and increased high-confidence false positives, rendering the detector highly unreliable. To address this, we introduce MS3D++, a self-training framework for multi-source unsupervised domain adaptation in 3D object detection. MS3D++ provides a straightforward approach to domain adaptation by generating high-quality pseudo-labels, enabling the adaptation of 3D detectors to a diverse range of lidar types, regardless of their density. Our approach effectively fuses predictions of an ensemble of multi-frame pre-trained detectors from different source domains to improve domain generalization. We subsequently refine the predictions temporally to ensure temporal consistency in box localization and object classification. Furthermore, we present an in-depth study into the performance and idiosyncrasies of various 3D detector components in a cross-domain context, providing valuable insights for improved cross-domain detector ensembling. Experimental results on Waymo, nuScenes and Lyft demonstrate that detectors trained with MS3D++ pseudo-labels achieve state-of-the-art performance, comparable to training with human-annotated labels in Bird's Eye View (BEV) evaluation for both low and high density lidar.
LightFormer: An End-to-End Model for Intersection Right-of-Way Recognition Using Traffic Light Signals and an Attention Mechanism
Jul 14, 2023For smart vehicles driving through signalised intersections, it is crucial to determine whether the vehicle has right of way given the state of the traffic lights. To address this issue, camera based sensors can be used to determine whether the vehicle has permission to proceed straight, turn left or turn right. This paper proposes a novel end to end intersection right of way recognition model called LightFormer to generate right of way status for available driving directions in complex urban intersections. The model includes a spatial temporal inner structure with an attention mechanism, which incorporates features from past image to contribute to the classification of the current frame right of way status. In addition, a modified, multi weight arcface loss is introduced to enhance the model classification performance. Finally, the proposed LightFormer is trained and tested on two public traffic light datasets with manually augmented labels to demonstrate its effectiveness.
Practical Collaborative Perception: A Framework for Asynchronous and Multi-Agent 3D Object Detection
Jul 09, 2023



Occlusion is a major challenge for LiDAR-based object detection methods. This challenge becomes safety-critical in urban traffic where the ego vehicle must have reliable object detection to avoid collision while its field of view is severely reduced due to the obstruction posed by a large number of road users. Collaborative perception via Vehicle-to-Everything (V2X) communication, which leverages the diverse perspective thanks to the presence at multiple locations of connected agents to form a complete scene representation, is an appealing solution. State-of-the-art V2X methods resolve the performance-bandwidth tradeoff using a mid-collaboration approach where the Bird-Eye View images of point clouds are exchanged so that the bandwidth consumption is lower than communicating point clouds as in early collaboration, and the detection performance is higher than late collaboration, which fuses agents' output, thanks to a deeper interaction among connected agents. While achieving strong performance, the real-world deployment of most mid-collaboration approaches is hindered by their overly complicated architectures, involving learnable collaboration graphs and autoencoder-based compressor/ decompressor, and unrealistic assumptions about inter-agent synchronization. In this work, we devise a simple yet effective collaboration method that achieves a better bandwidth-performance tradeoff than prior state-of-the-art methods while minimizing changes made to the single-vehicle detection models and relaxing unrealistic assumptions on inter-agent synchronization. Experiments on the V2X-Sim dataset show that our collaboration method achieves 98\% of the performance of an early-collaboration method, while only consuming the equivalent bandwidth of a late-collaboration method.
MS3D: Leveraging Multiple Detectors for Unsupervised Domain Adaptation in 3D Object Detection
Apr 10, 2023



We introduce Multi-Source 3D (MS3D), a new self-training pipeline for unsupervised domain adaptation in 3D object detection. Despite the remarkable accuracy of 3D detectors, they often overfit to specific domain biases, leading to suboptimal performance in various sensor setups and environments. Existing methods typically focus on adapting a single detector to the target domain, overlooking the fact that different detectors possess distinct expertise on different unseen domains. MS3D leverages this by combining different pre-trained detectors from multiple source domains and incorporating temporal information to produce high-quality pseudo-labels for fine-tuning. Our proposed Kernel-Density Estimation (KDE) Box Fusion method fuses box proposals from multiple domains to obtain pseudo-labels that surpass the performance of the best source domain detectors. MS3D exhibits greater robustness to domain shifts and produces accurate pseudo-labels over greater distances, making it well-suited for high-to-low beam domain adaptation and vice versa. Our method achieved state-of-the-art performance on all evaluated datasets, and we demonstrate that the choice of pre-trained source detectors has minimal impact on the self-training result, making MS3D suitable for real-world applications.
Viewer-Centred Surface Completion for Unsupervised Domain Adaptation in 3D Object Detection
Sep 14, 2022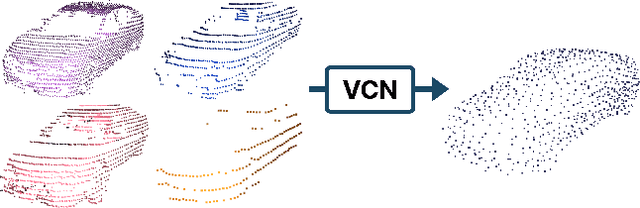
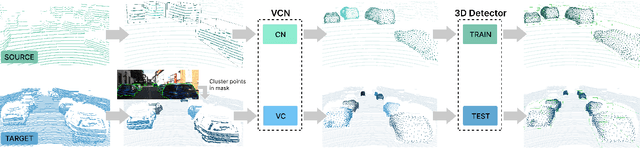
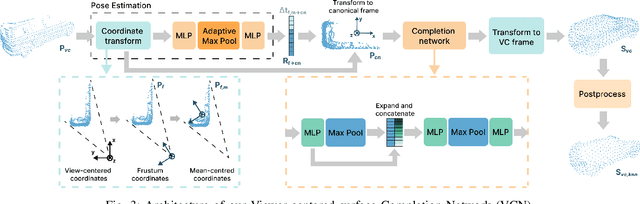

Every autonomous driving dataset has a different configuration of sensors, originating from distinct geographic regions and covering various scenarios. As a result, 3D detectors tend to overfit the datasets they are trained on. This causes a drastic decrease in accuracy when the detectors are trained on one dataset and tested on another. We observe that lidar scan pattern differences form a large component of this reduction in performance. We address this in our approach, SEE-VCN, by designing a novel viewer-centred surface completion network (VCN) to complete the surfaces of objects of interest within an unsupervised domain adaptation framework, SEE. With SEE-VCN, we obtain a unified representation of objects across datasets, allowing the network to focus on learning geometry, rather than overfitting on scan patterns. By adopting a domain-invariant representation, SEE-VCN can be classed as a multi-target domain adaptation approach where no annotations or re-training is required to obtain 3D detections for new scan patterns. Through extensive experiments, we show that our approach outperforms previous domain adaptation methods in multiple domain adaptation settings. Our code and data are available at https://github.com/darrenjkt/SEE-VCN.